Домашний веб-сервер для чайников

Привет, Хабр! Относительно недавно после пары лет перерыва в айти, потраченных на изучение японского языка, мне пришлось срочно обновлять свои знания на работе. Ну знаете, искать возможности исполнить все хотелки начальника, как и положено эникею. Меня ждало много увлекательных открытий, но при этом, как водится, и немало боли и борьбы с непонятками. Docker, контейнеры, реверс DNS и реверс прокси, получение TLS сертификатов. В какой-то момент я наконец дошёл до удобного решения, которым я теперь хочу поделиться.
В своё время домашний сервер очень облегчил бы мне понимание Docker’а, да и удобство работы с ним неслабо бы повысил. Поэтому возникла идея написать эту статью, после прочтения которой любой человек даже с поверхностными знаниями в информационных технологиях сможет поставить себе постоянно доступный домашний сервер на базе Docker Swarm с удобной веб-мордой, простым получением TLS-сертификатов и Heroku-подобным функционалом (для чего будем использовать PaaS CapRover).
Статья, в общем-то, рассчитана на новичков, обладающих какими-то техническими знаниями — школьников старших классов, студентов и просто любителей — а потому вряд ли будет интересна серьёзным профессионалам.
Зачем оно нужно?

Ну как минимум потому что это круто, иметь домашний сервер! Да и настраивать всё это дело интересно. При этом он уже за месяца три отобьёт свою стоимость в сравнении с VPS’ом схожей конфигурации. Ну и наконец он просто радует глаз и миленький.
Что же до использования — иметь возможность развернуть в пару кликов дома Docker-контейнеры сразу в формате http://контейнер.мой.домен/ и в ещё один клик подключить к нему SSL неплохо упрощает жизнь. Сейчас всё больше и больше разнообразных приложений и сервисов переезжают в контейнеры и, если вы не любите лишний раз платить большим компаниям, иметь свои аналоги платных сервисов на домашнем сервере это очень удобно.
Ну а удобство для разработчиков и так понятно.
Подготовка
Поскольку мы хотим, чтобы наш домашний сервер был доступен из внешней сети, нужно сделать несколько приготовлений.
Port Forwarding
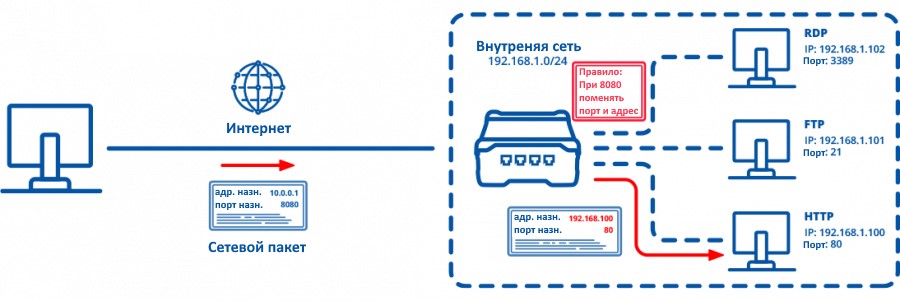
Проверьте наличие у вашего маршрутизатора (роутера) опции Fort forwarding/Port mapping/Перенаправление портов. Это не самый безопасный, но самый простой способ дать нашему серверу путь во внешний мир. Убедитесь что 80, 443 и 3000 порты у вас ничем не заняты — именно их вы будете прописывать IP адресу вашего сервера. Возможно в будущем, например, если вы захотите поднять почтовый сервер, вам придётся прописать дополнительные порты, но пока нужно только это.
Если проводить аналогию для понимания перенаправления портов, то представьте работу мамы в детстве. По умолчанию охранник туда не пустит, но стоит только сказать волшебную фразу «Я к маме», как строгий охранник уже пускает и говорит куда пройти. Вот и тут так же, с нашим NAT’ом роутера, только вместо «Я к маме» вы говорите порт, на что вас направляют куда надо.
Так же стоит убедиться, что у DHCP вашего роутера есть возможность зарезервировать выданный IP адрес за MAC. Скорее всего ваш сервер будет стоять включённым всё время и не просрочит свой выданный IP адрес, но подстраховаться никогда не бывает лишним. Если нельзя — выпишите машине статичный IP вне зоны выдачи адресов DHCP. Это сложнее и неудобнее, но тоже вариант (Кто-то даже скажет что так даже лучше сделать. Но я сейчас за простоту).
Нету этих опций? Возможно ещё не всё потеряно. Проверьте базу https://dd-wrt.com/support/router-database/ на наличие вашего роутера и есть ли тема по нему на 4pda. Если и там пусто. Ну, либо сворачивайте это руководство, либо пора купить новый роутер.
Домен

Конечно, ничто не мешает нам обращаться к нашему домашнему серверу и напрямую по IP адресу, но делать так не рекомендуется: и не особо безопасно, и запоминать IP адрес не просто, да и если у вас динамический, меняющийся каждый раз как вы заново подключаетесь к интернету, IP адрес, то запоминать его вообще бессмысленно. Ну и наконец, у нас много сервисов планируется, а чтобы к ним доступ был тупо по IP адресу, придётся их на разные порты навешивать. Оно вам надо?
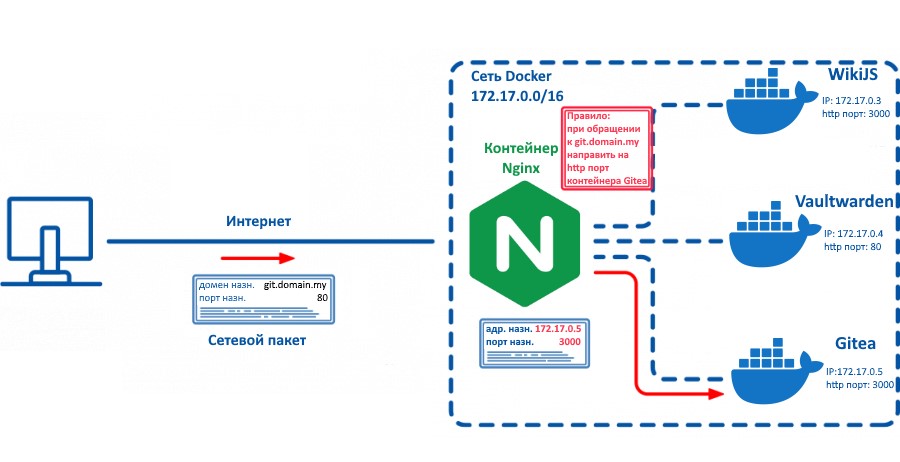
Именно поэтому мы будем использовать домен.
Ну, знаете, ту самую штуку, которую вы вводите в адресной строке. В результате сможем давать сервисам поддомены для удобства и не страдать. Ну, например https://пароли.мой.домен/ для парольного сервиса или https://почта.мой.домен/ для почты. Удобно, в общем, запоминается. Делать это будет Ngnix под капотом нашего PaaS, при желании всегда можете разобраться в конкретике.
Рекомендую я, конечно, домен купить. Цены на домены в популярных зонах достаточно либеральные, платить раз в год, регистраторов куча. В плане выбора регистратора я ничего конкретного советовать не буду. Адекватнее всего ориентироваться по цене и отзывам. Разве что маленькое наблюдение: если регистратор требует миллиарды шекелей за такие вещи, как банальное управление DNS записями, то возможно это не очень хороший регистратор и следует посмотреть в другую сторону.
Впрочем если вы только пощупать пришли, то домен можно получить и бесплатно. Есть такой регистратор — Freenom, там можно бесплатно достать домен в зонах .tk, .ml, .ga, .cf или .gq. Правда как часто бывает с чем-то бесплатным, сайт глючный. Если на проверке доменов у вас всё время пишется, что домен занят, попробуйте поставить сразу полный путь. То есть вводите в проверочное поле не мой_домен, а сразу, скажем, мой_домен.tk.
Очевидно, что если что-то досталось бесплатно, то и потерять его легко — отзывы у Freenom в этом плане далеки от хороших. Так что если планируете что-то серьёзное, то лучше домен себе всё-таки купить у регистратора. Однако для маленького домашнего сервера потенциальная потеря домена не критична.
Cloudflare

Тут мы уже входим в пространство вкусовщины. Вам ничто не мешает использовать и редактор DNS записей вашего регистратора или любой другой сервис управления DNS записями домена. Тут, на хабре, вон вообще CloudFlare раком интернета недавно называли. Но с другой стороны, CloudFlare даже в базовой, бесплатной версии имеет достаточно много приятных фишек, которые ваш регистратор скорее всего не предоставляет. Тут и какая-никакая защита от DDoS, кеширование, расширенные возможности управления доступом и так далее и в том же духе. Плюс в одном из следующих пунктов, когда мы поднимем контейнер для DDNS, будет использоваться именно CloudFlare (впрочем настроить DDNS с другим провайдером вроде DuckDNS — задача достаточно тривиальная).
Правда многие фишки пройдут мимо нас, поскольку проксирование у CloudFlare на wildcard-записи (ну, это записи включающие всё пространство имён *.мой.домен) не работает (ну, за бесплатно). Однако ничего не мешает потом, уже для отдельных сервисов, сделать конкретную запись и пожать все плюшки платформы. Ну или ещё лучше, если у вас статический IP адрес, вообще без DDNS обойтись.
Платформа
Физический путь

Удобство физического пути очевидно — стоит отдельная машинка, не мешает основной работе, радует глаз.
Если спросить, что же использовать как платформу, наверняка многие ответят Малинку (то есть Raspberry Pi). На мой взгляд это не самый лучший выбор для данного случая.
Raspberry Pi отлично подходят для самодельных решений разнообразной направленности, но по соотношению цена/производительность не являются каким-либо лидером. И, хотя сейчас уже множество софта доступно под ARM системы, под x86 программы всё-таки чувствуют себя постабильнее.
Кто-то захочет переоборудовать старую машину или собрать на старых Xeon’ах себе компьютер для веб-сервера. И это тоже вариант, хотя по потреблению электроэнергии не оптимальный.
Я же советовал бы купить для данных целей недорогой (или не очень дешёвый, если вы хотите постоянно запускать «тяжёлые» задачи на вашем сервере) мини-пк (иначе называемый неттоп). Доступные варианты с 8 гигабайтами оперативной памяти, четырёхядерным Celeron и SSD на 128 гигабайт можно найти за 150-200 долларов и этого более чем хватит для домашних задач. При этом он будет компактным, тихим, удобным в размещении, достаточно приятно выглядящим и с низким TDP. Даже в самые дешёвые модели обычно можно доставить как минимум один, а порой и два 2,5 дюймовых диска, так что как файловую помойку его, в общем-то, тоже можно использовать. Хотя лучше превратить его в личное облако, а как файловый сервер использовать отдельное NAS-устройство — для отказоустойчивого хранения большого количества данных форм фактор мини-пк не слишком располагает.
Помимо этого, если вы «наиграетесь» и решите, что оно не ваше, такому компьютеру будет легко найти место. Например поставить обратно Windows и отдать маме/тёте Вале из третьего подъезда. Для офисной работы и использования браузера он подойдёт прекрасно.
А если вы за чуточку большую цену взяли мини-пк с несколькими сетевыми портами, то сможете превратить его в невероятно мощный и функциональный маршрутизатор, поставив сверху OpenWRT, PFsense, ClearOS или ещё какую-нибудь систему для роутеров. Ну и вообще альтернатив много, когда и если наиграетесь с предложенным мной вариантом.
Сразу, правда, надо учесть: шансы, что у такой машинки не будет работать Wi-Fi под линуксом, мягко говоря, не самые маленькие. Так что планируйте проводное соединение.
Заранее погуглите, на какую клавишу вызвать boot menu у вашей машинки. А образ для установки, если вы на Windows, лучше всего на флешку записывать программой Rufus.
Виртуальный путь

Если у вас есть просто живой интерес к тому, что и как настроить, определиться надо ли оно или не надо, то настраиваем виртуальную машину.
Тут стоит провести некоторое разграничение в понимании, поскольку дальше у нас будут ещё и контейнеры Docker. Внешне и по структуре они очень похожи, но вот по использованию неплохо так различаются.
Виртуальная машина — это именно то, как оно звучит — компьютер, которой на самом деле не существует, живущий внутри нашего. Её в какой-то мере можно сравнить с картонной коробкой. Её нужно где-то достать, развернуть, заполнить. Она стоит и занимает место, даже если не до конца заполнена. И залезть внутрь этой коробки иначе как сверху достаточно проблематично.
А контейнер — это как пакетик из магазина. Вроде и служит примерно той же цели, что и коробка, но внутрь что-то положить и достать проще, укладывать по-особому не нужно,места много не занимает, и выкинуть не жалко, и продырявить просто. Говоря же чуть более нормальным языком — контейнер это такая недо-виртуалка, которая ведёт себя скорее как процесс программы.

Конкретный гипервизор (ну, программа, где ваши виртуальные машины создаются и управляются) — на ваше усмотрение. Лучше, конечно, использовать гипервизор первого типа (они, как правило, быстрее, поскольку работают “под” операционной системой, а не “над” ней, как гипервизоры второго типа), но нашему серверу это не очень критично.
Внимание, любители всяких игруль, мобильных и не очень, на Windows — большая часть гипервизоров конфликтуют с эмуляторами Android для игр и с некоторыми античит решениями. Нормально только Bluestacks для Hyper-V работает, так что заранее выберите, что вам важнее.
VirtualBox

Для начала распишу для VirtualBox, который доступен на всех основных платформах, хотя и не отличается высокой скоростью.
Нажмите на кнопку New (Создать) для создания новой машины, и, ориентируясь по своей логике, задайте все настройки — если что, то потом всегда сможете поправить. Правда, меньше чем 2 гигабайта оперативной памяти лучше не ставить.
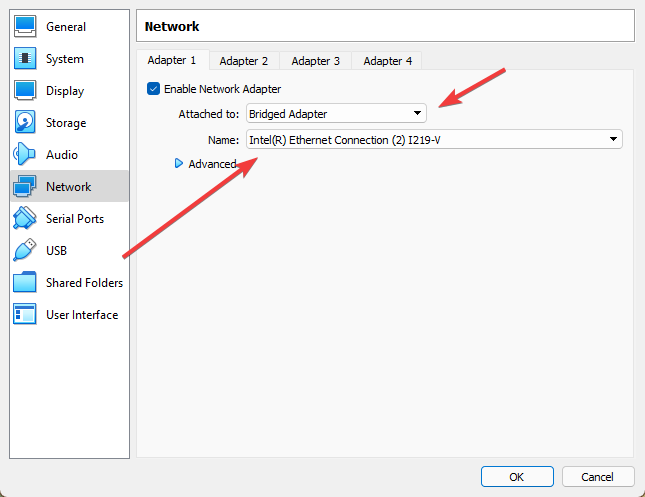
После создания машины войдите в её настройки. В разделе Storage (Носители) добавьте ваш образ к дисководу (синяя иконка), а в разделе Network (сеть) поменяйте тип подключения на Bridged Adapter (Сетевой мост) и выберите сетевую карту, по которой к вам приходят интернеты, после чего сохраните.

Hyper-V

Поскольку сам я в основном пользуюсь Windows, то предпочитаю использовать Hyper-V — встроенный в Pro версию системы гипервизор первого типа. Если вы пользователь Windows, то вам я тоже его советую — как и положено гипервизору первого типа, он весьма радует своей производительностью.
Чтобы использовать Hyper-V, активируйте его в Turn Windows Features on or off (Включение или отключение компонентов Windows) и перезагрузите компьютер. Вероятно, вам ещё придётся включить аппаратную виртуализацию в BIOS, если вы ещё не делали это. Также необходимо создать в Hyper-V manager (Диспетчер Hyper-V) сетевой интерфейс, ведущий во внешнюю сеть. Кликните справа на Virtual Switch Manager (Диспетчер виртуальных коммутаторов), выберите External (Внешний) и нажмите Create Virtual Switch (Создать виртуальный коммутатор). Далее в настройках External Network (Внешняя сеть) выберите сетевую карту, по которой к вам приходят интернеты, а потом сохраните.

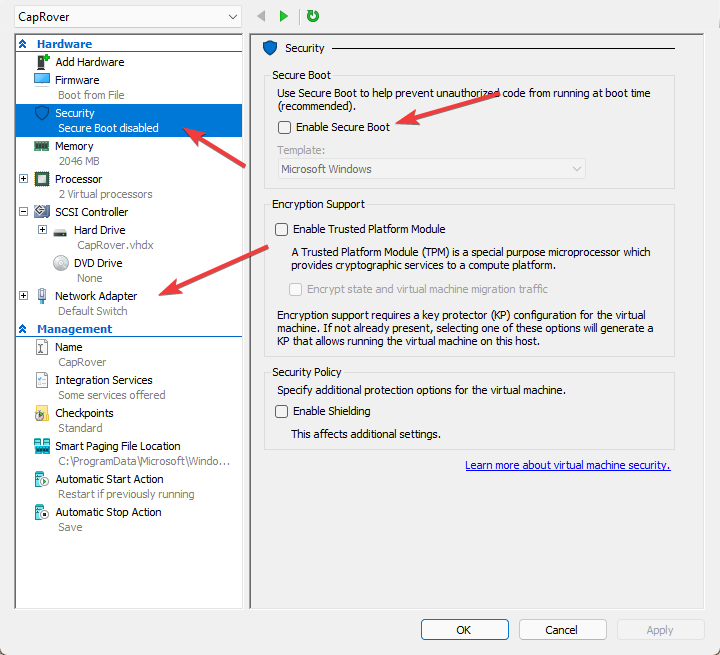
После этого создайте новую машину в Hyper-V manager (но только не создавайте «быструю» машину, там всё не слава богу), а потом пройдите в её свойства и отключите Secure Boot (если машина 2-ого поколения). Остальные параметры по вкусу, но меньше 2 гигабайт оперативной памяти лучше не ставить. Ну и как сетевой интерфейс, очевидно, нужно поставить свежесозданный.
Установка и настройка системы

При выборе дистрибутива для установки у нас есть некоторый выбор (Но свериться с поддерживаемыми платформами на https://docs.docker.com/engine/install/ не помешает). Официально докер рекомендуется ставить на Ubuntu, я обычно предпочитаю Debian, но нам в целом не принципиально. Однако возможные подводные камни я распишу только для этих двух дистрибутивов.
И да, если можете, то лучше напрямую смотрите инструкции. А то информация в интернете имеет привычку устаревать и есть шанс, что к моменту, как вы это читаете, всё уже десять раз поменялось.
В случае с Ubuntu скачайте Ubuntu Server — на сервере графический интерфейс ни к чему, вы даже не будете подключать к нему монитор после изначальной установки. При установке важный момент — НЕ отмечайте Docker в качестве установки по умолчанию. Иначе он поставится как snap пакет, будет глючить, тупить и вообще, зачем вам лишние проблемы, не дружите со snap’ами, это плохая компания.
После установки системы копипастим по одной эти строчки (вы же уже подключились по SSH, правда ведь? Если нет, то чуть подальше будет инструкция) или вбиваем вручную:
sudo apt-get update sudo apt-get install \ ca-certificates \ curl \ gnupg \ lsb-release curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update sudo apt-get install docker-ce docker-ce-cli containerd.ioПри установке Debian не надо отмечать web server, поскольку в качестве него у нас Nginx внутри контейнера Docker’а с нашим PaaS работать будет.
После установки системы копипастим эти строчки:
sudo apt-get update sudo apt-get install \ ca-certificates \ curl \ gnupg \ lsb-release curl -fsSL https://download.docker.com/linux/debian/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg echo \ "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/debian \ $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null sudo apt-get update sudo apt-get install docker-ce docker-ce-cli containerd.ioВ общем скачайте что вам нравится, запишите на флешку при физическом пути, подключите к виртуалке при виртуальном и давайте, устанавливайте по инструкциям.
Помимо того, чтобы вводить команды вручную, вы можете использовать Ansible или другие системы для развёртывания, но данное руководство их проигнорирует, поскольку ничего сложного мы не делаем. Просто знайте, что если вам потребуется однотипно настраивать несколько машин, то можно по ssh удобненько это делать через Ansible. Но ssh игнорировать всё же не стоит, ведь как минимум подключившись к своей машине по нему, вы сможете тупо копипастить все команды из руководств, а не вводить вручную.
Ansible это достаточно важный инструмент для Linux-админа и, если вы планируете сдавать или хотя бы просто учиться на сертификации от RedHat, то он вам понадобится. Ну так, на будущее.
Ssh клиентов великое множество, я обычно пользуюсь встроенным в Windows OpenSSH (хотя он встроен, но в старых версиях Windows 10 может быть по-умолчанию отключен. Включается в Turn Windows Features On and Off (Управление дополнительными компонентами)). Просто открываете PowerShell и пишите:
ssh логин_в_linux@IPшник_сервераА после вводите пароль своего пользователя. Тут стоит отметить, что использовать ssh с паролем это не особо безопасно (но зато проще всего), и, если у вас будет желание с этим разобраться, то лучше настроить ssh ключ.
Систему мы настроили, но не спешите ставить CapRover. Сначала вернёмся к роутеру. Найдите в нём ваш сервер и зарезервируйте его IP адрес в DHCP. Ну или поменяйте его на что-нибудь приятное и зарезервируйте. У вас есть чувство прекрасного, я уверен. После этого пропишите перенаправление с 80, 443 и 3000 портов маршрутизатора на 80, 443 и 3000 порты нашего сервера.
Вот пример того, как оно выглядит в моём роутере TP-Link:
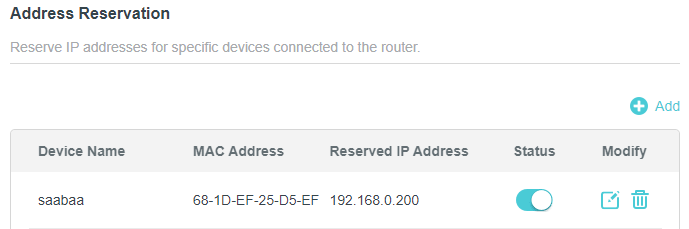
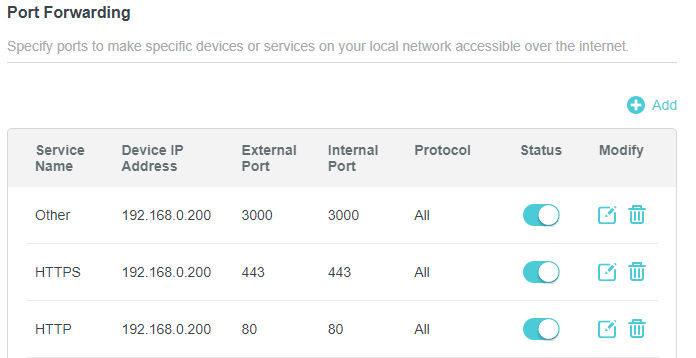
Теперь идём к домену. Войдите в CloudFlare или DNS редактор вашего регистратора и создайте следующую запись:
Тип: A
Хост: *.ваш.домен
Запись: указывает на ваш внешний IP адрес

Если вы не знаете как узнать ваш внешний IP адрес, то посмотрите в настройках интерфейса, роутера, где угодно. Ну или наберите в поисковике что-нибудь вроде «мой IP», если копаться не хочется.
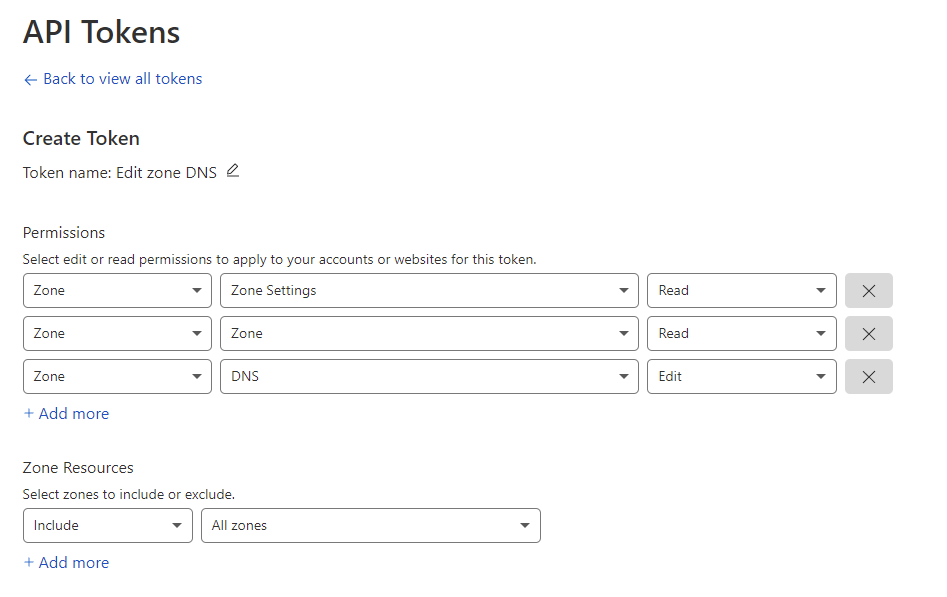
Можете сразу не отходя от кассы создать токен, если планируете динамически обновлять DNS при изменении вашего IP адреса.
Для этого пройдите по ссылке https://dash.cloudflare.com/profile/api-tokens и создайте токен со следующими свойствами:
Zone — Zone Settings — Read
Zone — Zone — Read
Zone — DNS — Edit
Include — All zones
Сохраните длинный Cloudflare API токен, но далеко не убирайте.
Всё, теперь заходим на сервер и пишем волшебную команду, которая поднимает нашу систему для управления контейнерами:
docker run -p 80:80 -p 443:443 -p 3000:3000 -v /var/run/docker.sock:/var/run/docker.sock -v /captain:/captain caprover/caproverЕсли вы плохо знакомы с Docker’ом, то тут мы запускаем наш первый контейнер — небольшой PaaS CapRover. Помимо этого мы даём портам в контейнере путь на волю (-p 80:80 -p 443:443 -p 3000:3000), позволяем контейнеру иметь доступ к демону Docker на хост-машине (-v /var/run/docker.sock:/var/run/docker.sock) и делаем так, чтобы папка из контейнера хранила своё содержимое в папке на хосте (-v /captain:/captain). Если так не сделать, то при перезапуске контейнера всё содержимое: настроечные файлы и другие данные нашего контейнера, потеряются навсегда. Так что никогда не забывайте указывать команду -v при работе docker в консоли, чтобы потом не плакать у разбитого корыта. Ну а caprover/caprover — это образ на Docker Hub.
Подождите немного и зайдите либо по айпи адресу, либо по адресу вашего домена:3000 (например http://мой.домен:3000), введите пароль captain42 . После этого тут же введите в нижнее поле ваш домен и нажмите Update Domain. Можете также нажать на Enable HTTPS, но вот на Force HTTPS не надо нажимать — Cloudflare и так трафик у вас (если вы оставили рекомендуемые настройки) с http на https переводит. Конфликтов на этом поводе нам не надо.
Настала пора запустить наш первый контейнер внутри PaaS.
Перейдите в веб панели в раздел Apps, нажмите на One-Click Apps/Database, найдите CloudFlare DDNS. Это достаточно простой контейнер, весь смысл которого сводится к тому чтобы раз в пять минут проверять, изменился ли IP адрес сервера, и, если изменился, обновлять DNS запись на CloudFlare.
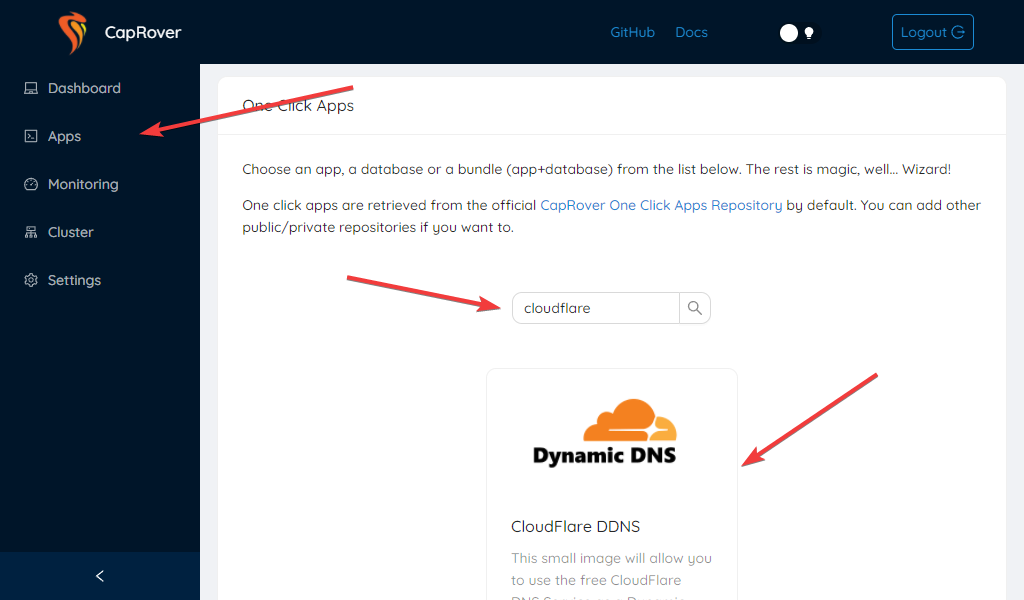
После того как вы нажали на него, вы увидите много опций для ввода. Вообще говоря, чтобы всё заработало нам достаточно просто указать наш сохранённый токен CloudFlare и задать какое-нибудь имя. Но давайте всё-таки разберёмся, что именно мы видим.
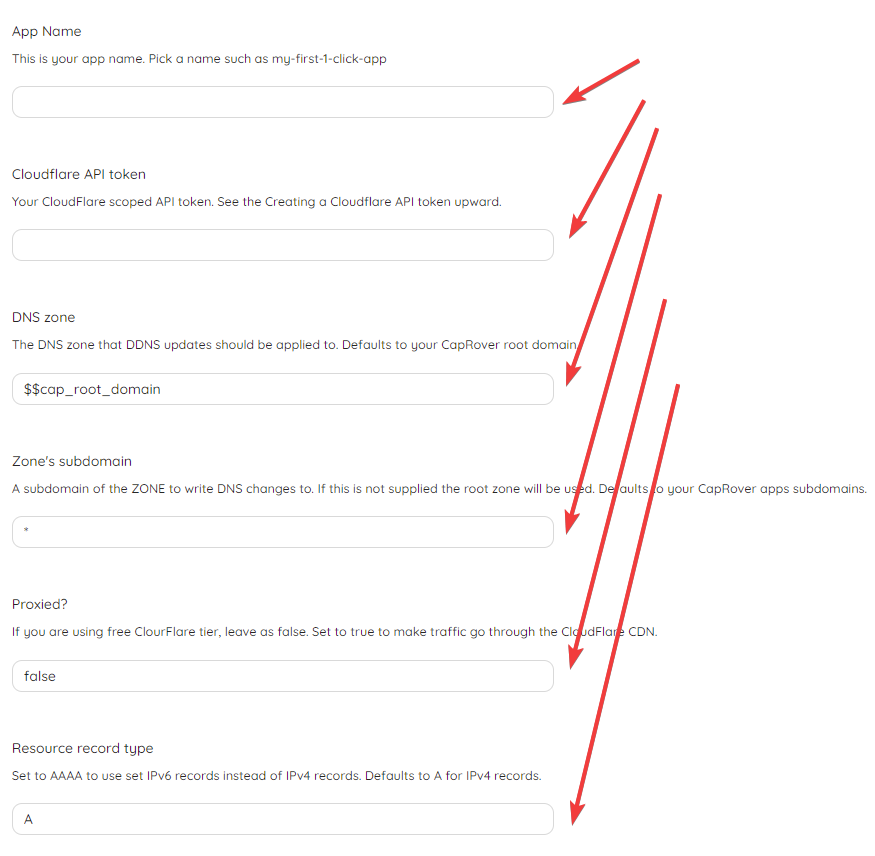
А видим мы опции ввода так называемых переменных окружения. Не всех правда, а только тех, которые указал автор конфигурационного файла для CapRover. Значения из этих переменных контейнер может достать и использовать в своих целях, проще говоря через них задаётся начальная конфигурация контейнера.
Так вот, задайте какое-нибудь имя, вставьте ранее сохранённый токен и нажмите Deploy. Контейнер заработал. Теперь можете делать что угодно!
Чуть сложнее
Этот контейнер был простым, без веб доступа, но что у тех, к которым мы будем иметь доступ? Да в общем всё так же, разве что ещё можно включить https, задать домен, указать HTTP порт контейнера и включить websocket. Попробуйте, это просто и интересно!

Использование

И вот наконец у нас всё стоит и работает.
Зачем оно вам? Ну, если вы до сих пор не знаете — придумайте. Для установки в один клик в CapRover доступно множество приложений для повседневного использования. Например менеджер паролей Vaultwarden. Торрент-клиент Qbittorrent. Сервер Minecraft. Боты для Discord. Вариантов много.
Я, например, держу стол для игры в DnD с друзьями Foundry VTT, веб-интерфейс для пробуждение от спячки моего домашнего компьютера (чтобы потом подключаться по RDP), свой маленький гит на базе Gitea, удобный фронтэнд для чтения Reddit’а libReddit, веб-архив для закладок и ещё кучу всякой всячины для тестов и изучения.
Ничто не мешает вам самому поэкспериментировать с контейнерами, которых в списке ещё нет, а если результат будет удовлетворительным — опубликовать свой конфиг на Github среди других приложений для установки в один клик.
В самом начале мы установили SSH, так что если вы захотите более тонкой настройки, подключите и тыкайтесь. Советую также зайти на SSH через VS Studio Code с установленным расширением Docker’а, и установить его же сразу там на ваш сервер. Теперь наблюдать, управлять и чистить мусор в контейнерах гораздо удобнее.
Что дальше?
Возможно, вам уже хватило, вы поняли что это не ваше и вообще. Тоже неплохой результат. Возможно, вы просто хотели домашний сервер и получили его — опять же, к результату мы пришли. Или же вы хотите большего — и это тоже прекрасный результат! Надо понимать, что хотя Docker Swarm уже несколько протух, для небольших нагрузок, вроде домашнего использования, он подходит на отлично. А если вам мало, то, разобравшись как и что тут работает, вы можете медленно начать своё движение к изучению kubernetes.
Что можно посоветовать конкретного? Ну, если Docker вам интересен и хочется в нём разобраться поглубже, то вводный цикл статей от Microsoft достаточно приятно и наглядно объясняет как и что оно.
Если хотите покрупнее брать — и в Hyper-V получше разобраться, и в контейнерах и чуточку затронуть кубер, то вот ещё у них есть неплохие материалы.
Не, не, вы не подумайте, я хоть и виндовый админ (ну хорошо-хорошо, эникей а не админ), но не сказать чтобы прям топлю за Microsoft, просто материалы у них бесплатные и достаточно толковые, на мой взгляд.
Коли от Microsoft тошнит — ищите курсы. В англоязычных интернетах с этим проще — идёшь на Udemy или Pluralsight и выбираешь курс по теме, где люди поменьше в комментах бугуртят на качество, и в бой. С русскоязычными курсами посложнее в выборе, но кто ищет — тот найдёт.
Ну и наконец если в целом вся эта тема с сервисами на своём домашнем сервере вам интересна, то вот отличный список selfhosted решений на все случаи жизни.
В общем, да пребудет с вами IT сила!
Как создать веб-сервер на Python
Создание веб-сервера на Python — несложная, но увлекательная задача, которая может стать отличным стартом для начинающих разработчиков. В этой статье мы разберем, как создать простой веб-сервер на языке программирования Python с использованием популярных библиотек. ��
Шаг 1: Выбор библиотеки
Для создания веб-сервера на Python существует несколько популярных библиотек:
- Flask — легковесный, удобный и легко настраиваемый фреймворк
- Django — мощный, но более сложный фреймворк с большим количеством функций «из коробки»
- FastAPI — современный, быстрый и асинхронный фреймворк
Для нашего примера выберем Flask, так как он идеально подходит для создания небольших веб-серверов и требует минимальных настроек.
Шаг 2: Установка и настройка Flask
Для начала установим Flask с помощью команды:
pip install Flask
Теперь создадим файл с нашим веб-сервером, например, app.py . В этом файле импортируем Flask и создадим экземпляр приложения:
from flask import Flask app = Flask(__name__) @app.route("/") def hello(): return "Hello, World!" if __name__ == "__main__": app.run()
Здесь мы создаем приложение Flask, определяем один маршрут (главную страницу) и функцию hello() , которая возвращает приветственное сообщение. Также, если файл запущен как основной, то запускается веб-сервер с нашим приложением.
Python-разработчик: новая работа через 9 месяцев
Получится, даже если у вас нет опыта в IT

Шаг 3: Запуск веб-сервера
Для запуска нашего веб-сервера выполним следующую команду в терминале:
python app.py
После запуска вы увидите сообщение о том, что сервер работает на http://127.0.0.1:5000/ . Откройте этот адрес в вашем браузере и увидите сообщение «Hello, World!».
�� Поздравляем! Вы только что создали свой первый веб-сервер на Python с использованием Flask!
Шаг 4: Дальнейшее развитие
Теперь, когда у вас есть базовый веб-сервер, вы можете добавить больше функциональности, например:
- Реализовать поддержку разных HTTP-методов (GET, POST, PUT, DELETE)
- Добавить обработку запросов с данными (формы, JSON)
- Создать систему аутентификации и авторизации
- Интегрировать базу данных для хранения и обработки данных
Не забывайте изучать документацию и искать примеры в интернете, чтобы углубить свои знания и навыки в создании веб-серверов на Python! ��
Пишем свой веб-сервер на Python: сокеты
Подпишись на обновления блогa, чтобы не пропустить следующий пост!
Оглавление
- Что определяет хорошего разработчика ПО?
- Что же такое веб-сервер?
- Как общаться с клиентами по сети
- Простейший TCP сервер
- Простейший TCP клиент
- Заключение
- Cсылки по теме
Лирическое отступление: что определяет хорошего разработчика?

Разработка ПО — это инженерная дисциплина. Если вы хотите стать действительно профессиональным разработчиком, то необходимо в себе развивать качества инженера, а именно: системный подход к решению задач и аналитический склад ума. Для вас должно перестать существовать слово магия. Вы должны точно знать как и почему работают системы, с которыми вы взаимодействуете (между прочим, полезное качество, которое находит применение и за пределами IT).
К сожалениею (или к счастью, ибо благоприятно складывается на уровне доходов тех, кто осознал), существует огромное множество людей, которые пишут код без должного понимания важности этих принципов. Да, такие горе-программисты могут создавать работающие до поры до времени системы, собирая их из найденных в Интернете кусочков кода, даже не удосужившись прочитать, как они реализованы. Но как только возникает первая нестандартная проблема, решение которой не удается найти на StackOverflow, вышеупомянутые персонажи превращаются в беспомощных жертв кажущейся простоты современной разработки ПО.
Для того, чтобы не оказаться одним из таких бедолаг, необходимо постоянно инвестировать свое время в получение фундаментальных знаний из области Computer Science. В частности, для прикладных разработчиков в большинстве случаев таким фундаментом является операционная система, в которой выполняются созданные ими программы.
Веб-фреймворки и контейнеры приложений рождаются и умирают, а инструменты, которыми они пользуются, и принципы, на которых они основаны, остаются неизменными уже десятки лет. Это означает, что вложение времени в изучение базовых понятий и принципов намного выгоднее в долгосрочной перспективе. Сегодня мы рассмотрим одну из основных для веб-разработчика концепций — сокеты. А в качестве прикладного аспекта, мы разберемся, что же такое на самом деле веб-сервер и начнем писать свой.
Что такое веб-сервер?
Начнем с того, что четко ответим на вопрос, что же такое веб-сервер?
В первую очередь — это сервер. А сервер — это процесс (да, это не железка), обслуживающий клиентов. Сервер — фактически обычная программа, запущенная в операционной системе. Веб-сервер, как и большинство программ, получает данные на вход, преобразовывает их в соответствии с бизнес-требованиями и осуществляет вывод данных. Данные на вход и выход передаются по сети с использованием протокола HTTP. Входные данные — это запросы клиентов (в основном веб-браузеров и мобильных приложений). Выходные данные — это зачастую HTML-код подготовленных веб-страниц.
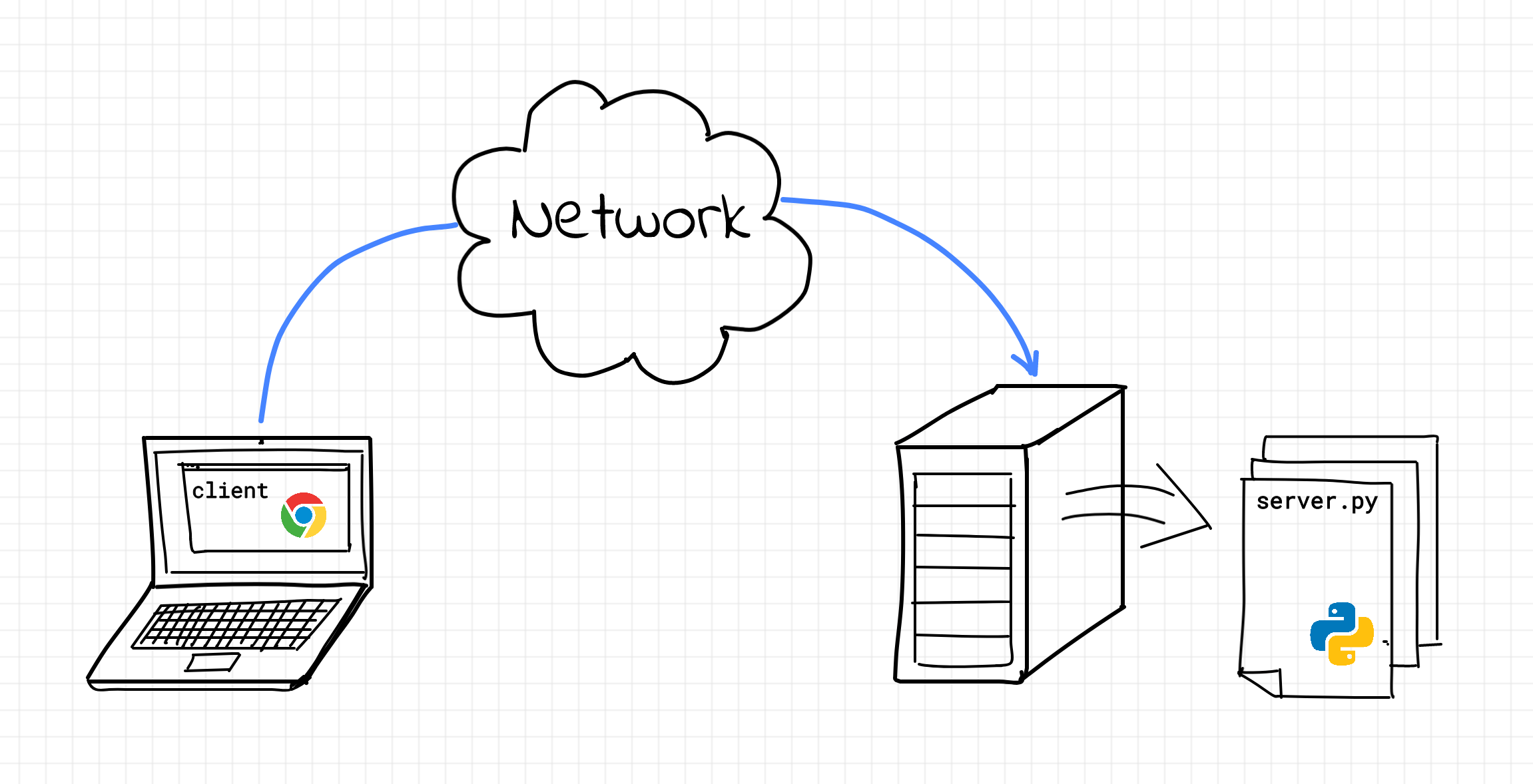
На данном этапе логичными будут следующие вопросы: что такое HTTP и как передавать данные по сети? HTTP — это простой текстовый (т.е. данные могут быть прочитаны человеком) протокол передачи информации в сети Интернет. Протокол — это не страшное слово, а всего лишь набор соглашений между двумя и более сторонами о правилах и формате передачи данных. Его рассмотрение мы вынесем в отдельную тему, а далее попробуем понять, как можно осуществлять передачу данных по сети.
Как компьютеры взаимодействуют по сети
В Unix-подобных системах принят очень удобный подход для работы с различными устройствами ввода/вывода — рассматривать их как файлы. Реальные файлы на диске, мышки, принтеры, модемы и т.п. являются файлами. Т.е. их можно открыть, прочитать данные, записать данные и закрыть.
При открытии файла операционной системой создается т.н. файловый дескриптор. Это некоторый целочисленный идентификатор, однозначно определяющий файл в текущем процессе. Для того, чтобы прочитать или записать данные в файл, необходимо в соответсвующую функцию (например, read() или write() ) передать этот дескриптор, чтобы четко указать, с каким файлом мы собираемся взаимодействовать.
int fd = open("/path/to/my/file", . ); char buffer[1024]; read(fd, buffer, 1024); write(fd, "some data", 10); close(fd); Очевидно, что т.к. общение компьютеров по сети — это также про ввод/вывод, то и оно должно быть организовано как работа с файлами. Для этого используется специальный тип файлов, т.н. сокеты.
Сокет — это некоторая абстракция операционной системы, представляющая собой интерфейс обмена данными между процессами. В частности и по сети. Сокет можно открыть, можно записать в него данные и прочитать данные из него.
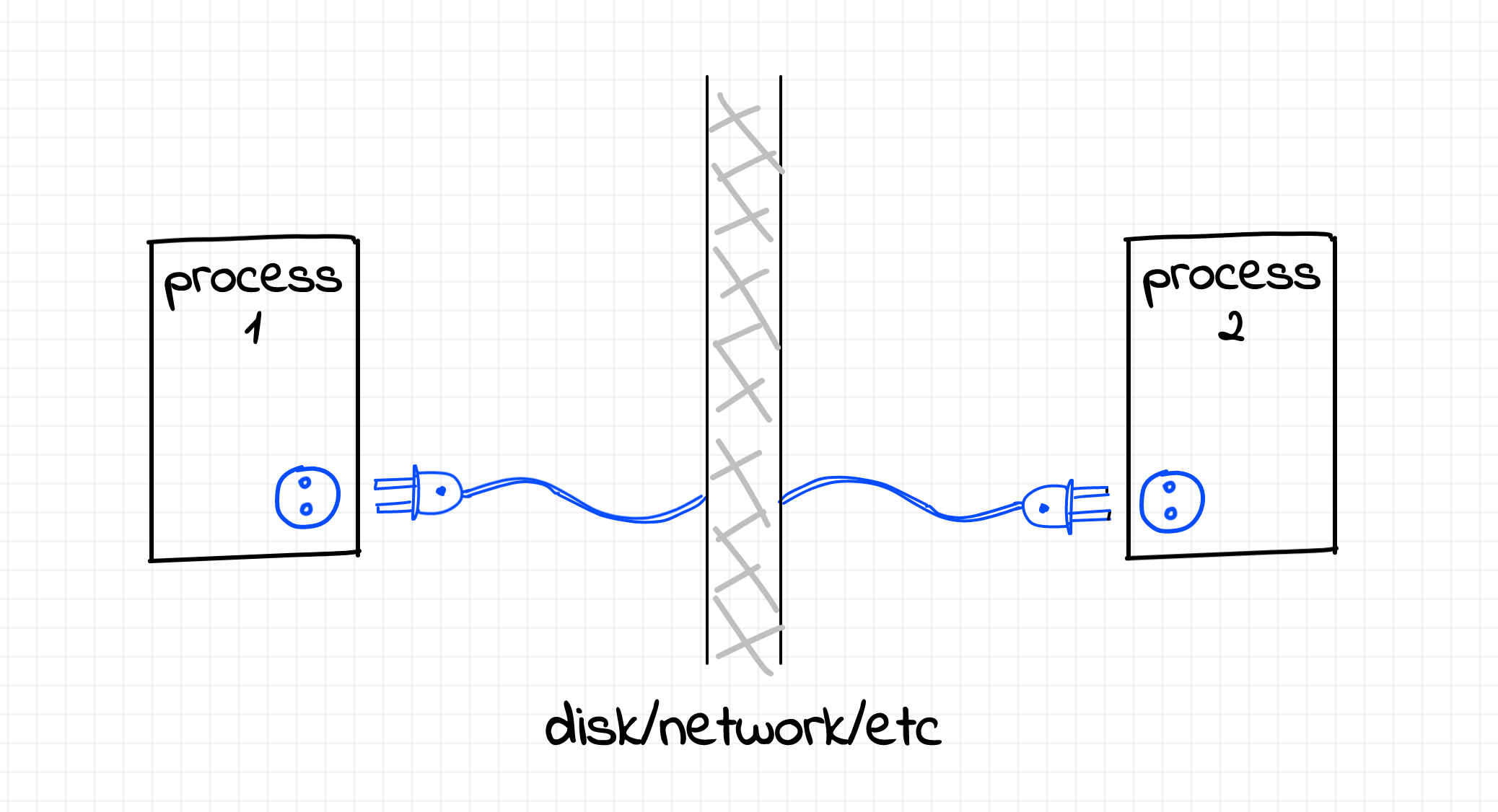
Т.к. видов межпроцессных взаимодействий с помощью сокетов множество, то и сокеты могут иметь различные конфигурации: сокет характеризуется семейством протоколов (IPv4 или IPv6 для сетевого и UNIX для локального взаимодействия), типом передачи данных (потоковая или датаграммная) и протоколом (TCP, UDP и т.п.).
Далее будет рассматриваться исключительно клиент-серверное взаимодействие по сети с использованием сокетов и стека протоколов TCP/IP.
Предположим, что наша прикладная программа хочет передать строку «Hello World» по сети, и соответствующий сокет уже открыт. Программа осуществляет запись этой строки в сокет с использованием функции write() или send() . Как эти данные будут переданы по сети?
Т.к. в общем случае размер передаваемых программой данных не ограничен, а за один раз сетевой адаптер (NIC) может передать фиксировнный объем информации, данные необходимо разбить на фрагменты, не превышающие этот объем. Такие фрагменты называются пакетами. Каждому пакету добавляется некоторая служебная информация, в частности содержащая адреса получателя и отправителя, и они начинают свой путь по сети.
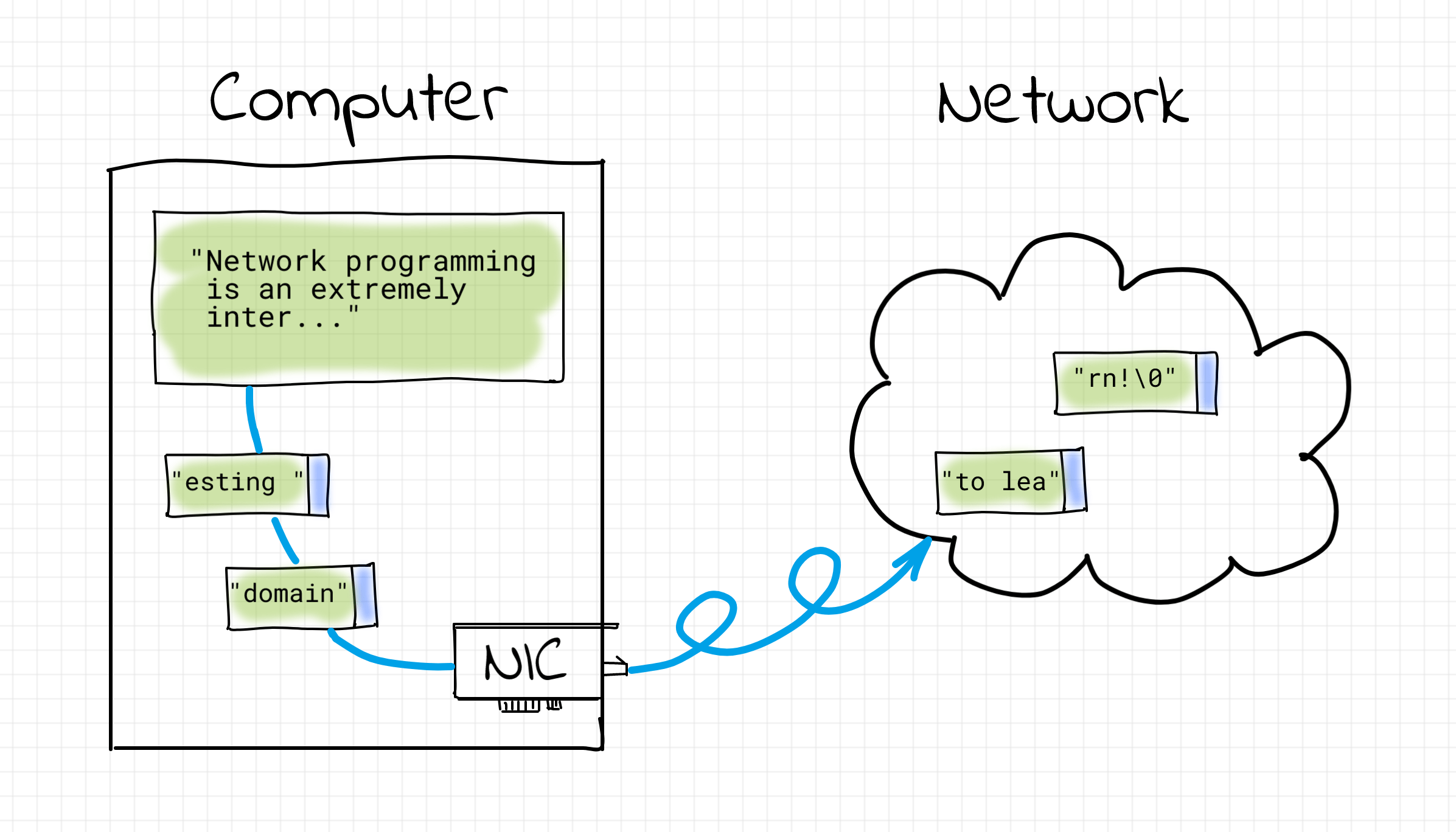
Адрес компьютера в сети — это т.н. IP-адрес. IP (Internet Protocol) — протокол, который позволил объединить множество разнородных сетей по всеми миру в одну общую сеть, которая называется Интернет. И произошло это благодаря тому, что каждому компьютеру в сети был назначен собственный адрес.
В силу особенности маршрутизации пакетов в сети, различные пакеты одной и той же логической порции данных могут следовать от отправителя к получателю разными маршрутами. Разные маршруты могут иметь различную сетевую задержку, следовательно, пакеты могут быть доставлены получателю не в том порядке, в котором они были отправлены. Более того, содержимое пакетов может быть повреждено в процессе передачи.
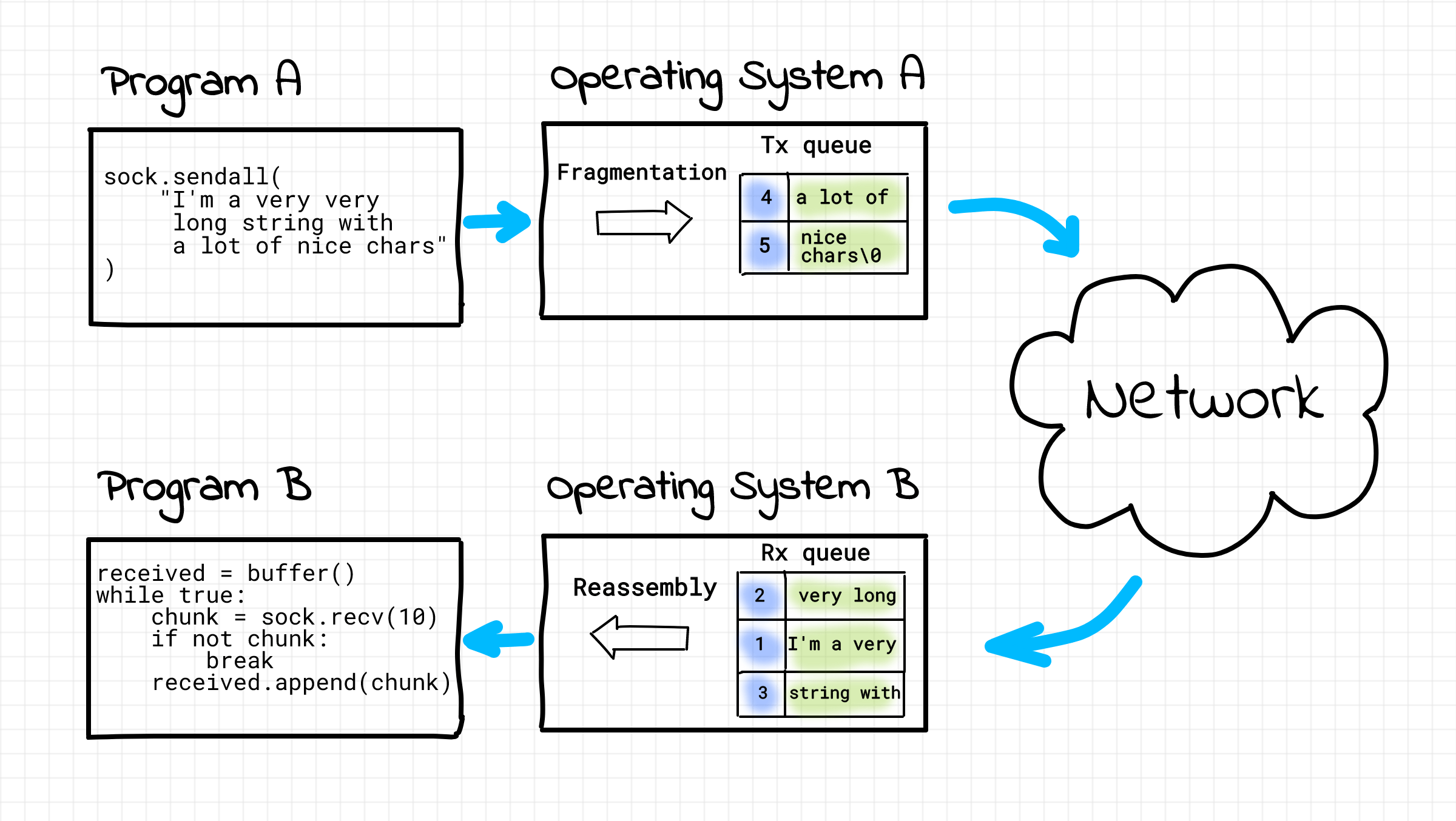
Вообще говоря, требование получать пакеты в том же порядке, в котором они были отправлены, не всегда является обязательным (например, при передаче потокового видео). Но, когда мы загружаем веб-страницу в браузере, мы ожидаем, что буквы на ней будут расположены ровно в том же порядке, в котором их нам отправил веб-сервер. Именно поэтому HTTP протокол работает поверх надеждного протокола передачи данных TCP, который будет рассмотрен ниже.
Чтобы организовать доставку пакетов в порядке их передачи, необходимо добавить в служебную информацию каждого пакета его номер в цепочке пакетов и на принимающей стороне делать сборку пакетов не в порядке их поступления, а в порядке, определенном этими номерами. Чтобы избежать доставки поврежденных пакетов, необходимо в каждый пакет добавить контрольную сумму и пакеты с неправильной контрольной суммой отбрасывать, ожидая, что они будут отправлены повторно.
Этим занимается специальный протокол потоковой передачи данных — TCP.
TCP — (Transmission Control Protocol — протокол управления передачей) — один из основных протоколов передачи данных в Интернете. Используется для надежной передачи данных с подтверждением доставки и сохранением порядка пакетов.
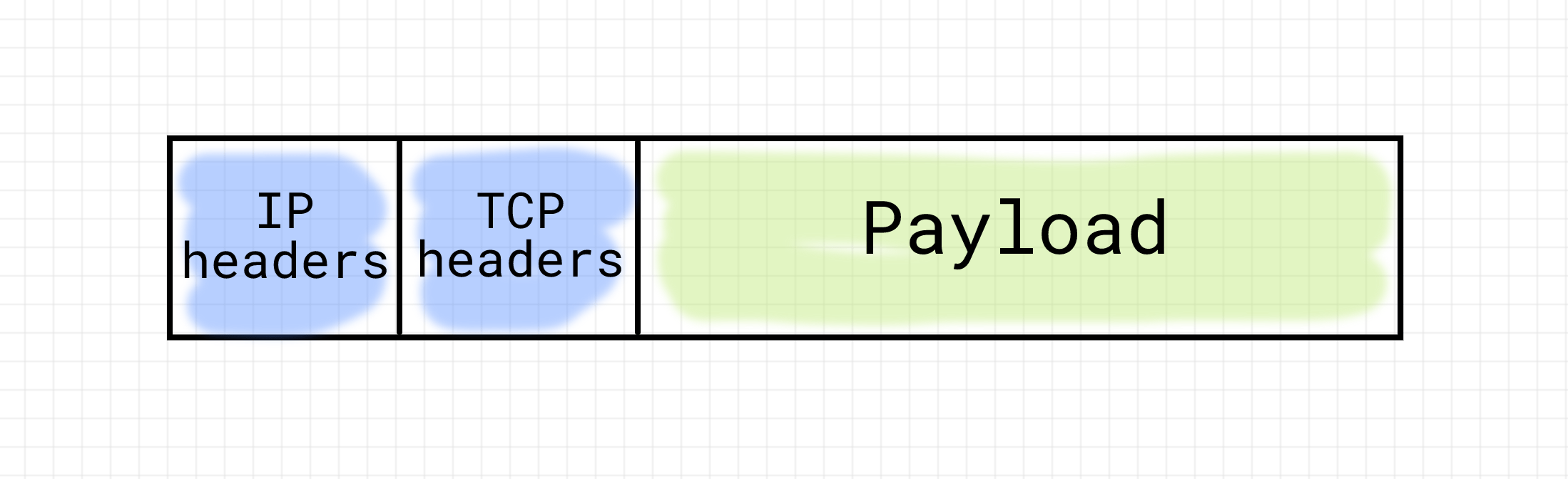
В силу того, что передачей данных по сети по протоколу TCP на одном и том же компьютере может заниматься одновременно несколько программ, для каждого из таких сеансов передачи данных необходимо поддерживать свою последовательность пакетов. Для этого TCP вводит понятие соединения. Соединение — это просто логическое соглашение между принимающей и передающей сторонами о начальных и текущих значениях номеров пакетов и состоянии передачи. Соединение необходимо установить (обменявшись несколькими служебными пакетами), поддерживать (периодически передавать данные, чтобы не наступил таймаут), а затем закрыть (снова обменявшись несколькими служебными пакетами).
Итак, IP определяет адрес компьютера в сети. Но, в силу наличия TCP соединений, пакеты могут принадлежать различным соединениям на одной и той же машине. Для того, чтобы различать соединения, вводится понятие TCP-порт. Это всего лишь пара чисел (одно для отправителя, а другое для получателя) в служебной информации пакета, определяющая, в рамках какого соединения должен рассматриваться пакет. Т.е. адрес соединения на этой машине.
Простейший TCP сервер
Теперь перейдем к практике. Попробуем создать свой собственный TCP-сервер. Для этого нам понадобится модуль socket из стандартной библиотеки Python.
Основная проблема при работе с сокетами у новичков связана с наличием обязательного магического ритуала подготовки сокетов к работе. Но имея за плечами теоретические знания, изложенные выше, кажущаяся магия превращается в осмысленные действия. Также необходимо отметить, что в случае с TCP работа с сокетами на сервере и на клиенте различается. Сервер занимается ожиданием подключений клиентов. Т.е. его IP адрес и TCP порт известны потенциальным клиентам заранее. Клиент может подключиться к серверу, т.е. выступает активной стороной. Сервер же ничего не знает об адресе клиента до момента подключения и не может выступать инициатором соединения. После того, как сервер принимает входящее соединения клиента, на стороне сервера создается еще один сокет, который является симметричным сокету клиента.
Итак, создаем серверный сокет:
# python3 import socket serv_sock = socket.socket(socket.AF_INET, # задамем семейство протоколов 'Интернет' (INET) socket.SOCK_STREAM, # задаем тип передачи данных 'потоковый' (TCP) proto=0) # выбираем протокол 'по умолчанию' для TCP, т.е. IP print(type(serv_sock)) #
А где же обещанные int fd = open(«/path/to/my/socket») ? Дело в том, что системный вызов open() не позволяет передать все необходимые для инициализации сокета параметры, поэтому для сокетов был введен специальный одноименный системный вызов socket() . Python же является объектно-ориентированным языком, в нем вместо функций принято использовать классы и их методы. Код модуля socket является ОО-оберткой вокрут набора системных вызовов для работе с сокетами. Его можно представить себе, как:
class socket: # Да, да, имя класса с маленькой буквы :( def __init__(self, sock_familty, sock_type, proto): self._fd = system_socket(sock_family, sock_type, proto) def write(self, data): # на самом деле вместо write используется send, но об этом ниже system_write(self._fd, data) def fileno(self): return self._fd Т.е. доступ к целочисленному файловому дескриптору можно получить с помощью:
print(serv_sock.fileno()) # 3 или другой int Так мы работаем с серверным сокетом, а в общем случае на серверной машине может быть несколько сетевых адаптеров, нам необходимо привязать созданный сокет к одному из них:
serv_sock.bind(('127.0.0.1', 53210)) # чтобы привязать сразу ко всем, можно использовать '' Вызов bind() заставляет нас указать не только IP адрес, но и порт, на котором сервер будет ожидать (слушать) подключения клиентов.
Далее необходимо явно перевести сокет в состояние ожидания подключения, сообщив об этом операционной системе:
backlog = 10 # Размер очереди входящих подключений, т.н. backlog serv_sock.listen(backlog) После этого вызова операционная система готова принимать подключения от клиентов на этом сокете, хотя наш сервер (т.е. программа) — еще нет. Что же это означает и что такое backlog?
Как мы уже выяснили, взаимодействие по сети происходит с помощью отправки пакетов, а TCP требует установления соединения, т.е. обмена между клиентом и сервером несколькими служебными пакетами, не содержащими реальных бизнес-данных. Каждое TCP соединение обладает состоянием. Упростив, их можно представить себе так:
СОЕДИНЕНИЕ УСТАНАВЛИВАЕТСЯ -> УСТАНОВЛЕНО -> СОЕДИНЕНИЕ ЗАКРЫВАЕТСЯ Таким образом, параметр backlog определяет размер очереди для установленных, но еще не обработанных программой соединений. Пока количество подключенных клиентов меньше, чем этот параметр, операционная система будет автоматически принимать входящие соединения на серверный сокет и помещать их в очередь. Как только количество установленных соединений в очереди достигнет значения backlog, новые соединения приниматься не будут. В зависимости от реализации (GNU Linux/BSD), OC может явно отклонять новые подключения или просто их игнорировать, давая возможность им дождаться освобождения места в очереди.
Теперь необходимо получить соединение из этой очереди:
client_sock, client_addr = serv_sock.accept() В отличие от неблокирующего вызова listen() , который сразу после перевода сокета в слушающее состояние, возвращает управление нашему коду, вызов accept() является блокирующим. Это означает, что он не возвращает управление нашему коду до тех пор, пока в очереди установленных соединений не появится хотя бы одно подключение.
На этом этапе на стороне сервера мы имеем два сокета. Первый, serv_sock , находится в состоянии LISTEN , т.е. принимает входящие соединения. Второй, client_sock , находится в состоянии ESTABLISHED , т.е. готов к приему и передаче данных. Более того, client_sock на стороне сервера и клиенсткий сокет в программе клиента являются одинаковыми и равноправными участниками сетевого взаимодействия, т.н. peer’ы. Они оба могут как принимать и отправлять данные, так и закрыть соединение с помощью вызова close() . При этом они никак не влияют на состояние слушающего сокета.
Пример чтения и записи данных в клиентский сокет:
while True: data = client_sock.recv(1024) if not data: break client_sock.sendall(data) И опять же справедливый вопрос — где обещанные read() и write() ? На самом деле с сокетом можно работать и с помощью этих двух функций, но в общем случае сигнатуры read() и write() не позволяют передать все возможные параметры чтения/записи. Так, например, вызов send() с нулевыми флагами равносилен вызову write() .
Немного коснемся вопроса адресации. Каждый TCP сокет определяется двумя парами чисел: (локальный IP адрес, локальный порт) и (удаленный IP адрес, удаленный порт) . Рассмотрим, какие адреса на данный момент у наших сокетов:
serv_sock: laddr (ip=, port=53210) raddr (ip=0.0.0.0, port=*) # т.е. любой client_sock: laddr (ip=, port=51573) # случайный порт, назначенный системой raddr (ip=, port=53210) # адрес слушающего сокета на сервере Полный код сервера выглядит так:
# python3 import socket serv_sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM, proto=0) serv_sock.bind(('', 53210)) serv_sock.listen(10) while True: # Бесконечно обрабатываем входящие подключения client_sock, client_addr = serv_sock.accept() print('Connected by', client_addr) while True: # Пока клиент не отключился, читаем передаваемые # им данные и отправляем их обратно data = client_sock.recv(1024) if not data: # Клиент отключился break client_sock.sendall(data) client_sock.close() Подключиться к этому серверу можно с использованием консольной утилиты telnet , предназначенной для текстового обмена информацией поверх протокола TCP:
telnet 127.0.0.1 53210 > Trying 192.168.0.1. > Connected to 192.168.0.1. > Escape character is '^]'. > Hello > Hello Простейший TCP клиент
На клиентской стороне работа с сокетами выглядит намного проще. Здесь сокет будет только один и его задача только лишь подключиться к заранее известному IP-адресу и порту сервера, сделав вызов connect() .
# python3 import socket client_sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM) client_sock.connect(('127.0.0.1', 53210)) client_sock.sendall(b'Hello, world') data = client_sock.recv(1024) client_sock.close() print('Received', repr(data)) Заключение
Запоминать что-то без понимания, как это работает — злое зло не самый разумный подход для разработчика. Работа с сокетами тому отличный пример. На первый взгляд может показаться, что уложить в голове последовательность приготовления клиентских и серверных сокетов к работе практически не возможно. Это происходит из-за того, что не сразу понятен смысл производимых манипуляций. Однако, понимая, как осуществляется сетевое взаимодействие, API сокетов сразу становится прозрачным и легко оседает в подкорке. А с точки зрения полезности полученных знаний, я считаю. что понимание принципов сетевого взаимодействия жизненно важно для разработки и отладки действительно сложных веб-проектов.
Другие статьи из серии:
- Пишем свой веб-сервер на Python: процессы, потоки и асинхронный I/O
- Пишем свой веб-сервер на Python: протокол HTTP
- Пишем свой веб-сервер на Python: стандарт WSGI
- Пишем свой веб-сервер на Python: фреймворк Flask
Ссылки по теме
Справочная информация:
Литература
- Beej’s Guide to Network Programming — отличные основы
- UNIX Network Programming — продвинутый уровень
Пишем свой веб-сервер на Python: протокол HTTP
Подпишись на обновления блогa, чтобы не пропустить следующий пост!
Оглавление
- Введение
- Задача HTTP-сервера
- Структура HTTP-сервера
- Пару слов о кодировке
- Стратегия разбора запроса
- Разбор request line
- Разбор заголовков запроса
- Обработка запроса
- Отправка ответа
- Чтение тела запроса
- Повторное использование TCP-соединений
- Заключение
- Ссылки по теме
Введение
На данный момент мы умеем отправлять и принимать данные по сети и организовывать обработку запросов на сервере. Настало время перейти на более высокий уровень — реализовать свой HTTP сервер.
Для начала определимся, что же такое HTTP. Hypertext Transfer Protocol (HTTP) — это протокол прикладного уровня, предназначенный для передачи гипертекстовых данных в распределенных информационных системах. Ух, сложнааа. А на самом деле нет. Давайте разбираться!
Протокол — это не более, чем соглашение между двумя или более участниками некоторого взаимодействия. Когда речь идет о сетевом взаимодействии, протоколы принято условно разделять на уровни. В самом низу находятся протоколы физического уровня, определяющие как данные передаются в физических средах, т.е. по проводам, оптоволокну, и т.п. Знакомые нам из первой части протоколы IP и TCP — это протоколы сетевого и транспортного уровня, соответственно. Они определяют более высокоуровневые детали взаимодействия, в частности, IP отвечает за адресацию компьютеров/узлов в сети, а TCP — за надежную передачу данных произвольной (т.е. в общем случае превышающей размер одного IP-пакета) длины между узлами. HTTP же располагается на самом высоком уровне — прикладном. От нижележащих протоколов HTTP ожидает гарантий надежности доставки данных, а сам концентрируется на определении понятий запросов и ответов (сообщений) и их семантике. Фактически, HTTP является основным протоколом передачи данных в вебе, а сами данные являются гипертекстом, зачастую представленным в формате HTML-страниц.

До версии HTTP/2, появившейся в 2015 году, HTTP был простым текстовым протоколом. Во второй версии протокол претерпел значительные доработки, стал эффективнее и приобрел новые возможности, но в то же время реализация клиентов и серверов усложнилась. На декабрь 2021 только 46.8% сайтов Интернет используют HTTP/2, но наблюдается устойчивый восходящий тренд.
В этой статье мы рассмотрим, как можно реализовать простейший HTTP-сервер на Python. Ради простоты, мы будем работать с версией протокола HTTP/1.1, а код сервера будет скорее служить образовательным целям, нежели являться полнофункциональным веб-сервером.
Задача HTTP-сервера
HTTP-сервер — это (в большинстве случаев) развитие идеи уже хорошо нам известного TCP-сервера. Задача HTTP-сервера — принимать входящие HTTP-запросы от клиентов, обрабатывать их и отправлять HTTP-ответы.
Простейший HTTP-запрос выглядит следующим образом:
GET / HTTP/1.1 Host: example.com То, что мы видим выше — это так называемое сообщение HTTP message. Опуская вопрос кодировки данных, сообщение HTTP/1.1 — это обычный текст, который состоит из строк, разделенных символами CRLF, т.е. \r\n . Первая строка запроса называется request line. Она определяет метод method, цель target и версию протокола. Далее идут заголовки запроса. В ранних версиях протокола секция заголовков могла отсутствовать полностью, но в HTTP/1.1 заголовок Host является обязательным.
Назначение вышеописанных элементов мы рассмотрим чуть позже, а сейчас перейдем к примеру HTTP-ответа:
HTTP/1.1 200 OK HTTP-ответы также представлены сообщениями. Первая строка ответа называется status line. Она состоит из версии, трехзначного кода статуса status-code и опционального текста причины.
Как и в случае с TCP-сервером, для того, чтобы начать обрабатывать HTTP-запросы, наш сервер должен создать слушающий (listening) сокет. На каждое входящее соединение, сервер должен прочитывать текст HTTP-запроса, вызывать соответствующий обработчик, и, получив от него ответ, отсылать данные клиенту. TCP-соединение может быть как завершено непосредственно после отправки ответа, так и сохранено для повторного использования клиентом.
Структура HTTP-сервера
Реализация полнофункционального HTTP/1.1-сервера требует учета всех требований протокола, определенных группой RFC (RFC7230 «Message Syntax and Routing», RFC7231 «Semantics and Content», RFC7232 «Conditional Requests», RFC7233 «Range Requests», RFC7234 «Caching», RFC7235 «Authentication»). Мы же скорее хотим сфокусироваться на самом подходе к реализации. Исходный код в этой статье не готов для боевого использования, и не гарантируется, что его логика строго следует спецификации протокола.
В качестве основы будущего HTTP-сервера мы будем использовать следующий класс:
# python3 import socket import sys class MyHTTPServer: def __init__(self, host, port, server_name): self._host = host self._port = port self._server_name = server_name def serve_forever(self): serv_sock = socket.socket( socket.AF_INET, socket.SOCK_STREAM, proto=0) try: serv_sock.bind((self._host, self._port)) serv_sock.listen() while True: conn, _ = serv_sock.accept() try: self.serve_client(conn) except Exception as e: print('Client serving failed', e) finally: serv_sock.close() def serve_client(self, conn): try: req = self.parse_request(conn) resp = self.handle_request(req) self.send_response(conn, resp) except ConnectionResetError: conn = None except Exception as e: self.send_error(conn, e) if conn: conn.close() def parse_request(self, conn): pass # TODO: implement me def handle_request(self, req): pass # TODO: implement me def send_response(self, conn, resp): pass # TODO: implement me def send_error(self, conn, err): pass # TODO: implement me if __name__ == '__main__': host = sys.argv[1] port = int(sys.argv[2]) name = sys.argv[3] serv = MyHTTPServer(host, port, name) try: serv.serve_forever() except KeyboardInterrupt: pass Код сервера максимально упрощен, чтобы иметь возможность сфокусироваться именно на работе с протоколом HTTP. Обработка запросов происходит синхронно, т.е. возможно обслуживать не более одного клиента в один момент времени. Сервер в бесконечном цикле осуществляет прием входящих соединений, выполняя serv_sock.accept() . Каждое соединение conn является клиентским сокетом. Прием очередного соединения инициирует обработку HTTP-запроса serve_client(conn) . Обработка же заключается в чтении и разборе aka синтаксическом анализе HTTP-запроса parse_request(conn) , непосредственно обработке handle_request(req) и отправке ответа send_response(conn, resp) . В случае же ошибки на любом из этапов, обработка заканчивается отправкой сообщения об ошибке send_error(conn, err) .
Запустить сервер можно, сохранив код в файле server.py и выполнив команду:
python3 server.py 127.0.0.1 53210 example.local Для отправки тестовых HTTP-запросов удобно пользоваться консольной утилитой netcat:
nc localhost 53210 > GET / HTTP/1.1 > Host: example.local > Пару слов о кодировке
В соответствии со спецификацией, одно сообщение HTTP может одновременно содержать данные, представленные в различных кодировках. В то же время, служебные данные, такие как request line, status line и заголовки должны быть преставлены некоторым надмножеством однобайтовой ASCII кодировки, определенном в стандарте ISO/IEC 8859-1. Почему существует такое требование становится очевидно при попытке реализации собственного HTTP-сервера. Как мы уже видели выше, HTTP-запрос — это обычный текст, а текст в компьютерном мире — это последовательность байт плюс дополнительное знание, в какой кодировке эти байты должны быть интерпретированы. Без знания кодировки в общем случае невозможно (и зачастую небезопасно) каким-либо образом интерпретировать текстовые данные, представленные последовательностью байт. Так как никакой предварительной фазы обмена информацией о кодировке в протоколе не предусмотрено, логичным решением является заранее договориться, что все данные по умолчанию передаются в одной и той же кодировке, и такой кодировкой была выбрана ASCII. В таком случае, у сервера всегда существует возможность произвести разбор запроса на составляющие, т.е. отделить request line от блока заголовков, а заголовки друг от друга.
Ограничение ASCII к счастью не распространяется на тело запроса. Имея возможность прочитать заголовки, из них возможно получить информацию о наличии, размере и кодировке тела запроса. Далее сервер должен прочитать заданное количество «сырых» байт из сокета и лишь потом декодировать их в строку с использованием договоренной кодировки (или кодировки по умолчанию).
Если же существует очень большое желании использовать не-ASCII символы в значениях заголовков, то проткол предлагает кодировать данные в MIME, хотя поддержка и использование этой возможности не является широко распространенной практикой.
Стратегия разбора запроса
Разбор запроса состоит из следующих шагов:
- Читаем первую строку, т.е. request line, разбираем ее на метод, цель и версию и сохраняем их в некоторую структуру данных.
- Читаем построчно заголовки, разбираем их на имя и значение и сохраняем в словаре (aka ассоциативном массиве) с именем заголовка в качестве ключа. Индикатором конца секции заголовков служит пустая строка.
- На основе метода и заголовков определяем, содержит ли запрос тело. Если да, поточно читаем байты из соединения до тех пор, пока прочитанное количество не равно ожидаемому размеру тела запроса. Техника чтения может отличаться в зависимости от типа запроса, подробнее см. секцию Чтение тела запроса.
Как было отмечено ранее, чтение строк должно осуществляться с использованием кодировки ISO/IEC 8859-1. Применение других кодировок возможно только к значениям элементов сообщения (т.е. к значениям заголовков или телу запроса).
Разбор request line
В качестве разминки выполним разбор request line, самой первой строки HTTP-запроса. Прежде всего, из соединения необходимо прочитать строку, т.е. последовательность байт, заканчивающуюся комбинацией \r\n . Простейший способ — это читать данные байт за байтом, сохраняя их в некотором буфере, пока не будет найдена необходимая комбинация:
class MyHTTPServer: def parse_request(self, conn): buf = '' while '\r\n' not in buf: byte = conn.recv(1) # возвращает тип bytes buf += str(byte, 'iso-8859-1') # . Однако, такой подход достаточно неэффективен, так как каждый вызов conn.recv() приводит к системному вызову, а значит имеет высокие накладные расходы. К счастью, благодаря широчайшим возможностям стандартной библиотеки Python, сокет предоставляет возможность создать вокруг него некоторую обертку, которая предоставляет file object интерфейс:
MAX_LINE = 64*1024 class MyHTTPServer: def parse_request(self, conn): rfile = conn.makefile('rb') raw = rfile.readline(MAX_LINE + 1) # эффективно читаем строку целиком if len(raw) > MAX_LINE: raise Exception('Request line is too long') req_line = str(raw, 'iso-8859-1') req_line = req_line.rstrip('\r\n') words = req_line.split() # разделяем по пробелу if len(words) != 3: # и ожидаем ровно 3 части raise Exception('Malformed request line') method, target, ver = words if ver != 'HTTP/1.1': raise Exception('Unexpected HTTP version') return Request(method, target, ver, rfile) class Request: def __init__(self, method, target, version, rfile): self.method = method self.target = target self.version = version self.rfile = rfile Так как мы фокусируемся только на версии HTTP/1.1, код разбора получился достаточно коротким и простым. Все, что мы сделали — это прочитали строку из соединения и разбили ее по пробелу на составляющие — метод, цель и версию, сохранив их в структуре Request.
Разбор заголовков запроса
Перейдем к следующему шагу — разбору HTTP-заголовков. Запрос с заголовками выглядит следующим образом:
GET /foo/bar HTTP/1.1 Host: example.local Accept: text/html User-Agent: Mozilla/5.0 # пустая строка выше - индикатор конца блока заголовков Таким образом, необходимо читать строку за строкой, до тех пор, пока не будет встречена первая пустая строка. Выполним небольшой рефакторинг кода нашего сервера, выделив разбор request line и разбор заголовков в отдельные методы:
MAX_HEADERS = 100 class MyHTTPServer: def parse_request(self, conn): rfile = conn.makefile('rb') method, target, ver = self.parse_request_line(rfile) headers = self.parse_headers(rfile) return Request(method, target, ver, headers, rfile) def parse_headers(self, rfile): headers = [] while True: line = rfile.readline(MAX_LINE + 1) if len(line) > MAX_LINE: raise Exception('Header line is too long') if line in (b'\r\n', b'\n', b''): # завершаем чтение заголовков break headers.append(line) if len(headers) > MAX_HEADERS: raise Exception('Too many headers') return headers def parse_request_line(self, rfile): pass # . В результате, мы получили список отдельных заголовков headers вида:
[b'Host: example.local\r\n', b'Accept: text/html\r\n', b'User-Agent: Mozilla/5.0\r\n'] В то же время, мы планировали сохранять заголовки HTTP-сообщений в ассоциативном массиве, где ключами бы являлись ключи заголовков (например, Host, Accept или User-Agent), а значениями — соответствующие значения полей. Одним из вариантов было бы продолжить разбор, разбивая каждый элемент списка по символу : и сохраняя левую часть в качестве ключа, а правую — в качестве значения в некотором dict:
def parse_headers(self, rfile): headers = [] # . read headers lines from rfile hdict = <> for h in headers: h = h.decode('iso-8859-1') k, v = h.split(':', 1) hdict[k] = v return hdict Однако, существует достаточно большое количество частных случаев, которые подход выше не учитывает. Например, в одном сообщении может быть несколько заголовков с одинаковым именем, т.е. в общем случае по ключу в hdict должен находиться скорее список, а не одна строка; значения заголовков могут быть представлены в MIME-кодировке; и пр.
К счастью, формат HTTP-сообщений, как и email-сообщений, следует спецификации Internet Message Format. Стандартная библиотека Python предоставляет модуль email, который в частности может быть использован для разбора HTTP-заголовков. Нам понадобится внести лишь минимальное изменение в метод parse_headers() , чтобы воспользоваться стандартным парсером:
from email.parser import Parser class MyHTTPServer: def parse_headers(self, rfile): headers = [] # . read headers lines from rfile sheaders = b''.join(headers).decode('iso-8859-1') return Parser().parsestr(sheaders) Возвращаемое значение метода Parser.parsestr() — это объект email.message.Message , который напоминает OrderedDict . Ключи в Message — это отсортированные в порядке появления ключи заголовков.
Последнее, что мы сделаем в рамках задачи разбора заголовков — это проверим наличие и соответствие заголовка Host:
class MyHTTPServer: def parse_request(self, conn): # . headers = self.parse_headers(rfile) host = headers.get('Host') if not host: raise Exception('Bad request') if host not in (self._server_name, f':'): raise Exception('Not found') return Request(method, target, ver, headers, rfile) # terminal 1 python3 server.py 127.0.0.1 53210 example.local # terminal 2 nc localhost 53210 > GET / HTTP/1.1 > Host: example.local # terminal 3 nc localhost 53210 > GET / HTTP/1.1 > Host: iximiuz.com Обработка запроса
Настало время заняться непосредственно обработкой HTTP-запросов, т.е. бизнес-логикой нашего сервера. Одной из традиционных задач, выполняемых HTTP-сервером, является отдача статического контента, т.е. файлов и директорий из некоторой корневой директории. Мы же опустим эту функцию и сфокусируемся на кастомной логике приложения.
Представим, что мы хотим создать сервис, который позволяет регистрировать пользователей, получать список ID зарегистрированных пользователей, а также информацию о каждом пользователе по его ID. Опишем API нашего сервиса:
# Создание нового пользователя POST /users?name=Vasya&age=42 # Получение списка пользователей GET /users # Получение профиля пользователя GET /users/123 Дополнительно, в зависимости от заголовка запроса Accept, сервер будет возвращать данные либо в формате HTML, либо JSON.
Прежде, чем приступать непосредственно к обработке, давайте расширим возможности класса Request, чтобы впоследствии код обработки получился чуть более высокоуровневым. Добавим полезные методы path и query , которые будут разбивать цель вида /users?name=Vasya&age=42 на /users и , соответственно:
from functools import lru_cache from urllib.parse import parse_qs, urlparse class Request: def __init__(self, method, target, version, headers, rfile): self.method = method self.target = target self.version = version self.headers = headers self.rfile = rfile @property def path(self): return self.url.path @property @lru_cache(maxsize=None) def query(self): return parse_qs(self.url.query) @property @lru_cache(maxsize=None) def url(self): return urlparse(self.target) Обработка запросов начинается в методе handle_request() . Сам метод занимается скорее диспетчеризацией запросов на основе метода и цели, чем непосредственно обработкой:
from urllib.parse import parse_qs class MyHTTPServer: def __init(self, *args): # . self._users = <> def handle_request(self, req): if req.path == '/users' and req.method == 'POST': return self.handle_post_users(req) if req.path == '/users' and req.method == 'GET': return self.handle_get_users(req) if req.path.startswith('/users/'): user_id = req.path[len('/users/'):] if user_id.isdigit(): return self.handle_get_user(req, user_id) raise Exception('Not found') def handle_post_users(self, req): pass def handle_get_users(self, req): pass def handle_get_user(self, req, user_id): pass Давайте посмотрим на метод создания пользователя handle_post_users() :
class MyHTTPServer: def handle_post_users(self, req): user_id = len(self._users) + 1 self._users[user_id] = return Response(204, 'Created') Все очень просто — на основании данных из запроса создаем новый объект пользователя и сохраняем его на сервере. Ответом на такой запрос является лишь строка статуса HTTP/1.1 204 Created\r\n . Класс Response можно определить следующим образом:
class Response: def __init__(self, status, reason, headers=None, body=None): self.status = status self.reason = reason self.headers = headers self.body = body Следующий функция нашего приложения — это возвращение списка зарегистрированных пользователей handle_get_users() . В данном случае нам понадобится полноценный ответ, содержащий в себе перечисление всех пользователей на сервере. А в качестве дополнительной возможности, наш сервер будет поддерживать два формата данных — text/html и application/json:
-
‘ for u in self._users.values(): body += f’
- # , ‘ body += ‘
Важно обратить внимание на способ представления body . Так как наш ответ содержит символы кириллицы, ASCII кодировка нам не подходит. Мы работаем с body как со строкой в кодировке UTF-8. Однако, прежде чем создать объект ответа, мы кодируем строку в последовательность байт, а заголовок Content-Length, представляющий собой размер ответа, принимает значение длины уже в байтах. Заголовок Content-Type при этом содержит секцию ; charset=utf-8 , по которой клиенты нашего сервера могут определить кодировку тела ответа.
Реализацию последнего метода нашего приложения handle_get_user(user_id) можно посмотреть в полном исходном коде сервера в конце статьи.
Отправка ответа
Последний шаг, отделяющий нас от минимальной рабочей версии — это отправка HTTP-ответов. Код отправки достаточно прост. Прежде всего записываем в соединение status line вида HTTP/1.1 . Затем, построчно записываем заголовки и не забываем пустую строку, обозначающую конец секции заголовков. Все вышеперечисленные данные должны быть представлены в кодировке ISO/IEC 8859-1. При наличии тела ответа, ожидаем, что оно уже представлено последовательностью байт и просто отправляем его в сокет:
class MyHTTPServer: def send_response(self, conn, resp): wfile = conn.makefile('wb') status_line = f'HTTP/1.1 \r\n' wfile.write(status_line.encode('iso-8859-1')) if resp.headers: for (key, value) in resp.headers: header_line = f': \r\n' wfile.write(header_line.encode('iso-8859-1')) wfile.write(b'\r\n') if resp.body: wfile.write(resp.body) wfile.flush() wfile.close() В случае возникновения ошибки на сервере, нам также необходимо отправить ответ. Для этого реализуем метод send_error() , фактически являющийся оберткой вокруг метода send_response() :
class MyHTTPServer: def send_error(self, conn, err): try: status = err.status reason = err.reason body = (err.body or err.reason).encode('utf-8') except: status = 500 reason = b'Internal Server Error' body = b'Internal Server Error' resp = Response(status, reason, [('Content-Length', len(body))], body) self.send_response(conn, resp) Теперь мы можем ввести класс HTTPError(Exception) и заменить в коде сервера вхождения вида raise Exception(‘Not found’) на raise HTTPError(404, ‘Not found’) .
class HTTPError(Exception): def __init__(self, status, reason, body=None): super() self.status = status self.reason = reason self.body = body Запустим наш сервер:
# terminal 1 python3 server.py 127.0.0.1 53210 example.local И протестируем его, создав двух пользователей:
# terminal 2 nc localhost 53210 > POST /users?name=Vasya&age=42 HTTP/1.1 > Host: example.local > < HTTP/1.1 204 Created nc localhost 53210 >POST /users?name=Vasya&age=42 HTTP/1.1 > Host: example.local > < HTTP/1.1 204 Created Теперь попробуем получить информацию о зарегистрированных пользователях - в формате HTML и в формате JSON:
Также попробуем протестировать сообщения об ошибке:
# terminal 2 nc localhost 53210 > GET /users HTTP/1.1 > < HTTP/1.1 400 Bad request < Content-Length: 22 < < Host header is missing nc localhost 53210 >GET /foo HTTP/1.1 > Host: example.local > Accept: application/json > < HTTP/1.1 404 Not found < Content-Length: 9 < < Not found Чтение тела запроса
До настоящего момента, наш сервер не умел работал с телом запроса. Расширим класс Request, добавив тривиальную реализацию метода body() :
class Request: def body(self): size = self.headers.get('Content-Length') if not size: return None return self.rfile.read(size) Если абстрактно представить себе проблему передачи сообщений по сети, то задача чтения одного сообщения может быть непротиворечиво решена только если: сообщения всегда имеют фиксированную длину, сообщения имеют метаинформацию о размере, сообщения разделены некоторым набором символов. В случае протокола HTTP используется подход с передачей метаинформации в заголовоке Content-Length, определяющем длину тела сообщения.
Необходимо заметить, что не все типы запросов могут иметь тело. Например, запросы GET не должны иметь тела сообщения.
Протокол HTTP также предоставляет возможность передачи больших объемов данных, разбивая их на части (т.н. chunk-и). В таком случае добавляется специалльный заголовок Transfer-Encoding: chunked , а тело запроса (или ответа) представляется блоками байт, каждый из которых имеет префикс в виде длины блока. Подробнее тут Chunked transfer encoding.
Повторное использование TCP-соединений
Протокол HTTP поддерживает отправку нескольких последовательных (в версии HTTP2 поддерживается также мультиплексирование) HTTP-запросов в рамках одного TCP-соединения. Несмотря на то, что наш сервер мгновенно закрывает соединение после отправки ответа, поведением по умолчанию для протокола HTTP/1.1 является сохранение соединения открытым для повторного его использования клиентом. Это так называемый механизм HTTP keep-alive. В случае же, если клиент или сервер по каким-либо причинам не хотят реиспользовать соединение, необходимо добавить заголовок Connection: close .
Заключение
Реализованный нами HTTP-сервер объединяет в себе как непосредственно работу с протоколом, так и более высокоуровневую обработку HTTP-запросов, суть - бизнес-логику приложения. Очевидным развитием архитектуры веб-сервера является отделение редко меняющейся протокольной части от специфичной и волатильной бизнес-логики приложения. Более того, формализация программного интерфейса HTTP-сервера в виде некоторого стандарта позволила бы создавать переносимые между серверами приложения, избегая дублирования кода. Не удивительно, что Python-сообщество уже решило эту проблему, введя стандарт взаимодействия сервера и приложения WSGI. В следующей статье мы рассмотрим, что из себя представляет эта спецификация и как на уровне кода можно научить приложение взаимодействовать с любым WSGI-совместимым HTTP-сервером.
Исходный код сервера
-
' for u in self._users.values(): body += f'
- # , ' body += '
Ссылки по теме
- http.server модуль Python Standard Library
- Исходный код http.server на GitHub
- RFC7230 Message Syntax and Routing
- RFC7231 Semantics and Content
- RFC7232 Conditional Requests
- RFC7233 Range Requests
- RFC7234 Caching
- RFC7235 Authentication
Автор Ivan Velichko
Следовать в twitter @iximiuz