Извлечение, преобразование и загрузка (ETL)
Распространенной проблемой, с которой сталкиваются организации, является сбор данных из нескольких источников в нескольких форматах. Затем эти данные необходимо переместить его в одно или несколько хранилищ данных. Тип назначения может не совпадать с типом источника. Часто его формат отличается, либо необходимо сформировать или очистить данные перед их загрузкой в целевое расположение.
За несколько лет для решения этих проблем было разработано много средств, служб и процессов. Независимо от используемого процесса, существует общая потребность в координации работы и преобразовании данных в конвейере. В следующих разделах описываются распространенные методы, используемые для выполнения этих задач.
Извлечение, преобразование и загрузка (ETL)
Извлечение, преобразование и загрузка (ETL) — это конвейер данных, используемый для сбора данных из различных источников. Затем он преобразует данные в соответствии с бизнес-правилами и загружает их в целевое хранилище данных. Процесс преобразования в конвейере ETL выполняется в специальной подсистеме. Зачастую для временного хранения данных во время их преобразования и до загрузки в пункт назначения используются промежуточные таблицы.
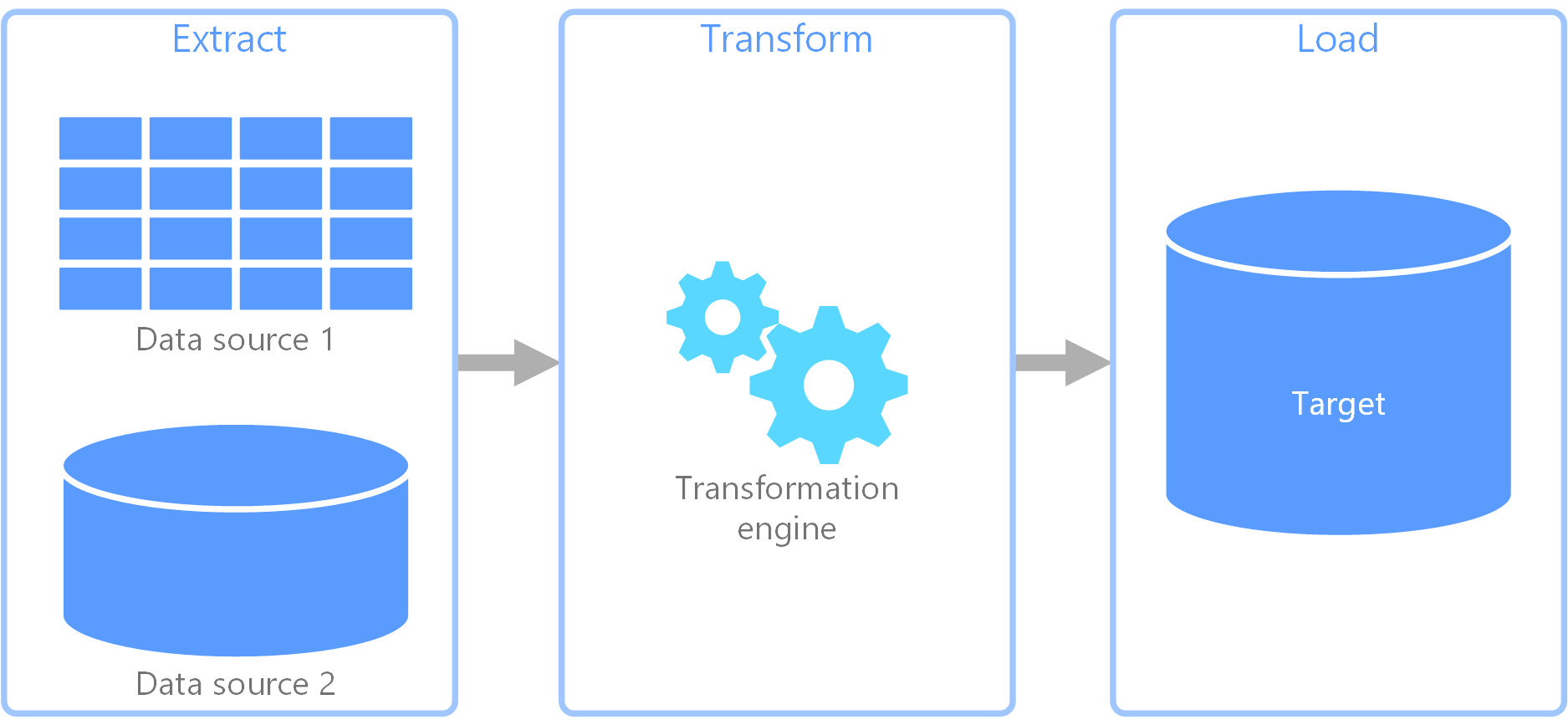
Обычно в процессе преобразования данных применяются различные операции (например, фильтрация, сортировка, агрегирование, объединение, очистка, дедупликация и проверка данных).
Часто три этапа ETL выполняются параллельно, чтобы сэкономить время. Например, при извлечении данных процесс преобразования может уже обрабатывать полученные данные и подготавливать их для загрузки, а процесс загрузки может начать обрабатывать подготовленные данные, не дожидаясь полного завершения извлечения.
Соответствующие службы Azure:
Извлечение, загрузка и преобразование (ELT)
Конвейер извлечения, загрузки и преобразования (ELT) отличается от ETL исключительно средой выполнения преобразования. В конвейере ELT преобразование происходит в целевом хранилище данных. В этом случае для преобразования данных вместо специальной подсистемы используются средства обработки целевого хранилища данных. Это упрощает архитектуру за счет удаления механизма преобразования из конвейера. Еще одним преимуществом этого подхода является то, что масштабирование целевого хранилища данных также улучшает производительность конвейера ELT. Тем не менее ELT работает надлежащим образом, только если целевая система имеет достаточную производительность для эффективного преобразования данных.
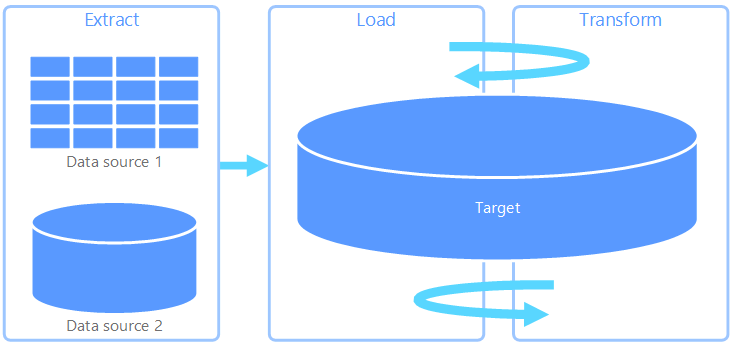
Обычно конвейер ELT применяется для обработки больших объемов данных. К примеру, вы можете извлечь все исходные данные в неструктурированные файлы в масштабируемое хранилище (например, распределенную файловую систему Hadoop, Хранилище BLOB-объектов Azure или Azure Data Lake Store 2-го поколения либо их сочетание). Затем для выполнения запроса исходных данных можно использовать такие технологии, как Spark, Hive или PolyBase. Ключевой особенностью ELT является то, что хранилище данных, используемое для выполнения преобразования, — это то же хранилище, в котором данные в конечном счете потребляются. Это хранилище данных считывает данные непосредственно из масштабируемого хранилища, вместо того чтобы загружать их в собственное защищаемое хранилище. Этот подход пропускает этап копирования (присутствующий в ETL), который часто может занимать много времени при обработке больших наборов данных.
Обычно целевым хранилищем является хранилище данных, использующее кластер Hadoop (с помощью Hive или Spark) или выделенные пулы SQL в Azure Synapse Analytics. Чаще всего схема накладывается на данные неструктурированных файлов во время выполнения запроса и сохраняется в виде таблиц, позволяя запрашивать данные таким же образом, как и любую другую таблицу в хранилище данных. Они называются внешними таблицами, так как данные находятся не в хранилище, управляемом самим хранилищем данных, а во внешнем масштабируемом хранилище, таком как Azure Data Lake Store или хранилище BLOB-объектов Azure.
Хранилище данных управляет только схемой данных и применяет ее при чтении. Например, кластер Hadoop, использующий Hive, описывает таблицу Hive, где источником данных является фактический путь к набору файлов в HDFS. В Azure Synapse технология PolyBase может достичь того же результата, создав таблицу с данными, хранящимися вне самой базы данных. Когда исходные данные загружены, данные, имеющиеся во внешних таблицах, можно обрабатывать, используя возможности хранилища данных. В сценариях с большими данными это означает, что хранилище данных должно поддерживать массовую параллельную обработку (MPP), когда данные разбиваются на более мелкие фрагменты, а обработка этих фрагментов распределяется сразу между несколькими узлами в параллельном режиме.
Последний этап конвейера ELT обычно заключается в преобразовании исходных данных в окончательный формат, более эффективный для тех типов запросов, которые необходимо поддерживать. Например, данные могут быть секционированы. Кроме того, ELT может использовать оптимизированные форматы хранения (например, Parquet), в которых построчные данные хранятся в виде столбцов и предоставляется оптимизированная индексация.
Соответствующие службы Azure:
- Выделенные пулы SQL в Azure Synapse Analytics
- Бессерверные пулы SQL в Azure Synapse Analytics
- HDInsight с Hive;
- Фабрика данных Azure
- Диаграммы данных в Power BI
Поток данных и поток управления
В контексте конвейеров данных поток управления обеспечивает обработку набора задач в правильном порядке. Для этого используется управление очередностью. Эти ограничения можно рассматривать как соединители на схеме рабочего процесса, показанной ниже. Каждая задача имеет результат (успешное завершение, сбой или завершение). Все последующие задачи начинают обработку данных, только когда предыдущая задача завершена с одним из этих результатов.
Потоки управления выполняют потоки данных в качестве задачи. В рамках задачи потока данных данные извлекаются из источника, преобразовываются и загружаются в хранилище данных. Выходные данные одной задачи потока данных могут использоваться в качестве входных данных для следующей задачи потока данных, а эти потоки могут выполняться одновременно. В отличие от потоков управления, вы не можете добавить ограничения между задачами в потоке данных. Однако вы можете добавить средство просмотра данных для наблюдения за данными по мере их обрабатывания каждой задачей.
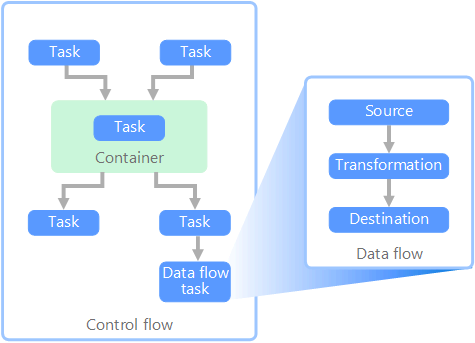
На приведенной выше схеме показано несколько задач в потоке управления, одна из которых является задачей потока данных. Одна из задач вложена в контейнер. Контейнеры можно использовать для обеспечения структуры задач, тем самым формируя единицу работы. Одним из примеров является повторение элементов в коллекции (например, файлы в папке или инструкции базы данных).
Соответствующие службы Azure:
Выбор технологий
- Хранилища данных оперативной обработки транзакций (OLTP)
- Хранилища данных OLAP
- Хранилища данных
- Оркестрация конвейеров
Соавторы
Эта статья поддерживается корпорацией Майкрософт. Первоначально он был написан следующими участник.
- Раунак Джавар | Старший архитектор облака
- Зойнер Теджада | Генеральный директор и архитектор
Следующие шаги
- Интеграция данных с Фабрика данных Azure или Azure Synapse Pipeline
- Общие сведения об Azure Synapse Analytics
- Оркестрация перемещения и преобразования данных в Фабрика данных Azure или Azure Synapse Pipeline
Связанные ресурсы
На следующей схеме эталонной архитектуры представлены сквозные конвейеры ELT в Azure:
- Корпоративная бизнес-аналитика в Azure с использованием Azure Synapse
- Автоматизированная корпоративная бизнес-аналитика с использованием Azure Synapse и Фабрики данных Azure
Обратная связь
Отправить и просмотреть отзыв по
Основные функции ETL-систем
ETL – аббревиатура от Extract, Transform, Load. Это системы корпоративного класса, которые применяются, чтобы привести к одним справочникам и загрузить в DWH и EPM данные из нескольких разных учетных систем.
Вероятно, большинству интересующихся хорошо знакомы принципы работы ETL, но как таковой статьи, описывающей концепцию ETL без привязки к конкретному продукту, на я Хабре не нашел. Это и послужило поводом написать отдельный текст.
Хочу оговориться, что описание архитектуры отражает мой личный опыт работы с ETL-инструментами и мое личное понимание «нормального» применения ETL – промежуточным слоем между OLTP системами и OLAP системой или корпоративным хранилищем.
Хотя в принципе существуют ETL, который можно поставить между любыми системами, лучше интеграцию между учетными системами решать связкой MDM и ESB. Если же вам для интеграции двух зависимых учетных систем необходим функционал ETL, то это ошибка проектирования, которую надо исправлять доработкой этих систем.
Зачем нужна ETL система
Проблема, из-за которой в принципе родилась необходимость использовать решения ETL, заключается в потребностях бизнеса в получении достоверной отчетности из того бардака, который творится в данных любой ERP-системы.
- Как случайные ошибки, возникшие на уровне ввода, переноса данных, или из-за багов;
- Как различия в справочниках и детализации данных между смежными ИТ-системами.
- Привести все данные к единой системе значений и детализации, попутно обеспечив их качество и надежность;
- Обеспечить аудиторский след при преобразовании (Transform) данных, чтобы после преобразования можно было понять, из каких именно исходных данных и сумм собралась каждая строчка преобразованных данных.
Как работает ETL система
Все основные функции ETL системы умещаются в следующий процесс:
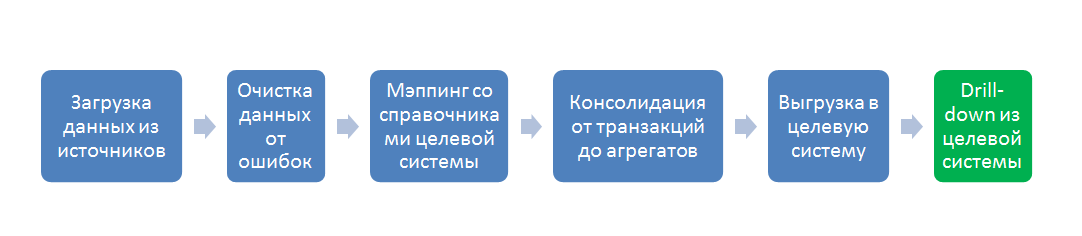
В разрезе потока данных это несколько систем-источников (обычно OLTP) и система приемник (обычно OLAP), а так же пять стадий преобразования между ними:
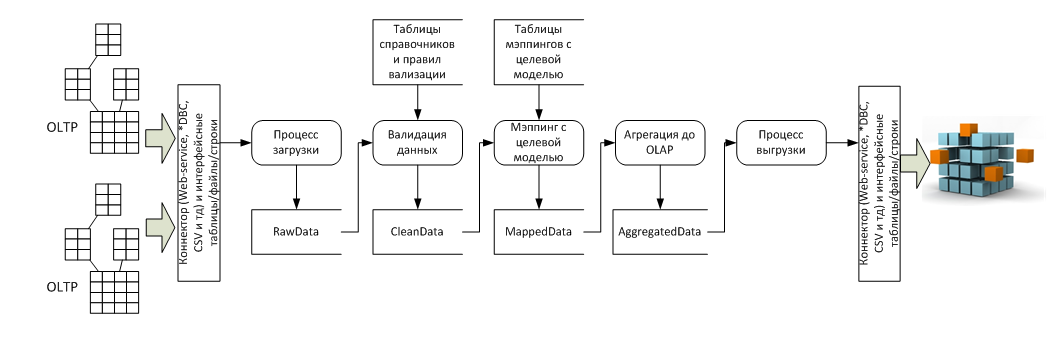
- Процесс загрузки – Его задача затянуть в ETL данные произвольного качества для дальнейшей обработки, на этом этапе важно сверить суммы пришедших строк, если в исходной системе больше строк, чем в RawData то значит — загрузка прошла с ошибкой;
- Процесс валидации данных – на этом этапе данные последовательно проверяются на корректность и полноту, составляется отчет об ошибках для исправления;
- Процесс мэппинга данных с целевой моделью – на этом этапе к валидированной таблице пристраивается еще n-столбцов по количеству справочников целевой модели данных, а потом по таблицам мэппингов в каждой пристроенной ячейке, в каждой строке проставляются значения целевых справочников. Значения могут проставляться как 1:1, так и *:1, так и 1:* и *:*, для настройки последних двух вариантов используют формулы и скрипты мэппинга, реализованные в ETL-инструменте;
- Процесс агрегации данных – этот процесс нужен из-за разности детализации данных в OLTP и OLAP системах. OLAP-системы — это, по сути, полностью денормализованная таблица фактов и окружающие ее таблицы справочников (звездочка/снежинка), максимальная детализация сумм OLAP – это количество перестановок всех элементов всех справочников. А OLTP система может содержать несколько сумм для одного и того же набора элементов справочников. Можно было-бы убивать OLTP-детализацию еще на входе в ETL, но тогда мы потеряли бы «аудиторский след». Этот след нужен для построения Drill-down отчета, который показывает — из каких строк OLTP, сформировалась сумма в ячейке OLAP-системы. Поэтому сначала делается мэппинг на детализации OLTP, а потом в отдельной таблице данные «схлопывают» для загрузки в OLAP;
- Выгрузка в целевую систему — это технический процесс использования коннектора и передачи данных в целевую систему.
Особенности архитектуры
Реализация процессов 4 и 5 с точки зрения архитектуры тривиальна, все сложности имеют технический характер, а вот реализация процессов 1, 2 и 3 требует дополнительного пояснения.
Процесс загрузки
При проектировании процесса загрузки данных необходимо помнить о том что:
- Надо учитывать требования бизнеса по длительности всего процесса. Например: Если данные должны быть загружены в течение недели с момента готовности в исходных системах, и происходит 40 итераций загрузки до получения нормального качества, то длительность загрузки пакета не может быть больше 1-го часа. (При этом если в среднем происходит не более 40 загрузок, то процесс загрузки не может быть больше 30 минут, потому что в половине случаев будет больше 40 итераций, ну или точнее надо считать вероятности:) ) Главное если вы не укладываетесь в свой расчет, то не надейтесь на чудо — сносите и все, делать заново т.к. вы не впишитесь;
- Данные могут загружаться набегающей волной – с последовательным обновлением данных одного и того-же периода в будущем в течение нескольких последовательных периодов. (например: обновление прогноза окончания года каждый месяц). Поэтому кроме справочника «Период», должен быть предусмотрен технический справочник «Период загрузки», который позволит изолировать процессы загрузки данных в разных периодах и не потерять историю изменения цифр;
- Данные имеют обыкновение быть перегружаемыми много раз, и хорошо если будет технический справочник «Версия» как минимум с двумя элементами «Рабочая» и «Финальная», для отделения вычищенных данных. Кроме-того создание персональных версий, одной суммарной и одной финальной позволяет хорошо контролировать загрузку в несколько потоков;
- Данные всегда содержат ошибки: Перезагружать весь пакет в [50GB -> +8] это очень не экономно по ресурсам и вы, скорее всего, не впишитесь в регламент, следовательно, надо грамотно делить загружаемый пакет файлов и так проектировать систему, чтобы она позволяла обновлять пакет по маленьким частям. По моему опыту лучший способ – техническая аналитика «файл-источник», и интерфейс, который позволяет снести все данные только из одного файла, и вставить вместо него обновленные. А сам пакет разумно делить на файлы по количеству исполнителей, ответственных за их заполнение (либо админы систем готовящие выгрузки, либо пользователи заполняющие вручную);
- При проектировании разделения пакета на части надо еще учитывать возможность так-называемого «обогащения» данных (например: Когда 12 января считают налоги прошлого года по правилам управленческого учета, а в марте-апреле перегружают суммы на посчитанные по бухгалтерскому), это решается с одной стороны правильным проектированием деления пакета данных на части так, чтобы для обогащения надо было перегрузить целое количество файлов (не 2,345 файла), а с другой стороны введением еще одного технического справочника с периодами обогащения, чтобы не потерять историю изменений по этим причинам).
Процесс валидации
Данный процесс отвечает за выявление ошибок и пробелов в данных, переданных в ETL.
Само программирование или настройка формул проверки не вызывает вопросов, главный вопрос – как вычислить возможные виды ошибок в данных, и по каким признакам их идентифицировать?
Возможные виды ошибок в данных зависят от того какого рода шкалы применимы для этих данных. (Ссылка на прекрасный пост, объясняющий, какие существуют виды шкал — http://habrahabr.ru/post/246983/).
Ближе к практике в каждом из передаваемых типов данных в 95% случаев возможны следующие ошибки:
- Не из списка разрешенных значений
- Отсутствие обязательных значений
- Не соответствие формату (Все договора должны нумероваться «ДГВxxxx..»)
- Не из списка разрешенных значений для связанного элемента
- Отсутствие обязательных элементов для связанного элемента
- Не соответствие формату для связанного элемента(например: для продукта «АИС» все договора должны нумероваться «АИСxxxx..»)
- Символы допустимые в одном формате, недопустимы в другом
- Кодировка
- Обратная совместимость (Элемент справочника был изменен в целевой системе без добавления мэппинга)
- Новые значения (нет мэппинга)
- Устаревшие значения (не из списка разрешенных в целевой системе)
- Не число
- Не в границах разрешенного интервала значений
- Пропущено порядковое значение (например: данные не дошли)
- Не выполняется отношение y=ax+b (например: НДС и Выручка, или Встречные суммы равны)
- Элементу «А» присвоен неправильный порядковый номер
- Разницы за счет разных правил округления значений (например: в 1С и SAP никогда не сходится рассчитанный НДС)
- Переполнение
- Потеря точности и знаков
- Несовместимость форматов при конвертации в не число
- День недели не соответствует дате
- Сумма единиц времени не соответствует из-за разницы рабочие/не рабочие/праздничные/сокращенные дни
- Несовместимость формата даты при передаче текстом (например: ISO 8601 в UnixTime, или разные форматы в ISO 8601)
- Ошибка точки отсчета и точности при передаче числом (например: TimeStamp в DateTime)
Соответственно проверки на ошибки реализуются либо формулами, либо скриптами в редакторе конкретного ETL-инструмента.
А если вообще по большому счету, то большая часть ваших валидаций будет на соответствие справочников, а это [select * from a where a.field not in (select…) ]
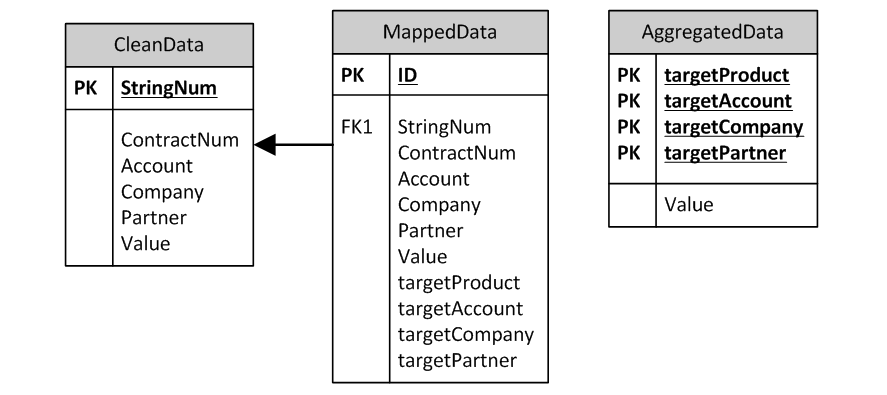
При этом для сохранения аудиторского следа разумно сохранять в системе две отдельные таблицы – rawdata и cleandata с поддержкой связи 1:1 между строками.
Процесс мэппинга
Процесс мэппинга так же реализуется с помощью соответствующих формул и скриптов, есть три хороших правила при его проектировании:
-
Таблица замэпленных данных должна включать одновременно два набора полей – старых и новых аналитик, чтобы можно был сделать select по исходным аналитикам и посмотреть, какие целевые аналитики им присвоены, и наоборот:
Заключение
В принципе это все архитектурные приемы, которые мне понравились в тех ETL инструментах, которыми я пользовался.
Кроме этого конечно в реальных системах есть еще сервисные процессы — авторизации, разграничения доступа к данным, автоматизированного согласования изменений, и все решения конечно являются компромиссом с требованиями производительности и предельным объемом данных.
Надеюсь, эта информация будет вам полезна.
- Веб-разработка
- Анализ и проектирование систем
ETL: что такое, зачем и для кого

В статье рассмотрено одно из ключевых BI-понятий (Business Intelligence) – ETL-технологии: определение, история возникновения, основные принципы работы, примеры реализации и типовые варианты использования (use cases). Также отмечены некоторые проблемы применения ETL и способы их решения с помощью программных инструментов обработки больших данных (Big Data).
Что такое ETL и зачем это нужно
Начнем с определения: ETL (Extract, Transform, Load) – это совокупность процессов управления хранилищами данных, включая [1]:
- извлечение данных из внешних источников (таблицы баз данных, файлы);
- преобразование и очистка данных согласно бизнес-потребностям;
- загрузка обработанной информации в корпоративное хранилище данных (КХД).
Понятие ETL возникло в результате появления множества корпоративных информационных систем, которые необходимо интегрировать друг с другом с целью унификации и анализа хранимых в них данных. Реляционная модель представления данных, подходящая для потребностей транзакционных систем, оказалась неэффективной для комплексной обработки и анализа информации. Поиск унифицированного решения привел к развитию хранилищ и витрин данных – самостоятельных систем хранения консолидированной информации в виде измерений и показателей, что считается оптимальным для формирования аналитических запросов [2].
Прикладное назначение ETL состоит в том, чтобы организовать такую структуру данных с помощью интеграции различных информационных систем. Учитывая, что BI-технологии позиционируются как «концепции и методы для улучшения принятия бизнес-решений с использованием систем на основе бизнес-данных» [3], можно сделать вывод о прямой принадлежность ETL к этому технологическому стеку.
Как устроена ETL-система: архитектура и принцип работы
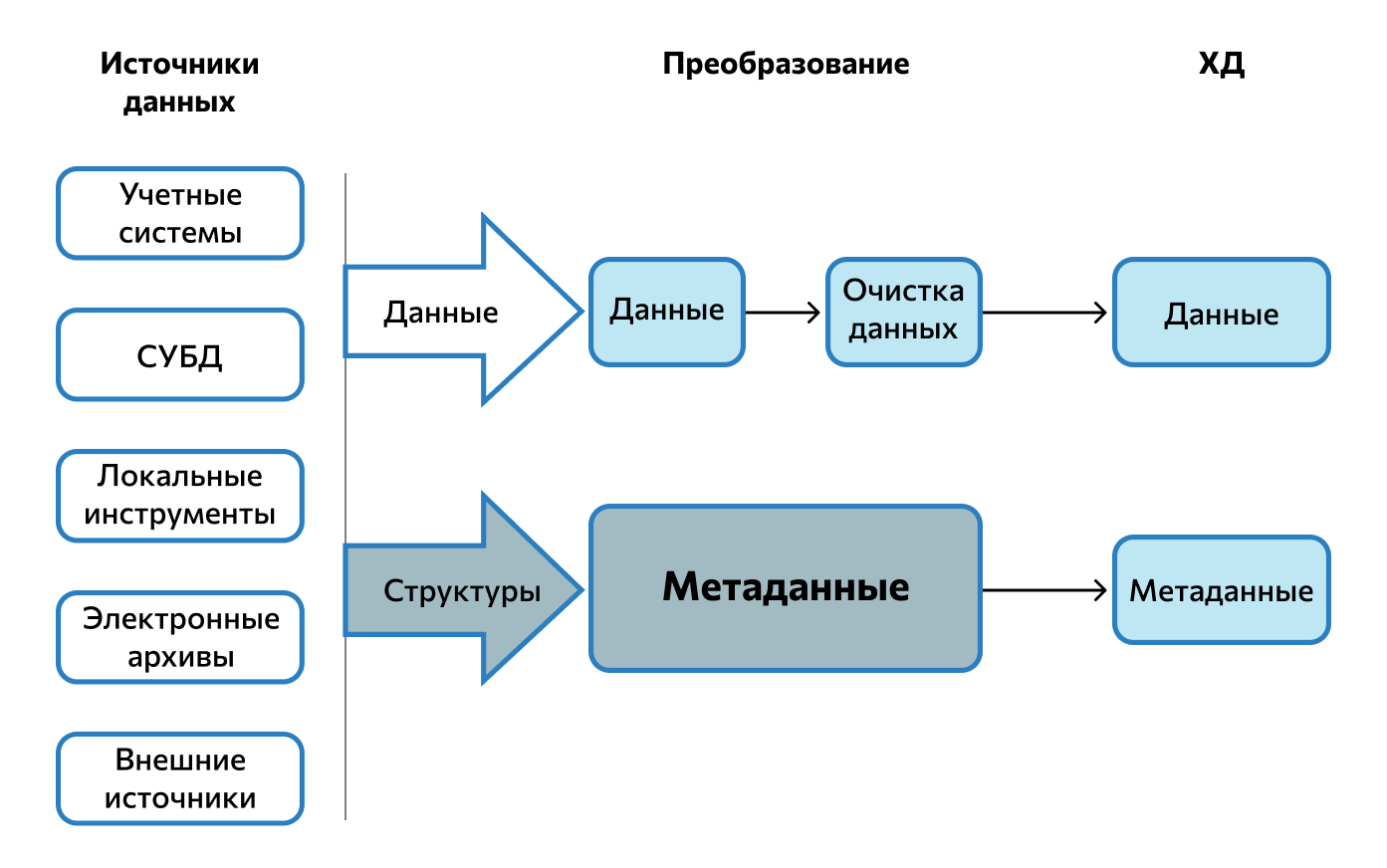
Независимо от особенностей построения и функционирования ETL-система должна обеспечивать выполнение трех основных этапов процесса ETL-процесса (рис.1) [4]:
- извлечение данных из одного или нескольких источников и подготовка их к преобразованию (загрузка в промежуточную область, проверка данных на соответствие спецификациям и возможность последующей загрузки в ХД);
- трансформация данных – преобразование форматов и кодировки, агрегация и очистка;
- загрузка данных— запись преобразованных данных, включая информацию о структуре их представления (метаданные) в необходимую систему хранения (КХД) или витрину данных.

Таким образом, ETL-процесс представляет собой перемещение информации (потока данных) от источника к получателю через промежуточную область, содержащую вспомогательные таблицы, которые создаются временно и исключительно для организации процесса выгрузки (рис. 2) [1]. Требования к организации потока данных описывает аналитик. Поэтому ETL – это не только процесс переноса данных из одного приложения в другое, но и инструмент подготовки данных к анализу.

На практике ETL выступает в качестве промежуточного слоя между OLTP — и OLAP -системами. OLTP (Online Transaction Processing) – это транзакционные системы для обработки непрерывного потока небольших по размеру транзакций в режиме реального времени: ERP-, MES-, банковские и биржевые приложения. Они автоматизируют структурированные, повторяющиеся задачи обработки данных, например, ввод заказов и банковские транзакции, в большом количестве за короткие промежутки времени. Однако сложные аналитические запросы, например, сколько товаров категории «предметы народного промысла» было куплено молодыми людьми 18-30 лет в городах-миллионниках за последние 3 года, в таких системах выполняются очень долго [5].
Для подобных запросов предназначены OLAP-системы. OLAP (Online Analytical Processing) – это интерактивная аналитическая обработка, подготовка суммарной (агрегированной) информации на основе больших массивов данных, структурированных по многомерному принципу. При этом строится сложная структура данных – OLAP-куб, включающий таблицу фактов, по которым делаются ключевые запросы и таблицы агрегатов (измерений), показывающие, как могут анализироваться агрегированные данные. Например, группировка продуктов по городам, производителям, потребителям и другие сложные запросы, которые могут понадобиться аналитику. Куб потенциально содержит всю информацию, нужную для ответов на любые количественные и пространственно-временные вопросы. При огромном количестве агрегатов зачастую полный расчёт происходит только для некоторых измерений, для остальных же производится «по требованию» [6].
Таким образом, основные функции ETL-системы можно представить в виде последовательности операций по передаче данных из OLTP в OLAP (рис. 3) [7]:
- загрузка в ETL «сырых» данных (Raw Data) произвольного качества для дальнейшей обработки. При этом выполняется сверка суммы пришедших строк: если в системе-источнике больше строк, чем в Raw Data, то загрузка прошла с ошибкой.
- валидация данных, когда данные последовательно проверяются на корректность и полноту, составляется отчет об ошибках для исправления;
- настройка соответствия (мэппинг)данных с целевой моделью, когда к валидированной таблице пристраиваются столбцы по количеству справочников целевой модели, а потом в каждой пристроенной ячейке каждой строки проставляются соответствие значений целевых справочников (1:1, *:1, 1:* или *:*);
- агрегация данных, необходимая из-за разности детализации данных в OLTP и OLAP-системах. OLAP представляет собой полностью денормализованную таблицу фактов и окружающие ее таблицы справочников по схеме звездочка или снежинка. При этом максимальная детализация сумм OLAP равна количеству перестановок (агрегаций) всех элементов всех справочников. OLTP-система может содержать несколько сумм для одного и того же набора элементов справочников. Чтобы проследить, из каких строк OLTP сформировалась сумма в ячейке OLAP-системы, необходим мэппинг OLTP-детализации, а потом «склейка» данных в отдельной таблице для загрузки в OLAP.
- выгрузка в целевую системус использованием коннектора и интерфейсных инструментов.

Немного про хранилища и витрины данных
ETL часто рассматривают как средство переноса данных из различных источников в централизованное КХД. Однако КХД не связано с решением какой-то конкретной аналитической задачи, его цель — обеспечивать надежный и быстрый доступ к данным, поддерживая их хронологию, целостность и непротиворечивость. Чтобы понять, каким образом КХД связаны с аналитическими задачами и ETL, для начала обратимся к определению.
Корпоративное хранилище данных (КХД, DWH – Data Warehouse) – это предметно-ориентированная информационная база данных, специально разработанная и предназначенная для подготовки отчётов и бизнес-анализа с целью поддержки принятия решений в организации. Информация в КХД, как правило, доступна только для чтения. Данные из OLTP-системы копируются в КХД таким образом, чтобы при построении отчётов и OLAP-анализе не использовались ресурсы транзакционной системы и не нарушалась её стабильность. Есть два варианта обновления данных в хранилище [8]:
- полное обновление данных в хранилище, когда старые данные удаляются, потом происходит загрузка новых данных. Процесс происходит с определённой периодичностью, при этом актуальность данных может несколько отставать от OLTP-системы;
- инкрементальное обновление, когда обновляются только те данные, которые изменились в OLTP-системе.
ETL-процесс позволяет реализовать оба этих способа. Отметим основные принципы организации КХД [8]:
- проблемно-предметная ориентация, когда данные объединяются в категории и хранятся в соответствии с областями, которые они описывают, а не с приложениями, которые они используют;
- интегрированность– данные объединены так, чтобы они удовлетворяли всем требованиям предприятия в целом, а не конкретной бизнес-функции;
- некорректируемость– данные в КХД не создаются, а поступают из внешних источников, не корректируются и не удаляются;
- зависимость от времени– данные в хранилище точны и корректны только в том случае, когда они привязаны к некоторому промежутку или моменту времени.
Витрина данных (Data Mart) представляет собой срез КХД в виде массива тематической, узконаправленной информации, ориентированного, например, на пользователей одной рабочей группы или департамента. Витрина данных, аналогично дэшборд-панели, позволяет аналитику увидеть агрегированную информацию в определенном временном или тематическом разрезе, а также сформировать и распечатать отчетные данные в виде шаблонизированного документа [9].
При проектировании хранилищ и витрин данных аналитику следует ориентироваться на возможности их прикладного использования и с учетом этого разрабатывать ETL-процессы. Например, если известно, что информация, поступающая из определенных подразделений, является самой важной и полезной, а также наиболее часто анализируется, то в регламент переноса данных в хранилище стоит внести соответствующие приоритеты. Это позволит ускорить работу с информацией, что особенно важно для data-driven организаций со сложной многоуровневой филиальной структурой и большим количеством подразделений [4].
Прикладные кейсы использования ETL-технологий
Рассмотрим пару типовых примеров использования ETL-систем [10].
Кейс 1. Прием нового сотрудника на работу, когда требуется завести учетную карточку во множестве корпоративных систем. В реальности в средних и крупных организациях этим занимаются специалисты разных подразделений, не скоординировав задачу между собой. Поэтому на практике часто возникают ситуации, когда принятый на работу сотрудник подолгу не может получить банковскую карту, потому что его учетная запись не была вовремя заведёна в бухгалтерии, а уже уволенные сотрудники имеют доступ к корпоративной почте и приложениям, т.к. их аккаунты не заблокированы в домене. ETL поможет быстро наладить взаимодействие между всеми корпоративными информационными системами.
Аналогичным образом ETL-технологии помогут автоматизировать удаление аккаунтов сотрудника из всех корпоративных систем в случае увольнения. В частности, как только в HR-систему попадут данные о дате окончания карьеры сотрудника на этом месте работы, информация о необходимости блокировки его записи поступит контроллеру домена, его корпоративная почта автоматически архивируется, а почтовый ящик блокируется. Также возможен полуавтоматический режим с созданием заявки на блокировку в службу технической поддержки, например, Help Desk.
Кейс 2. Разноска платежей, когда при взаимодействии со множеством контрагентов необходимо сопоставить информацию в виде платёжных документов, с деньгами, поступившими на расчетный счёт. В реальности это два независимых потока данных, которые сотрудники бухгалтерии или операционисты связывают вручную. Далеко не все корпоративные финансовые системы имеют функцию автоматической привязки платежей.
Итак, информация о платежах поступает от платежной сети в зашифрованном виде, т.к. содержит персональные данные. Вторым потоком данных являются файлы в формате DBF, содержащие информацию о банках-контрагентах, которая требуется для геолокации платежа. Наконец, с минимальной задержкой в три банковских дня, приходят деньги и выписка с платежами, проведёнными через банк-партнёр. Отметим, что в реальности прямой связи между всеми этими данными нет: номера документов, указанные в реестрах от платёжной системы и банка, не совпадают, а из-за особенностей работы банка дата платежа, которая значится в выписке, может не соответствовать дате реальной оплаты, которая содержится в зашифрованном файле реестра.
Расшифровку данных можно включить в ETL-процесс, в результате чего получится текстовый файл сложной структуры, содержащий ФИО, телефон, паспортные данные плательщика, сумму и дату платежа, а также дополнительные технические данных, идентифицирующие транзакцию. Это как раз позволит связать платёж с данными из банковской выписки. Данные из реестра обогащаются информацией о банках-контрагентах (филиалах, подразделениях, городах и адресах отделений), после этого осуществляются их соответствие (мэппинг) к конкретным полям таблиц корпоративных информационных систем и загрузка в КХД. Обогащение уже очищенных данных происходит в рамках реляционной модели с использованием внешних ключей.
После прихода банковской выписки запускается ещё один ETL-процесс, задача которого состоит в сопоставлении ранее полученной информации о платежах с реально пришедшими деньгами. Поскольку выписки приходят из банка в текстовом формате, первым шагом трансформации является разбор файла, затем идет процесс автоматической привязки платежей с использованием информации, ранее загруженной в корпоративную систему из реестров платежей и банков. В процессе привязки происходит сравнение не только ключей, идентифицирующих транзакцию, но и суммы и ФИО плательщика, а также отделения банка. Также решается задача исправления неверной даты платежа, указанной в банковской выписке, на реальную дату его совершения.
В результате нескольких ETL-процессов получилась система автоматической привязки платежей, при этом основные затраты были связаны с не с разработкой программного обеспечения, а с проектированием и изучением форматов файлов. В редких случаях ручной привязки обогащение данных с помощью ETL-технологии существенно облегчает эту процедуру. В частности, наличие телефонного номера плательщика позволяет уточнить данные о платеже лично у него, а геолокация платежа даёт информацию для аналитических отчётов и позволяет более эффективно отслеживать переводы от партнёров-брокеров (рис. 4).

Современный рынок ETL-систем и особенности выбора
Существует множество готовых ETL-систем, реализующих функции загрузки данных в КХД. Среди коммерческих решений наиболее популярными считаются следующие [11]:
- IBM WebSphere DataStage;
- Informatica PowerCenter;
- Oracle Data Integrator;
- SAP Data Services;
- SAS Data Integration Server;
К категории условно бесплатных можно отнести [11]:
- Oracle Warehouse Builder;
- Talend Open Studio;
- Scriptella;
- Pentaho.
При выборе готовой ETL-системы необходимо, в первую очередь, руководствоваться не бюджетом ее покупки или стоимостью использования, а следующими функциональными критериями:
- совместимость с источниками данных – современные КХД могут строиться на основе различных моделей данных (многомерных, реляционных, гибридных), поэтому ETL-систем должна быть универсальной, чтобы извлекать и переносить данные как можно большего числа типов и форматов [4];
- наличие инструментов разработки (API, коннекторов и т.д.) для масштабирования и интеграции со сторонними системами (источниками и потребителями данных), а также для создания оригинальных алгоритмов операций с данными;
- «зрелость» системы, включающая завершенность ее функциональных возможностей, простоту эксплуатации и уровень технической поддержки.
Многие из современных промышленных решений представляют собой технологические платформы, позволяющие масштабировать ETL-процессы с поддержкой параллелизма выполнения операций, перераспределением нагрузки по обработке информации между источниками и самой системой, а также другими функциями в области интеграции данных. Поэтому выбор ETL-средства – это своего рода компромисс между конкретным проектным решением, текущими и будущими перспективами использования ETL-инструментария, а также стоимостью разработки и поддержания в актуальном состоянии всех используемых функций ETL-процесса [2].
Некоторые проблемы ETL-технологий и способы их решения
Как правило, ETL-системы самостоятельно справляются с проблемами подготовки данных к агрегированию и анализу, выполняя операции очистки данных. При этом устраняются проблемы качества данных: проверка на корректность форматов и типов, приведение значений к нужному диапазону, заполнение пропусков, удаление дубликатов, противоречий и нарушений структуры. Однако, кроме очистки данных, можно выделить еще пару трудоемких задач, которые не решаются автоматически:
- выбор источников данных – перед запуском процесса извлечения данных следует определить, где и в каком виде хранится информация, которая должна попасть в КХД. При этом аналитик данных должен учесть следующие факторы:
значимость данных с точки зрения анализа; сложность получения данных из источников; возможное нарушение целостности и достоверности данных; объем данных в источнике.
На практике часто приходится искать компромисс между этими факторами. Например, данные могут представлять несомненную ценность для анализа, но сложность их извлечения или очистки может свести на нет все преимущества от использования [4].
- разрозненность конечных данных– после того, как Data Analyst определил, какая информация и из каких источников должна попадать в КХД, эти источники становятся основными репозиториями. Содержимое витрин данных становится доступным для пользователей, однако исходные данные не хранятся и не могут быть извлечены. Но на практике различным категориям пользователей нужно больше информации, чем предоставляют ETL-системы. В этом случае пользователи создают свои собственные, локальные хранилища и витрины данных, которые не интегрированы с общим КХД. В результате при использовании одной и тоже же по смыслу информации у разных бизнес-подразделений возникают разночтения, что приводит к несогласованности в работе [12].
- появление новых источников и форматов представления данных– традиционные ETL-инструментов хорошо подходят для обработки структурированных данных, однако в реальности часто возникает необходимость работы с полуструктурированной или неструктурированной информаций. В этом случае следует подключать технологии больших данных (Big Data), например, Apache Hive и Pig для загрузки и преобразования информации, хранящейся в распределенной файловой системе Hadoop Distributed File System (HDFS). Hive реализует принципы традиционных баз и хранилищ данных на основе SQL-запросов и схем, а Pig похож на стандартный язык ETL-сценариев. Оба инструмента используют функции MapReduce в пакетной обработке данных [12], т.е., как и типовые ETL-системы, ориентированы на регулярную загрузку информации для обеспечения согласованности источников и витрин данных с КХД [2]. А для потоковой обработки множества разноструктурированной информации потребуются распределенные фреймворки, обеспечивающие работу с непрерывно поступающими данными, например, Apache Spark, Flink, Storm, Samza или Kafka Streams [13].
Таким образом, Big Data инструменты пакетной и потоковой обработки позволяют дополнить типовые ETL-системы, предоставляя бизнес-пользователям более широкие возможности по работе с корпоративной информацией. Однако, в этом случае временные, трудовые и финансовые затраты на аналитику данных существенно возрастут, т.к. понадобятся дорогие специалисты: Data Engineer, который выстроит конвейер данных (pipeline), а также Data Scientist, который разработает программное приложение для онлайн-аналитики, включая оригинальные ML-алгоритмы. Впрочем, такие инвестиции будут оправданы, если предприятие достигло хотя бы 3-го уровня управленческой зрелости по модели CMMI, обладает большим количеством разных данных с высоким потенциалом для аналитики и стремится стать настоящей data-driven компанией. Однако, чтобы эти вложения принесли выгоду, а не превратились в пустые траты, стоит адекватно оценить свои потребности и возможности, возможно, с привлечением внешнего консультанта по аналитике данных.
Стоит отметить, что разработчики многих ETL-систем учитывают потребность аналитики больших данных с помощью своих продуктов и потому включают в их возможности работы с Apache Hadoop и Spark, как, например, Pentaho Business Analytics Platform [14]. В этом случае не придется самостоятельно разрабатывать средства интеграции ETL-системы с распределенными решениями сбора и обработки больших данных, а можно воспользоваться готовыми коннекторами и API-интерфейсами. Впрочем, это не отменяет необходимость предварительной аналитической работы по проектированию и реализации ETL-процесса. Организация сбора информации в хранилище данных может достигать до 80% трудозатрат по проекту. Учет различных аспектов ETL-процессов с прицелом на будущее позволит тщательно спланировать необходимые работы, избежать увеличения общего времени реализации и стоимости проекта, а также обеспечить BI-систему надежными и актуальными данными для анализа [2].
Источники
- ETL
- ETL – технология, сопутствующая любой BI-инициативе
- Business Intelligence
- Введение в ETL
- OLTP
- OLAP
- Основные функции ETL-систем
- Хранилище данных
- Витрина данных
- Знакомый-незнакомый ETL
- Реализация подсистемы ETL (Extract, Transform, Load) корпоративного хранилища данных
- Hive как инструмент для ETL или ELT
- Что выбрать для потоковой обработки Big Data: Apache Kafka Streams или Spark Streaming
- Pentaho Data Integration
Etl sql что это
12 сентября 2023
Скопировано
ETL — это общий термин для процессов, которые происходят, когда данные переносят из нескольких систем в одно хранилище. Аббревиатура расшифровывается как Extract, Transform, Load, или «извлечение, преобразование, загрузка». Именно это происходит с файлами в процессе переноса.

Освойте профессию «Аналитик данных»
Обычно ETL-процессы используются, когда нужно перенести много разнородных данных: собрать их, привести к единому виду, загрузить в новую систему и сохранить всю информацию по пути. Системы бывают разными, и задача ETL — в том числе адаптировать под них данные из разных источников.
В качестве примера можно привести магазин. Учет офлайн-клиентов ведется в одном формате, онлайн-покупателей — в другом. Устройства разные, форматы данных тоже. Если магазину потребуется вести общую базу, сначала данные нужно выгрузить и привести к единому формату. За это отвечает ETL.
Существует множество платных и бесплатных реализаций ETL. Они называются ETL-системами. Простейшую реализацию программист может написать самостоятельно, но только для конкретной небольшой задачи. Большие системы работают с разными данными «из коробки».
Профессия / 12 месяцев
Аналитик данных
Находите закономерности и делайте выводы, которые помогут бизнесу

Кто работает с ETL-системами
- Разработчики, так как для некоторых проектов и задач могут потребоваться собственные внутренние реализации ETL. Обычно это нужно в компаниях, которым важно не зависеть от сторонних клиентов, например в банках. ETL-разработчик — это человек, который занимается проектированием и реализацией ETL-процессов.
- Бизнес- и дата-аналитики, которые работают с бизнес-логикой и данными, поэтому часто используют разнородную информацию.
- Дата-инженеры, специалисты, которые занимаются проектированием, поддержкой и оркестрацией систем хранения данных. Оркестрацией называют координирование работы сложных систем.
Где используется ETL
Единственное назначение ETL — помогать перемещению данных из одного места в другое. ETL можно использовать во множестве сфер, где требуется объединить информацию из разных источников.
Базы данных. Любые хранилища данных так или иначе сталкиваются с миграциями, перемещениями из одного места в другое. Иногда это разовый перенос, но часто компании работают так, что данные поступают в базу из разных источников все время. Пример с магазином хорошо иллюстрирует такое поведение. При работе с базами данных ETL будет отвечать за то, чтобы все было однородно и грамотно.
DWH, или КХД. Аббревиатуру можно расшифровать как Data Warehouse или «корпоративное хранилище данных», склад информации. Так называются специальные базы данных для организационных целей, внутреннего анализа и подготовки отчетов. Это административные и архивные базы данных компании. В них хранится важная бизнес-информация. Чтобы бизнес-процессы и внутренняя аналитика работали корректно, нужно объединить информацию в одном месте. В случае с КХД она всегда поступает из разных источников. Поэтому ETL часто используют в связке со «складами данных» и настройкой бизнес-процессов.

Станьте аналитиком данных и получите востребованную специальность
OLTP и OLAP. ETL используют как «прослойку» между системами OLTP и OLAP. Оба вида систем нужны для обработки данных, но у них есть различия:
- OLTP — это Online Transaction Processing, обработка онлайн-транзакций. Системы ориентированы на непрерывный поток небольших транзакций, многие из которых повторяются;
- OLAP — это Online Analytical Processing, аналитическая онлайн-обработка данных. В отличие от предыдущего вида систем, OLAP нужна для обработки крупных аналитических запросов со множеством параметров.
OLAP хорошо работает там, где не справляется OLTP, и наоборот, поэтому данные иногда требуется «перебрасывать» из одной системы в другую. Для этого применяется ETL.
Big Data. Работа с большими данными подразумевает их перемещения по разным системам. ETL-системы иногда описывают как решения для помощи Big Data-разработчикам, хотя на самом деле их функциональность нужна не только для этого.
IoT. Internet of Things — это термин для сети, которая дает возможность «умным» устройствам общаться друг с другом. Благодаря IoT техника может связываться друг с другом по локальной сети и в результате решать более сложные задачи, чем при работе по отдельности. Технологию часто используют при обустройстве «умных домов» и похожих автоматизированных систем.
Информация с разных устройств различается и форматом, и особенностями. Чтобы хранить ее в единой базе, нужно применять ETL. Пример — дашборд в «умном доме», который выводит информацию со всех датчиков и сведения о состоянии всех IoT-приборов.
Машинное обучение. Специалисты по искусственному интеллекту и машинному обучению оперируют огромными массивами данных — датасетами. Данные нужно обрабатывать, загружать в машины, использовать для обучения или анализа. ETL используется для миграции данных в единое хранилище, например при создании датасета.
Облачные технологии. Облачные сервера, инструменты и сервисы — замена продуктам, которые нужно держать на собственных машинах. «Облака» используются для хранения данных множества компаний. ETL может потребоваться и при первичной миграции данных в облако, и при последующем переносе новых данных из разных источников.
Аналитика. ETL может использоваться в анализе данных, бизнес-, маркетинговом анализе и других видах аналитики. Аналитика подразумевает большое количество информации, полученной из разных источников: ее нужно сравнивать, анализировать и делать прогнозы на ее основе. Поэтому в области широко применяется ETL, и работодатели часто требуют от соискателей на должность аналитика понимания процессов.
Читайте также Анализ или предсказания: в чем главные отличия аналитика данных от дата-сайентиста?
Устройство ETL-процесса
ETL — это аббревиатура из трех слов, каждое из которых означает какой-либо процесс. Мы говорили о расшифровке выше, а сейчас подробнее расскажем, что именно скрывается за этими словами.
Extract, или извлечение. Система берет данные из одного или нескольких источников и перемещает в промежуточный буфер для дальнейшей обработки. Также может проводиться валидация, проверка данных на соответствие тем или иным критериям. Система проверяет, можно ли загрузить их без потерь в новое хранилище.
Transform, или преобразование. Процесс, в ходе которого система видоизменяет данные под требования нового хранилища. Она меняет формат представления информации, при необходимости — кодировку, очищает данные от лишнего, приводит все к единому виду.
Load, или загрузка. Финальный этап, на котором подготовленные данные загружаются в новое хранилище и размещаются на своих местах. Кроме самой информации, ETL-система может передавать метаданные — данные о данных, например сведения об их структуре.
Что делают ETL-системы
На практике реализация принципа работы состоит более чем из трех шагов. При попадании в реальную ETL-систему данные проходят пять основных этапов.
Загрузка. Этап соответствует процессу Extract в аббревиатуре ETL, но сейчас мы смотрим на происходящее «изнутри» системы, и с этой точки зрения происходит загрузка, а не извлечение. Данные, которые загружаются в ETL-систему, называются сырыми — они пока не обработаны и даже не проверены, их качество может быть любым. Единственная проверка на этом этапе — сверка количества строк. Если их меньше, чем было в источнике, при загрузке произошел сбой.
Валидация. В ходе процесса Extract система должна проверить данные. Этот процесс называется валидация: загруженная информация по очереди проверяется и фильтруется. Система анализирует полноту данных, их корректность, наличие или отсутствие ошибок — «битой» информации. После завершения валидации выдается отчет об ошибках. Если есть сбои, их нужно исправить.
В некоторых процессах используется обогащение данных — получение дополнительных сведений на основе имеющейся информации. Это нужно, если у системы есть другие внутренние источники. Иногда дополнительные данные можно вычислить из существующих с помощью алгоритма.
Мэппинг. Составная часть процесса Transform — преобразования данных под новый формат. После валидации данные чаще всего выглядят как таблица, к которой добавляются нужные столбцы и строки. Мэппинг может происходить по разным алгоритмам в зависимости от ETL-инструмента и его настроек: в системе есть специальные скрипты и формулы.
Агрегация. Это тоже часть трансформации — в системах различаются особенности детализации и представления данных. Чтобы информацию можно было перенести в другую без ошибок, она трансформируется. Это не добавление новых строк и столбцов, как при мэппинге, а изменение связей между самими данными. В результате агрегации информация «склеивается» в новую таблицу — в ней все представлено так, как требует новое хранилище.
Схема преобразования может быть более или менее масштабной в зависимости от поставленной задачи.
Выгрузка. Это реализация процесса Load — преобразованные и очищенные данные выгружаются из системы и попадают в новое хранилище. Используются инструменты ETL-системы и хранилища — так называемые коннекторы и различные части интерфейса.
Примеры ETL-систем
Существуют системы, предназначенные для интеграции данных, их перемещения, объединения и трансформации. В них может входить реализация не только ETL, но и других процессов, связанных с передачей информации. Это, например, программные продукты IBM DataStage, Informatica PowerCenter, Oracle Data Integrator или SAP Data Services. Сюда же можно отнести Sybase ETL Development и Sybase ETL Server, а также многое другое ПО для работы с бизнес-базами. Все это платные решения от ведущих разработчиков.
Кроме специализированных сервисов, ETL-инструменты есть в более общем и более мощном ПО. Это, например, полномасштабная платформа для работы с данными IBM InfoSphere Information Server, СУБД Microsoft SQL Server или российский Cloud Big Data от VK — облачный сервис для больших данных.
Существуют бесплатные решения для работы с ETL: например, проприетарный инструмент Oracle Warehouse Builder или открытые Scriptella ETL Project, Jaspersoft ETL, Apatar и другие.
Как начать пользоваться ETL
Простейшую реализацию ETL можно написать самому. Нужно знать подходящий язык программирования, разбираться в архитектуре процессов, уметь применять алгоритмы для преобразования данных.
С бесплатными ETL-инструментами можно познакомиться, просто скачав и установив их. Для работы потребуется учебная среда, где есть базы данных или другие хранилища, из которых можно переносить данные. Некоторые платные проекты предоставляют ограниченные учебные версии. Информация предоставлена на сайте разработчика.
Чтобы эффективно работать с ETL-процессами, нужно разбираться в теории. Вам помогут учебники, туториалы или профессиональные курсы — под контролем менторов вы получите структурированную и актуальную информацию.
Аналитик данных
Аналитики влияют на рост бизнеса. Они выясняют, какой товар и в какое время больше покупают. Считают юнит-экономику. Оценивают окупаемость рекламной кампании. Поэтому компании ищут и переманивают таких специалистов.

Статьи по теме:
Как и с чем работает незаменимый специалист из сферы Data Science
R или Java — что лучше подходит для анализа больших данных
Екатерина Нестерова объясняет, как определять важность задач по методу ICE и почему аналитики постоянно ошибаются