Введение в модели и слои бэкэнда Keras
Когда мы с вами рассматривали нейронную сеть для классификации изображений цифр, то самостоятельно создавали полносвязный слой нейронов. Однако, это типовая задача, которая, конечно же, уже реализована в Tensorflowи в ветке:
можно найти множество разных типов слоев для их использования в нейронных сетях. В частности, класс Dense:
как раз и реализует полносвязные слои. Здесь слово Keras – это название официального бэкенда, разработанного для упрощения работы с нейронными сетями в Tensorflow. Мы его с вами уже использовали в курсе «Нейронные сети»:
Здесь его тоже затронем и увидим, как слои и модели, описанные через Keras, можно использовать в Tensorflow.
Создание собственных слоев
Базовым классом для описания слоев в Kerasявляется класс:
который предоставляет некоторые дополнительные удобства при создании слоев. Например, обычной практикой является инициализация переменных при первом обращении к слою. Для этого прописывается специальный метод build, в котором и выполняется начальная инициализация:
class DenseLayer(tf.keras.layers.Layer): def __init__(self, units=1): super().__init__() self.units = units def build(self, input_shape): self.w = self.add_weight(shape=(input_shape[-1], self.units), initializer="random_normal", trainable=True) self.b = self.add_weight(shape=(self.units,), initializer="zeros", trainable=True) def call(self, inputs): return tf.matmul(inputs, self.w) + self.b
Обратите внимание, в методе buid используется метод add_weight() для инициализации переменных в виде тензора заданной формы. Этот метод также появился благодаря базовому классу Layer. Далее, у нас идет метод call(), который вызывается после инициализации переменных и формирует выходное значение слоя в виде тензора. В частности, здесь описана формула для полносвязного слоя НС. При этом, магический метод __call__() переопределять уже не нужно, это сделано в базовом классе и, как раз, благодаря этому, мы имеем возможность использовать новые методы buid() и call().
Далее, можно создать экземпляр этого слоя (класса):
layer1 = DenseLayer(10)
и пропустить через него какой-либо тензор:
y = layer1(tf.constant([[1., 2., 3.]])) print( y )
- layer1.weights – тензор, содержащий все веса слоя;
- layer1.trainable_weights – тензор, содержащий все обучаемые веса слоя;
- layer1.non_trainable_variables – тензор, содержащий все необучаемые веса слоя.
Вложенные слои
Для описания сложных моделей, например, многослойных нейронных сетей, слои можно вкладывать друг в друга. Например, для двухслойной НС удобно задать общий класс для описания модели целиком в виде:
class NeuralNetwork(tf.keras.layers.Layer): def __init__(self): super().__init__() self.layer_1 = DenseLayer(128) self.layer_2 = DenseLayer(10) def call(self, inputs): x = self.layer_1(inputs) x = tf.nn.relu(x) x = self.layer_2(x) x = tf.nn.softmax(x) return x
Мы здесь определили два вложенных слоя layer_1 и layer_2 и функцию call() для обработки входного тензора с помощью этих слоев. В результате, можно создать общую модель НС:
model = NeuralNetwork()
и воспользоваться ей, например, так:
y = model(tf.constant([[1., 2., 3.]])) print( y )
При этом, все параметры вложенных слоев этой общей модели будут автоматически доступны через те же самые свойства: model.weights, model.trainable_variables, model.non_trainable_variables То есть, мы получаем возможность взаимодействовать с моделью как единым целым на более высоком уровне абстракции, что очень удобно при машинном обучении.
Класс tf.keras.Model
- обучать (метод fit());
- сохранять и загружать веса (методы save(), save_weights(), load_weights());
- оценивать и прогнозировать выходные значения (методы evaluate(), predict()),
class NeuralNetwork(tf.keras.Model): …
А все остальное оставить без изменений. Теперь, вместо того, чтобы отдельно прописывать функцию потерь, оптимизатор и метрику, достаточно взывать метод compile() экземпляра класса NeuralNetwork и передать требуемые параметры, например, так:
model.compile(optimizer=tf.optimizers.Adam(learning_rate=0.001), loss=tf.losses.categorical_crossentropy, metrics=['accuracy'])
Смотрите, мы сразу создаем оптимизатор при вызове метода, а в качестве функции потерь передаем ссылку tf.losses.categorical_crossentropy. Этого вполне достаточно, чтобы модель воспользовалась этими параметрами в процессе обучения. Конечно, оптимизатор Adam и категориальная кросс-энтропия – это стандартные параметры, поэтому в Keras для них зарезервированы соответствующие константы и этот же самый метод можно записать и в таком виде:
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Чаще именно таки и делают, если не применяются свои, особенные оптимизаторы или функции потерь.
Обучение модели нейронной сети
Давайте, для примера обучим эту нейросеть распознаванию цифр. Как и ранее, подготовим обучающую и тестовую выборки:
(x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train / 255 x_test = x_test / 255 x_train = tf.reshape(tf.cast(x_train, tf.float32), [-1, 28*28]) x_test = tf.reshape(tf.cast(x_test, tf.float32), [-1, 28*28]) y_train = to_categorical(y_train, 10) y_test_cat = to_categorical(y_test, 10)
И запустим процесс обучения с помощью метода fit():
model.fit(x_train, y_train, batch_size=32, epochs=5)
Смотрите, как API пакета Keras облегчают работу с нейронными сетями. Вместо цикла обучения с разбивкой на мини-батчи, вычислением градиентов и изменением параметров модели, достаточно записать всего одну строчку. В конце программы вызовем метод evaluate() для оценки качества классификации на тестовой выборке:
print( model.evaluate(x_test, y_test_cat) )
После запуска программы увидим похожий результат распознавания, который мы с вами получили на предыдущих занятиях. Только здесь программа получилась гораздо компактнее. Конечно, метод fit() реализует стандартный алгоритм обучения НС и он подходит для многих прикладных задач. Однако, бывают ситуации, когда требуется использовать свой алгоритм обучения НС. И здесь уже приходится опускаться на уровень Tensorflow так, как мы это делали с вами в предыдущих занятиях. Поэтому, при разработке нейронных сетей, полезно уметь работать и с высокоуровневым APIпакета Keras и напрямую с Tensorflow. Хорошая новость здесь в том, что мы легко можем комбинировать оба подхода. Например, описать модель сети на уровне Keras, а обучение провести с помощью Tensorflow. Это относительно частая ситуация, например, при разработке генеративно-состязательных сетей или различных автоэнкодеров. В последующих занятиях мы подробнее рассмотрим возможности пакета Keras, а в заключение этого отмечу несколько полезных возможностей, которые появляются у слоев и моделей уровня Keras.
Методы add_loss() и add_metric()
Предположим, что мы хотим в полносвязном слое DenseLayer дополнительно контролировать величину квадрата весовых коэффициентов и сделать так, чтобы при обучении сети она также учитывалась, то есть, минимизировалась. Для этого в методе call() можно сначала вычислить средний квадрат весовw:
regular = tf.reduce_mean(tf.square(self.w))
а, затем, добавить эту величину в список функций потерь нашей модели:
self.add_loss(regular)
В итоге, при запуске процесса обучения методом fit() общие потери будут определяться суммой двух функций: loss = categorical_crossentropy + regular Соответственно, градиенты будут учитывать уже две функции и обучение сети будет происходить несколько иначе. Чтобы заметить эффект от второй функции, умножим ее на 100:
regular = 100.0 * tf.reduce_mean(tf.square(self.w))
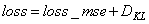
Видим, что качество обучения снизилось с 97% до 92%. То есть, наша дополнительная функция потерь негативно сказалась на результатах обучения. Конечно, это всего лишь простой пример того, как можно гибко настраивать общий вид функции потерь для обучения нейронной сети. В ряде задач это имеет смысл. Например, когда мы с вами проектировали вариационный автоэнкодер на одном из занятий по НС: Курс по нейронным сетям то там результирующая функция потерь, как раз состояла из суммы двух функций (среднего квадрата ошибок и дивергенции Кульбака-Лейблера): В этой задаче вполне можно было бы в модели прописать дивергеницию, а квадрат ошибок задать в виде стандартной функции в методе compile(). Если в процессе обучения нам хотелось бы видеть значения нашей функции потерь (или какую-либо другую метрику), то в том же методе call() можно прописать вызов метода:
self.add_metric(regular, name="mean square weights")
В результате, при обучении, мы увидим дополнительный параметр с указанным именем и вычисленным значением. Это бывает удобно для дополнительного контроля за процессом обучения модели или отдельного слоя. На этом занятии мы сделали шаг от Tensorflow к Keras и увидели, как можно создавать слои и модели с помощью классов Layer и Model. На следующих занятиях мы продолжим знакомиться с основными возможностями API Keras, так как он естественным образом упрощает разработку нейронных сетей на Tensorflow.
Перевод «dense layers» на русский
A conventional nuclear warhead enters the dense layers of the atmosphere at a speed of 5,000 metres per second.
В момент вхождения обычной ядерной боеголовки в плотные слои атмосферы ее скорость равна 5 тысячам метров в секунду.
And for its development, it needs to rise beyond the dense layers of the atmosphere.
А для её развития ему нужно подняться за пределы плотных слоев атмосферы.
This dome is very similar to the spaceship first generation after its release from the dense layers of the atmosphere.
Этот купол очень похож на космический корабль первого поколения после его выхода из плотных слоев атмосферы.
However, in the desert, under dense layers of sand, underground lakes and even seas of freshwater are hidden.
Однако в пустыне под плотными слоями песка скрыты подземные озёра и даже моря пресной воды.
Strongly clamped by dense layers of soil, they are firmly fixed in one position, which guarantees the stability of the whole structure.
Сильно зажатые плотными слоями грунта, они крепко фиксируются в одном положении, что гарантирует устойчивость всей конструкции.
After flying some distance, the rocket will again fall into the dense layers and ricochet again.
Пролетев некоторое расстояние, ракета опять попадет в плотные слои и вновь срикошетирует.
A small in size space body entered dense layers of the atmosphere and burned in them.
«Тело космического происхождения незначительных размеров попало в плотные слои атмосферы и сгорело в них.
Sometimes a stone meteorite collapses during flight through the dense layers of the Earth’s atmosphere, causing a massive explosion.
Иногда каменный метеорит во время полета через плотные слои атмосферы Земли разрушается, вызывая сильнейший взрыв.
Artificial Earth satellites, flying near the border of the dense layers of the atmosphere, moving at a speed of about 8 km/sec.
Искусственные спутники Земли, летающие вблизи границы плотных слоев атмосферы, движутся со скоростью около 8 км/сек.
Soft soils can produce well drilling depth of 100 meters for the day, with dense layers of the soil reducing the rate of 5-10.
Мягкие грунты позволяют произвести бурение скважины глубиной 100 метров за сутки, при этом плотные слои почвы снижают скорость в 5-10 раз.
50% of the fuel missile is used for lifting from the ground and climbing through dense layers of the atmosphere up to 10,000 m.
Обычно около 50 процентов ракетного топлива используется для подъема и преодоления плотных слоев атмосферы на высотах до 10 тысяч метров.
The difficulty in determining the exact location of the fall is that when you enter the dense layers of our atmosphere, the trajectory changes and becomes unpredictable.
Сложность определения точного места падения заключается в том, что при входе в плотные слои нашей атмосферы траектория изменится и станет непредсказуемой.
Maneuvers at altitude give a big range: a missile is pushed against the dense layers of atmosphere like a flat stone against a lake surface.
Манёвры по высоте дают большую дальность: блок отталкивается от плотных слоёв атмосферы, как плоский камень от поверхности озера.
Before entering the dense layers of the atmosphere directly above the target GSLA makes a complex maneuver, making it difficult to intercept by missile defenses.
Перед входом в плотные слои атмосферы непосредственно над целью боеголовка совершает сложный маневр, который затрудняет ее перехват средствами противоракетной обороны.
Seven days after the launch, the spacecraft entered the dense layers of atmosphere and burnt up over The Bay of Guinea.
Спустя семь дней после старта корабль вошел в плотные слои земной атмосферы и сгорел над Гвинейским заливом.
Entry into the dense layers of the atmosphere occurred at 160th circuit over the Central Pacific ocean.
Вход в плотные слои атмосферы произошел на 160-ом витке над центральной частью Тихого океана.
Alas, this attempt also failed, so today the ship begins to enter the dense layers of Earth’s atmosphere, and not pribyvshij in orbit.
Увы, эта попытка тоже провалилась, поэтому уже сегодня корабль начнёт входить в плотные слои атмосферы Земли, так и не прибравшись на орбите.
The device, having entered the dense layers of the atmosphere of Titan, descended by parachute for 2.5 hours.
Аппарат, войдя в плотные слои атмосферы Титана, в течение 2,5 часов спускался на парашюте.
the Shuttle entered the dense layers of the atmosphere.
В 8:44 шаттл вошел в плотные слои атмосферы.
Возможно неприемлемое содержание
Примеры предназначены только для помощи в переводе искомых слов и выражений в различных контекстах. Мы не выбираем и не утверждаем примеры, и они могут содержать неприемлемые слова или идеи. Пожалуйста, сообщайте нам о примерах, которые, на Ваш взгляд, необходимо исправить или удалить. Грубые или разговорные переводы обычно отмечены красным или оранжевым цветом.
Зарегистрируйтесь, чтобы увидеть больше примеров. Это просто и бесплатно
Ничего не найдено для этого значения.
Предложить пример
Больше примеров Предложить пример
Новое: Reverso для Windows
Переводите текст из любого приложения одним щелчком мыши .
Скачать бесплатно
Перевод голосом, функции оффлайн, синонимы, спряжение, обучающие игры
Результатов: 129 . Точных совпадений: 129 . Затраченное время: 95 мс
Помогаем миллионам людей и компаний общаться более эффективно на всех языках.
ML: Тензоры в Keras
Нейронная сеть — это функция $\mathbf’ = F(\mathbf)$, которая преобразует один тензор $\mathbf$ в другой $\mathbf$.
Существует несколько фреймворков (tensorflow, pytourch), которые обеспечивают эффективное вычисление подобных функций, в том числе на GPU. Первоначально синтаксис таких фреймворков был достаточно громоздким, поэтому Франсуа Шолле написал библиотеку в виде библиотеки keras, которая существенно упростила проектирование нейронных сетей. Со временем keras была поглощена Google и теперь развивается только в составе tensorflow версии 2.0 и выше.
На самом деле, фреймворки не только вычисляют функцию $F(\mathbf)$ (прямое распространение), но и решают сложную задачу оптимизации, подбирая параметры функции (обратное распространение ошибки). Тем не менее в этом документе мы сосредоточимся на первой задаче. Понимание того, как происходит вычисление $F(\mathbf)$ на каждом этапе, необходимо для понимания работы сложных архитектур нейронных сетей.
Используемые ниже слои будем импортировать из tensorflow:
from tensorflow.keras.layers import Input, Dense, SimpleRNN, Lambda from tensorflow.keras.layers import Flatten, Dot, Activation
Тензоры в backend
Библиотека keras на нижнем уровне раньше могла работать с тензорами numpy, tensorflow или theano. Поэтому по традиции она оборачивает тензоры в свой собственный класс. Для этого используется окружение backend:
import tensorflow.keras.backend as K
Так как тензоры участвуют в алгоритмах оптимизации, возникает необходимость различать постоянные (constant) и переменные (variable) тензоры:
cnst = K.constant(value = np.array([ [1, 2], [3, 4]]), # numpy массив dtype = 'float32', # тип его элементов name = 'my_cnst') # имя (для ссылок) print( type ( cnst ) ) #> tensorflow.python.framework.ops.EagerTensor print( cnst ) #> tf.Tensor( [[1. 2.] [3. 4.]], shape=(2, 2), dtype=float32)
Так как keras (вне tensorflow) может работать с различными бэкэндами, возвращаемый методом объект может быть, как numpy тензором, так и тензором tensorflow. Поэтому к их свойствам стоит «достукиваться» через функции backend:
print( K.dtype(cnst) ) #> float32 print( K.int_shape(cnst) ) #> (2, 2)
Аналогично для переменных:
var = K.variable(value = np.array([ [1, 2], [3, 4]]), # numpy массив dtype = 'float64', # тип его элементов name = 'my_var') # имя (для ссылок) print( type ( var ) ) #> tensorflow.python.ops.resource_variable_ops.ResourceVariable print( var ) #> tf.Variable 'my_var:0' shape=(2, 2) dtype=float64, #> numpy= array([[1., 2.], [3., 4.]])
С тензорами keras можно обращаться подобно numpy тензорам:
t = K.ones((2, 3)) # матрица 2x3 из единиц t1 = t[:, 0] # первая колонка t2 = t[:, 1] # вторая колонка t3 = K.concatenate([t1, t2]) # их объединение в один вектор print(t1) #> tf.Tensor([1. 1.], shape=(2,), dtype=float32) print(K.eval(t1)) #> [1. 1.] print(K.eval(t3)) #> [1. 1. 1. 1.] type(t1) #> tensorflow.python.framework.ops.EagerTensor
Объекты слоёв
Нейронные сети состоят из соединённых между собой слоёв. Слои являются «элементарными» функциями из которых формируется финальная модель $F(\mathbf)$. Каждый слой является классом. Экземпляр этого класса получает на вход тензор и выдаёт на выход тензор, вообще говоря, другой размерности и формы. У слоёв keras есть две ключевые особенности:
- При обработке тензора не затрагивается его нулевая ось.
- Объявление слоя ещё не приводит к вычислению.
Первая особенность связана с тем, что вычисления выполняются не для одного тензора, а для их набора (батча) размера batch_size. В задачах машинного обучения каждый тензор батча это один пример. При оптимизации параметров модели, ошибка вычисляется по всем примерам батча.
По факту любой слой Layer является элементарной функцией, которая производит вычисления независимо для каждого примера (хотя часто делает это «одновременно» и очень эффективно для всех примеров сразу):
for i in range(x.shape[0]): y[i] = Layer(x[i])
(в numpy запись x[i] для тензора, например, размерности три, означает x[i. ] — i-я матрица пачки).
Вторая особенность связана с тем, что все преобразования с тензорами формируют вычислительный граф. Прямой проход по этому графу приводит к вычислению тензоров (и выхода нейронной сети), а обратный — к вычислению градиентов, необходимых при оптимизации параметров модели.
Слой Activation
Рассмотрим слой Activation, который вычисляет заданную функцию от каждого элемента тензора. Параметров для обучения у слоя нет и форма тензора на выходе совпадает с формой на входе.
Вычислим в numpy, например, гиперболический тангенса от тензора с формы (2,3):
val = np.array([ [1, 0, -1], # val.shape = (2,3) [2, 0, -2]]) y = np.tanh(val)
В библиотеке keras мы должны преобразовать входной numpy-тензор val в keras-тензор x. Затем создаём экземпляр «a» класса слоя Activation и ему передаём входной тензор x. Слой возвращает выходной тензор y:
x = K.variable( val ) # тензор keras из numpy тензора val a = Activation('tanh') # экземпляр объекта Activation y = a(x) # y - тензор после обработки тензора x print( y ) # Tensor("activation_10/Tanh:0", shape=(2,3), dtype=float32) print( K.eval(y) ) # [[ 0.762 0. -0.762] # [ 0.964 0. -0.964]]
Обратим внимание, что числа (собственно вычисления) получаются только после вызова K.eval(y). Эта функция запускает работу вычислительного графа ведущего в узел y.
Создание слоя и получение выходного тензора можно объединить в одной строчке. Например вычислим функцию softmax:
y = Activation('softmax')(x) print(K.eval(y)) # [[0.665 0.245 0.09 ] # [0.867 0.117 0.016]]
Эта функция $e^ Слой Flatten также не имеет параметров для обучения, но меняет форму тензора. Задача этого слоя состоит в преобразовании многомерного входного тензора в одномерный тензор (без учёта оси батча!). На keras эти же вычисления выглядят следующим образом: Слой Dense состоит из units нейронов, соединённых синапсами с элементами входного тензора по его последнему индексу. Пусть размерность этого индекса равна inputs = x.shape[-1]. Обучаемыми параметрами слоя Dense является матрица $\mathbf$ формы (inputs, units) и вектор $\mathbf$ формы (units, ). Слой выполняет линейное преобразование: где многоточие обозначает, вообще говоря, произвольное число индексов, по-мимо обязательного нулевого индекса примеров батча: (batch_size. inputs) (inputs, units) + (units, ). Ниже, в качестве матрицы $\mathbf$, задаётся матрица, состоящая из единиц (если этого не сделать, её элементы будут случайными). При помощи параметра use_bias указывается, что вектор $\mathbf$ нам не нужен: В табличной форме входная матрица $\mathbf$ состоит из двух строк (batch_size=2) и трёх колонок (три признака у каждого из двух примеров). Так как число нейронов равно units=4, матрица весов имеет форму (3, 4): При добавлении вектора смещения (bias) к матрице используется правило расширения (broadcasting). По этому правилу вектор превращается в матрицу (inputs, units) с одинаковыми строчками. Подчеркнём, что размерность входного тензора может быть любой: Матрица в объекте слоя Dense создаётся, когда к нему присоединяется входой тензор (и становится известным размерность его последнего индекса: Таким образом, слой Dense с units нейронами и размерностью inputs последнего индекса входного тензора, имеет (inputs+1)*units параметров, если есть смещение $\mathbf$ и inputs*units, если его нет. Форму тензора слой менят следующим образом: Свёрточный слой Conv2D применяется к "картинкам" высотой rows, шириной cols и имеющих channels "цветовых" каналов. На самом деле графические термины условны и слой Conv2D может применяться не только при обработке изображений. Важно, что входящий в него тензор должен иметь форму: Для определённости будем использовать второй порядок, принятый в keras по умолчанию. Задача слоя Conv2D состоит в обработке "изображения" небольшим фильтром, который по нему скользит. Фильтрация проводится одновременно по всем каналам. Ниже на рисунке картинка (вход x) имеет 3 строки, 4 колонки и 2 канала. Размер ядрa фильтра 2x2 пикселя и 2 в глубину для каналов (3D тензор: голубой кубик). Элементы ядра (определяющие фильтр) перемножаются с соответствующими элементами такого же кубика на картинке (жёлтый цвет). Эти произведения складываются и к ним добавляется смещение bias (ещё один параметр фильтра). Результат вычислений помещается в первый пиксель на выходе y слоя (синий цвет). Затем жёлтый "кубик" сдвигается вправо (по умолчанию на один пиксель) и вычисляется следующее значение выхода. У слоя может быть не один, а несколько фильтров с различными ядрами и смещениями (ниже голубой и салатовый кубики). В этом случае описанные выше вычисления проделываются для каждого фильтра f независимо. Выход слоя будет иметь число каналов (глубину) равное числу фильтров: Рассмотрим пример вычисления свёртки при помощи numpy. Пусть картинка имеет 3 строки, 4 колонки и содержит один канал. Заполним левую её половину единицами ("белый цвет"), а правую - нулями ("чёрный цвет"): Обработаем картинку свёрточным слоем с одним фильтром и ядром размера 2x2 (ниже это будет фильтр выделения вертикального края). Будем считать, что у фильтра смещения нет: Процесс вычисления одного пикселя выхода приведен на рисунке ниже (1*1+0*(-1)+1*1+0*(-1)=2): Теперь выполним эти же вычисления на keras: Таким образом, слой Conv2D с filters фильтрами и формой каждого фильтра kernel_size=(k_rows, k_cols) имеет filters*(k_rows*k_cols + 1) параметров (если есть смещение). Форму тензора слой меняет следующим образом: Если слои со стандартным поведением не подходят, можно воспользоваться слоем Lambda. Этому слою передаётся произвольная lambda-функция меняющая входящий в слой тензор. Единственное ограничение: внутри lambda-функции можно использовать только функции по работе с тензорами из backend. В противном случае keras не сможет вычислить градиент при обратном распространении ошибки. Вычислим, например,сумму компонент входного тензора по axis=1 (второй индекс "признаков"): На слой можно передать несколько тензоров, при помощи их списка. В качестве простого примера, сложим два тензора внутри lambda-функции: В машинном обучении полносвязные (линейные) слои являются одним из важнейших компонентов нейронных сетей. Они называются "плотными" слоями (Dense layer по-английски). Этот слой обрабатывает каждый элемент предыдущего слоя, выполняя матричное перемножение этих элементов со своими весами. Полученные данные затем отправляются на следующий слой. Нейроны полносвязного слоя соединены со всеми нейронами предыдущего слоя, что означает, что каждый нейрон полносвязного слоя может взаимодействовать с любым нейроном предыдущего слоя. Поэтому полносвязные слои очень важны для финальной части нейронных сетей, где они часто используются для классификации данных. В последнее время полносвязные слои также используются для решения других задач, таких как регрессия, сегментация изображений и выделение признаков. Одним из преимуществ полносвязных слоев является их простота и интуитивность: мы можем легко понять, как они работают, и оценить их эффективность, проанализировав их выходные данные. Использование полносвязных слоев в нейронных сетях имеет множество преимуществ. Первое из них - это возможность изучения любой функции, которая может быть представлена в виде математической модели. Нейроны полносвязных слоев могут адаптироваться к любым входным данным, обучаясь выделять важные признаки и игнорировать незначительные. Другое преимущество полносвязных слоев - это их универсальность. Они могут использоваться в различных типах нейронных сетей, включая сверточные нейронные сети, рекуррентные нейронные сети и другие. Также следует отметить, что полносвязные слои очень просты в использовании и реализации. Они могут быть добавлены в модель с помощью нескольких строк кода. Полносвязные слои имеют и некоторые недостатки. Например, если у нас есть много параметров и мало данных, они могут переобучаться. К счастью, эта проблема решается путем использования регуляризации или сверточных слоев. Математически, полносвязный слой может быть описан следующей формулой: y - выходные данные слоя Функция активации может быть различной в зависимости от задачи и выбора алгоритма. Наиболее распространенные функции активации являются ReLU, Sigmoid, и Tanh. Полносвязные слои могут быть программированы в различных библиотеках машинного обучения, таких как TensorFlow, Keras, PyTorch, Theano и другие. Следует учитывать, что способы реализации полносвязных слоев могут немного отличаться в зависимости от используемой библиотеки. Например, в Keras полносвязный слой может быть добавлен в модель с помощью метода model.add(), который принимает аргумент Dense, указывающий на то, что это полносвязный слой. Кроме того, можно указать количество нейронов в слое и функцию активации, используемую в слое. В TensorFlow полносвязные слои можно создать с помощью функции tf.keras.layers.Dense, которая принимает такие же аргументы, как и в Keras. Также можно использовать класс tf.layers.Dense, чтобы создать полносвязные слои непосредственно в TensorFlow. В настоящее время использование полносвязных слоев в нейронных сетях является широко распространенным, и прогнозируется, что в будущем эта технология будет и далее улучшаться и развиваться. В настоящее время в научных кругах активно исследуются новые способы использования полносвязных слоев в нейронных сетях. В том числе повышается их точность, улучшается эффективности обучения и вычислений, а также увеличивается гибкости таких слоев для применения их в различных областях. В будущем полносвязные слои неприменно будут играть важную роль в развитии искусственного интеллекта и машинного обучения.Слой Flatten
На numpy это может выглядеть так:x = np.arange(12) x.shape = (2,2,3) # вход - стопка из двух матриц 2x3 y = x.reshape(x.shape[0], -1) # выход - "стопка" из векторов print(y) # [[ 0 1 2 3 4 5] # [ 6 7 8 9 10 11]]
x = K.arange(12) # тензор keras [0. 11] x = K.reshape(x, (2,2,3)) # меняем его форму f = Flatten() # экземпляр объекта Flatten y = f(x) # y - тензор после обработки тензора x print( x.shape ) #> (2, 2, 3) print( y.shape ) #> (2, 6) print( K.eval(y) ) #> [[ 0 1 2 3 4 5]
Таким образом, слой Flatten следующим образом меняет размерность тензора:
(batch_size, d1,d2. dn) => (batch_size, d1*d2*. *dn)
Полносвязный слой Dense
x = K.reshape(K.arange(6, dtype="float32"), (2,3)) W = np.ones((3,4)) d = Dense(units=4, weights = [W], use_bias = False) y = d(x) K.eval(y) # вычисление произведения
x = K.ones((2,3,4,5)) y = Dense(8)(x) print(y.shape) # (2, 3, 4, 8)
d = Dense(1) print( d.weights ) #> [] x = K.ones((2,3)) y = d(x) print(d.weights) #> [[-1.132], [ 0.808], [-0.135]]
(batch_size, d1,d2. dn, inputs) => (batch_size, d1,d2. dn, units)
Свёрточный слой Conv2D
x.shape = (batch_size, channels, rows, cols) если data_format = "channels_first" x.shape = (batch_size, rows, cols, channels) если data_format = "channels_last" (по умолч.)
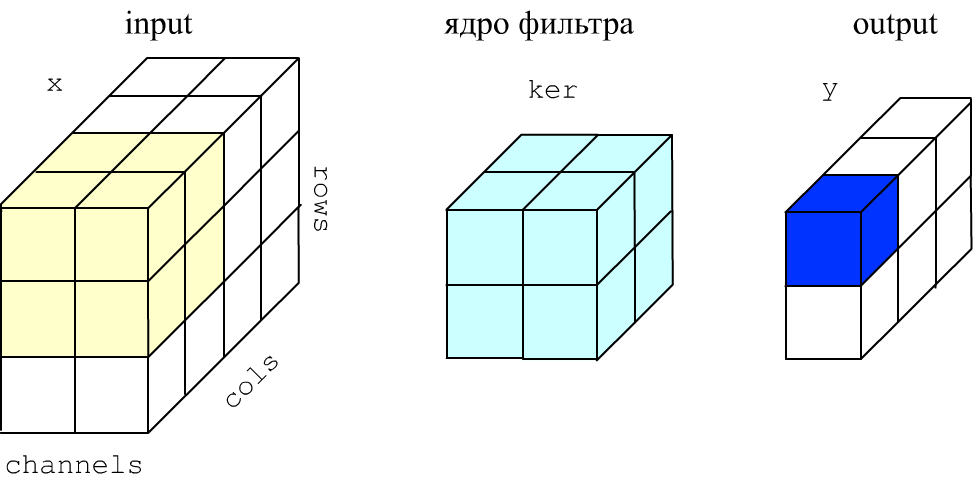
y[s, r, c, f] = np.sum( x[s, r:r+h, r:c+w, :] * ker[:, :, :, f] ) + bias[f].
Свёртка на numpy и keras
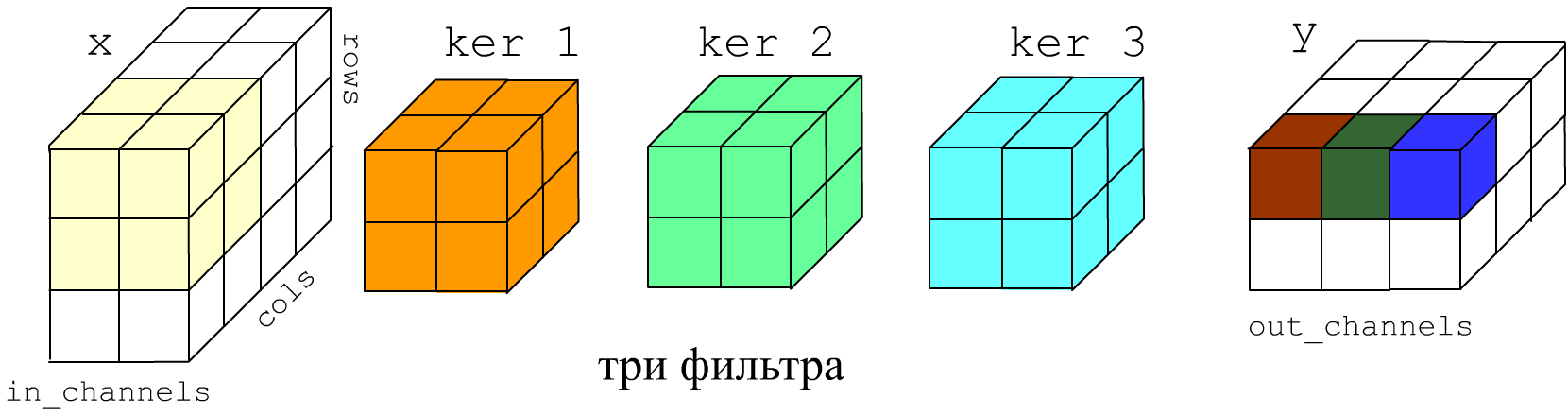
channels, filters = 1, 1 # один канал, один фильтр x_rows, x_cols = 3, 4 # размер картинки на входе im = np.ones((x_rows, x_cols), dtype = 'float32') # левая половина картинки "белая" im[:, 2:] = 0 # а правая половина - "чёрная"
k_rows, k_cols = 2, 2 # размер ядра y_rows = x_rows-k_rows+1 # размер картинки на выходе y_cols = x_cols-k_cols+1 # (фильтр смещается на один пиксель) x = im.reshape( (1, x_rows, x_cols, channels) ) # вход y = np.empty ( (1, y_rows, y_cols, filters ) ) # выход ker = np.array( [ 1,-1, 1,-1 ] ) # ядро фильтра ker.shape = (k_rows, k_cols, channels, filters) # выделения вертикального края for r in range(y_rows): # проведение свёртки for c in range(y_cols): y[0,r,c,0] = np.sum( x[0, r:r+k_rows, c:c+k_cols, :] * ker[ :, :, :, 0] )
x = K.variable(value = im.reshape( (1, x_rows, x_cols, channels) )) con = Conv2D(filters = 1, kernel_size = (k_rows, k_cols), use_bias = False, weights = [ker] ) print(x.shape,"=>", y.shape) #> (1, 3, 4, 1) => (1, 2, 3, 1) print(K.eval(y).reshape(-1)) #> [0, 2, 0, # 0, 2, 0]
(batch_size, x_rows, x_cols, channels) => (batch_size, y_rows, y_cols, filters)
Универсальный слой Lambda
x = K.variable(value = np.array([[1,2,3], [4,5,6]]) ) lm = Lambda(lambda t: K.sum(t,axis=1)) y = lm(x) print( K.eval(y) ) #> [ 6. 15.]
x1 = K.variable(value = np.array([[1,2,3], [4,5,6]]) ) x2 = K.variable(value = np.array([[7,8,9], [1,2,3]]) ) lm = Lambda(lambda lst: lst[0]+lst[1]) y = lm([x1,x2]) print( K.eval(y) ) #> [[ 8. 10. 12.] # [ 5. 7. 9.]]
Полносвязные слои нейронных сетей в машинном обучении
Таким образом, полносвязный слой является необходимым инструментом в создании моделей нейронных сетей, так как он позволяет выполнять обработку всех элементов предыдущего слоя и выдавать результат в форме одного вектора, который может быть использован в дальнейшем для обучения или классификации.
x - входные данные (вектор), полученные из предыдущего слоя
W - матрица весов, которая соединяет входные и выходные данные
b - вектор сдвига, который добавляется к выходным данным
activation - функция активации, которая применяется к выходным данным, чтобы добавить нелинейность.