Tpu процессор что это
ЦП против ГП против ТПУ
По сути, ЦП, ГП и ТПУ различаются тем, что ЦП — это процессор, работающий как мозг компьютера, идеально подходящий для программирования общего назначения.
Напротив, GPU — это ускоритель производительности, улучшающий рабочие нагрузки компьютерной графики и ИИ. В то время как TPU — это специально разработанные процессоры Google, которые ускоряют рабочие нагрузки машинного обучения с использованием (конкретной платформы машинного обучения) TensorFlow.
Что такое центральный процессор?
Центральный процессор (CPU) — это основной процессор, который существует во всех ваших интеллектуальных устройствах.
ЦП — это процессор общего назначения, разработанный с несколькими мощными ядрами и большой кэш-памятью, что позволяет ему одновременно запускать несколько программных потоков. Процессор подобен дирижеру в оркестре, он управляет всеми остальными компонентами от памяти до графической карты, выполняя множество функций обработки для системы.
ЦП имеет по крайней мере одно вычислительное ядро, но со временем он развивался, чтобы включать в себя все больше и больше ядер. Наличие нескольких ядер позволяет ЦП выполнять многопоточность — которая позволяет ЦП одновременно выполнять несколько операция на одном ядре.
Что такое графический процессор?

GPU (графический процессор) — это специализированный процессор, который работает как ускоритель производительности вместе с CPU. По сравнению с центральным процессором, графический процессор имеет тысячи ядер, которые могут разбивать сложные задачи на тысячи или миллионы отдельных задач и решать их параллельно. Параллельные вычисления используют тысячи ядер графического процессора для оптимизации различных приложений, включая обработку графики, рендеринг видео, машинное обучение и даже майнинг криптовалют, таких как биткойн. За последнее десятилетие графические процессоры стали незаменимыми для разработки глубокого обучения. Благодаря способности ускорять большие матричные операции и выполнять матричные вычисления смешанной точности за одну операцию, графические процессоры могут ускорить глубокое обучение с высокой скоростью. Эта технология параллельных вычислений делает GPU важнейшей частью современных суперкомпьютеров, вызвавших всемирный бум ИИ.
Центральный процессор против графического (наглядный пример)
Что такое ТПУ?
TPU обозначают Tensor Processing Units, которые представляют собой специализированные интегральные схемы (ASIC). TPU были разработаны Google. Они начали использовать TPU в 2015 году и сделали их общедоступными в 2018 году.
TPU минимизируют время достижения точности при обучении больших и сложных моделей нейронных сетей. Благодаря TPU модели глубокого обучения, на обучение которым раньше уходили недели на GPU, теперь на TPU занимают всего несколько часов.
Почему TPU так хорошо подходят для глубинного обучения?

Тензорный процессор третьего поколения

Тензорный процессор Google — интегральная схема специального назначения (ASIC), разработанная с нуля компанией Google для выполнения задач по машинному обучению. Он работает в нескольких основных продуктах Google, включая Translate, Photos, Search Assistant и Gmail. Облачный TPU обеспечивает преимущества, связанные с масштабируемостью и лёгкостью использования, всем разработчикам и специалистам по изучению данных, запускающим передовые модели машинного обучения в облаке Google. На конференции Google Next ‘18 мы объявили о том, что Cloud TPU v2 теперь доступен для всех пользователей, включая бесплатные пробные учётные записи, а Cloud TPU v3 доступен для альфа-тестирования.
Но многие спрашивают – какая разница между CPU, GPU и TPU? Мы сделали демонстрационный сайт, где расположена презентация и анимация, отвечающая на этот вопрос. В этом посте я хотел бы подробнее остановиться на определённых особенностях содержимого этого сайта.
Как работают нейросети
Перед тем, как начать сравнивать CPU, GPU и TPU, посмотрим, какого рода вычисления требуются для машинного обучения – а конкретно, для нейросетей.
Представьте, к примеру, что мы используем однослойную нейросеть для распознавания рукописных цифр, как показано на следующей диаграмме:
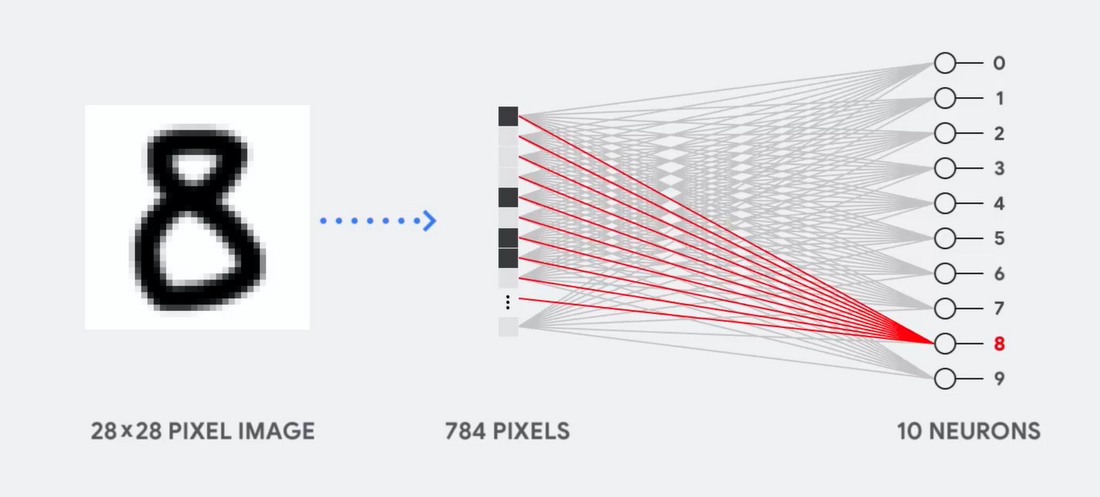
Если картинка будет сеткой размером 28х28 пикселей серой шкалы, её можно преобразовать в вектор из 784 значений (измерений). Нейрон, распознающий цифру 8, принимает эти значения и перемножает их со значениями параметра (красные линии на диаграмме).
Параметр работает как фильтр, извлекая особенности данных, говорящих о схожести изображения и формы 8:
Это наиболее простое объяснение классификации данных нейросетями. Перемножение данных с соответствующими им параметрами (окраска точек) и их сложение (сумма точек справа). Наивысший результат обозначает наилучшее совпадение введённых данных и соответствующего параметра, которое, скорее всего, и будет правильным ответом.
Проще говоря, нейросетям требуется делать огромное количество перемножений и сложений данных и параметров. Часто мы организовываем их в виде матричного перемножения, c которым вы могли столкнуться в школе на алгебре. Поэтому проблема состоит в том, чтобы выполнить большое количество матричных перемножений как можно быстрее, потратив как можно меньше энергии.
Как работает CPU
Как подходит к такой задаче CPU? CPU – процессор общего назначения, основанный на архитектуре фон Неймана. Это значит, что CPU работает с ПО и памятью как-то так:
Главное преимущество CPU – гибкость. Благодаря архитектуре фон Неймана, вы можете загружать совершенно разное ПО для миллионов различных целей. CPU можно использовать для обработки текстов, управления ракетными двигателями, выполнения банковских транзакций, классификации изображений при помощи нейросети.
Но поскольку CPU такой гибкий, оборудование не всегда знает заранее, какой будет следующая операция, пока не прочтёт следующую инструкцию от ПО. CPU нужно хранить результаты каждого вычисления в памяти, расположенной внутри CPU (так называемые регистры, или L1-кэш). Доступ к этой памяти становится минусом архитектуры CPU, известным как узкое место архитектуры фон Неймана. И хотя огромное количество вычислений для нейросетей делает предсказуемым будущие шаги, каждое арифметико-логическое устройство CPU (ALU, компонент, хранящий и управляющий множителями и сумматорами) выполняет операции последовательно, каждый раз обращаясь к памяти, что ограничивает общую пропускную способность и потребляет значительное количество энергии.
Как работает GPU
Для увеличения пропускной способности по сравнению с CPU, GPU использует простую стратегию: почему бы не встроить в процессор тысячи ALU? В современном GPU содержится порядка 2500 – 5000 ALU на процессоре, что делает возможным выполнение тысяч умножений и сложений одновременно.
Такая архитектура хорошо работает с приложениями, требующими массивного распараллеливания, такими, например, как умножение матриц в нейросети. При типичной тренировочной нагрузке глубинного обучения (ГО) пропускная способность в этом случае увеличивается на порядок по сравнению с CPU. Поэтому на сегодняшний день GPU является наиболее популярной архитектурой процессоров для ГО.
Но GPU всё равно остаётся процессором общего назначения, который должен поддерживать миллион различных приложений и ПО. А это возвращает нас к фундаментальной проблеме узкого места архитектуры фон Неймана. Для каждого вычисления в тысячах ALU, GPU необходимо обратиться к регистрам или разделяемой памяти, чтобы прочесть и сохранить промежуточные результаты вычислений. Поскольку GPU выполняет больше параллельных вычислений на тысячах своих ALU, он также тратит пропорционально больше энергии на доступ к памяти и занимает большую площадь.
Как работает TPU
Когда мы в Google разрабатывали TPU, мы построили архитектуру, предназначенную для определённой задачи. Вместо разработки процессора общего назначения, мы разработали матричный процессор, специализированный для работы с нейросетями. TPU не сможет работать с текстовым процессором, управлять ракетными двигателями или выполнять банковские транзакции, но он может обрабатывать огромное количество умножений и сложений для нейросетей с невероятной скоростью, потребляя при этом гораздо меньше энергии и умещаясь в меньшем физическом объёме.
Главное, что позволяет ему это делать – радикальное устранение узкого места архитектуры фон Неймана. Поскольку основной задачей TPU является обработка матриц, разработчикам схемы были знакомы все необходимые шаги вычислений. Поэтому они смогли разместит тысячи множителей и сумматоров, и соединить их физически, сформировав большую физическую матрицу. Это называется архитектурой конвейерного массива. В случае с Cloud TPU v2 используются два конвейерных массива по 128 х 128, что в сумме даёт 32 768 ALU для 16-битных значений с плавающей точкой на одном процессоре.
Посмотрим, как конвейерный массив выполняет подсчёты для нейросети. Сначала TPU загружает параметры из памяти в матрицу множителей и сумматоров.
Затем TPU загружает данные из памяти. По выполнению каждого умножения результат передаётся следующим множителям, при одновременном выполнении сложений. Поэтому на выходе будет сумма всех умножений данных и параметров. В течение всего процесса объёмных вычислений и передачи данных доступ к памяти совершенно не нужен.
Поэтому TPU демонстрирует большую пропускную способность при подсчётах для нейросетей, потребляя гораздо меньше энергии и занимая меньше места.
Преимущество: уменьшение стоимости в 5 раз
Какие же преимущества даёт архитектура TPU? Стоимость. Вот стоимость работы Cloud TPU v2 на август 2018 года, на время написания статьи:
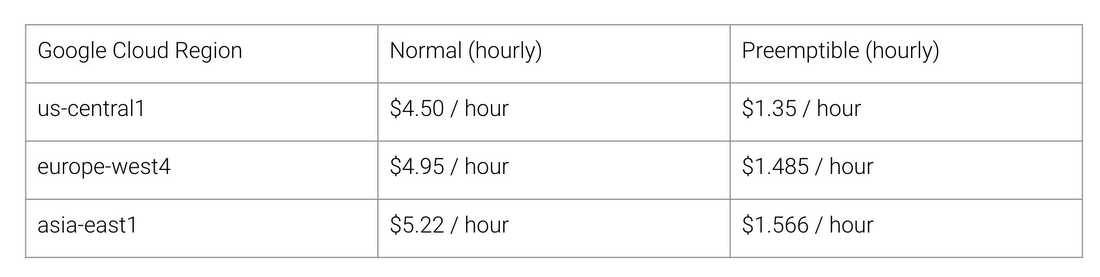
Обычная и TPU-шная стоимость работы для разных регионов Google Cloud
Стэнфордский университет раздаёт набор тестов DAWNBench, измеряющих быстродействие систем с глубинным обучением. Там можно посмотреть на различные комбинации задач, моделей и вычислительных платформ, а также на соответствующие результаты тестов.
На момент завершения соревнования в апреле 2018 минимальная стоимость тренировки на процессорах с архитектурой, отличной от TPU, равнялась $72,40 (для тренировки ResNet-50 с 93% точностью на ImageNet на спотовых инстансах). При помощи Cloud TPU v2 такую тренировку можно провести за $12,87. Это меньше 1/5 стоимости. Такова сила архитектуры, предназначенной специально для нейросетей.
- Облачные вычисления
- Google Cloud Platform
- Искусственный интеллект
Специальны е чип ы ASUS — «двойные интеллектуальные процессоры».

Специальный чип TPU , установленный на материнской плате, обеспечивает аппаратную поддержку разгона системы с помощью функций Auto Tuning и TurboV . Энтузиасты могут разогнать свою систему как с помощью специальной копки или переключателя на плате, так и с помощью интерфейса AI Suite II. Контроллер TPU обеспечивает тонкую настройку параметров разгона и расширенные средства мониторинга работы системы с использованием функций Auto Tuning и TurboV. Функция Auto Tuning включает режим динамического разгона до высокого, но абсолютно стабильного уровня, а TurboV дает пользователю бесконечную свободу в настройке параметров работы процессора для достижения нужной производительности в различных ситуациях.
EPU — энергетический процессор от ASUS
Специальный энергетический процессор от ASUS автоматически определяет степень загрузки системы и оптимизирует ее энергопотребление в режиме реального времени. Это способствует уменьшению шума от вентиляторов и долгому сроку службы компонентов компьютера. Этот первый в мире энергетический процессор создан для экономии потребления энергии и задействуется с помощью переключателя на плате или с помощью утилиты AI Suite II. Он оптимизирует энергопотребление, выполняя мониторинг загрузки в режиме реального времени и регулируя параметры электропитания компонентов платы согласно текущим потребностям. Помимо этого, благодаря EPU повышается долговечность системных компонентов и снижается уровень генерируемого компьютером шума.

Рис. 1. Микросхемы TPU и EPU на материнской плате.
В настоящее время существует две версии EPU Engine — EPU-4 и EPU-6. Отличие заключается в количестве компонентов ПК, подконтрольных энергосберегающему процессору EPU. EPU-4 поддерживает четыре компонента — центральный процессор, видеокарту, жёсткий диск и кулер. EPU-6 в дополнение к этому набору регулирует работу чипсета и оперативной памяти. Оперировать с технологией EPU мы можем при помощи фирменной утилиты ASUS EPU. Обычно эта программа даёт нам 3 режима работы — автоматический, скоростной и энергосберегающий – если материнская плата оснащена EPU-4 (в EPU-6 будет присутствовать ещё два промежуточных режима — турбо и умеренное энергосбережение).
Тензорные процессоры (TPU) как альтернатива NVIDIA. Инструкция по применению для разработчиков
Меня зовут Иван Жарский, я ведущий ML-разработчик компании Statanly Technologies.
В 2022 году основной производитель видеокарт GPU и библиотек по их использованию NVIDIA приостановил продажи видеокарт в Россию. В 2023 году компании не могут легально купить продукцию NVIDIA. Даже если получится приобрести видеокарту по параллельному импорту, в случае поломки владелец не получит техподдержки.
Я расскажу, как наша компания нашла альтернативу графическим процессорам (GPU) от NVIDIA для машинного обучения, чем тензорные процессоры (TPU) отличаются от графических и как адаптировать модель ИИ для работы на TPU.

Компания Statanly Technologies занимается разработкой готовых решений и моделей искусственного интеллекта. Одна из основных областей разработки — это компьютерное зрение (computer vision, CV) .
Область CV включает в себя задачи, связанные с анализом изображений и видео. Чаще всего это классификация изображений. Например, отличать собак от кошек или машины скорой помощи от пожарных и полицейских. Эти задачи относительно несложные, поскольку классов всего два (кошки и собаки) и много данных.
Еще одной задачей является детекция и сегментация объектов — например, определить местоположение человека на камере или вырезать машину из картинки. Иногда нужно со всех ракурсов определять марку и модель машины, даже по фотографиям отдельных деталей. Тогда в каждом классе получается большое разнообразие объектов, и это усложняет задачу. Если классов очень много и требуется высокая точность, то необходимы еще более тяжеловесные модели.
Для решения этих задач нужны датасеты — размеченные наборы данных, на которых будет учиться модель искусственного интеллекта. Чем больше данных, тем лучше качество модели. После успешного обучения модель можно выводить в продакшен.
Основные задачи продакшена — чтобы все работало качественно и быстро. Достичь обеих целей сложно, поэтому требуется компромисс.
Сколько памяти нужно моделям ИИ для работы и обучения
В области CV суперлегкие модели имеют до 5 млн параметров, легкие — от 5 до 10 млн, средние — от 10 до 50 млн, тяжелые — от 50 до 100 млн, супертяжелые — от 100 млн. Для сложных задач, в которых на вход приходят очень разнообразные данные, подходят тяжелые модели, которые выдают топовое качество и имеют внутри очень много настраиваемых обучаемых параметров. При этом они потребляют много памяти и работают очень долго. Это в большей степени справедливо для текстовых моделей, например GPT — GPT-3, BERT. В области CV это относится к современным генеративным моделям — например, диффузионным моделям Stable Diffusion и DALL-E, и к классификаторам, основанным на архитектуре «трансформер», — например, Vision Transformer и Swin Transformer.
Важно отметить, что количество потребляемой памяти определяет не только сама модель, но и размер входа — количество данных, которое должен обработать алгоритм. Для текстовых моделей это размер текста, для классификаторов изображений — размер картинки.
В свою очередь размер входа влияет на общий требуемый объем оперативной памяти и количество данных, которые мы зараз подаем в модель, — батч (batch size).
Для примера возьмем очень крупную модель ResNeXt101, предназначенную для классификации изображений. На ней картинка со стандартным для этой модели входом 224 на 224 и batch size 32 занимает 2 ГБ оперативной памяти на тестировании. Если мы запускаем 10 таких классификаторов, каждый из которых отвечает за какую-то свою задачу, нужно уже 20 ГБ оперативной памяти GPU.
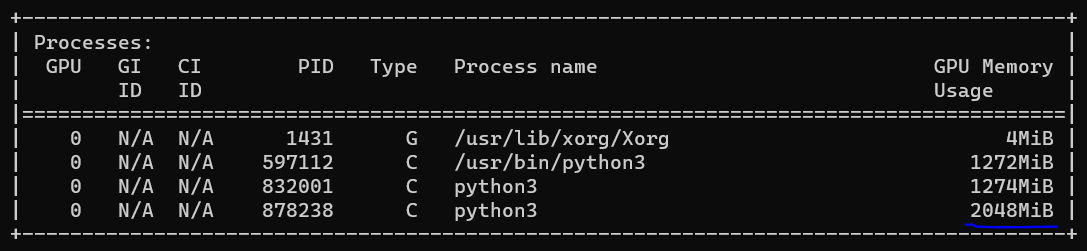
Скриншот запуска ResNeXt101 на тестировании. Модель занимает 2 ГБ оперативной памяти
Для запуска в режиме тестирования ResNeXt101 нужны 2 ГБ, но для обучения модели ИИ размер необходимой памяти увеличивается в несколько раз. В случае ResNeXt101 — в 8 раз, то есть до 16 ГБ. Так происходит потому, что во время обучения модели также нужно хранить граф вычислений и считать производные (градиенты), с помощью которых обновляются параметры (веса) нейронной сети.
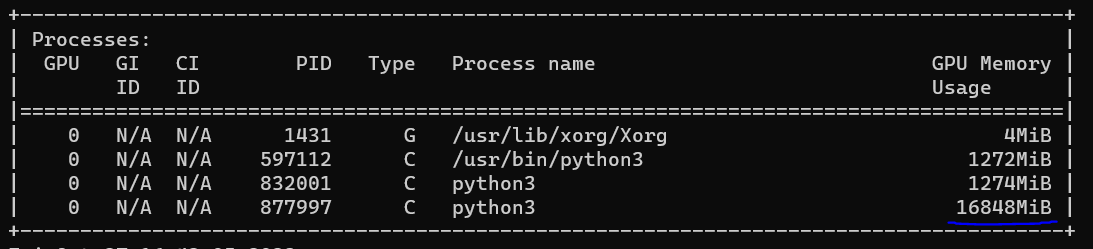
Скриншот запуска ResNeXt101 на обучении. Модель занимает 16 ГБ оперативной памяти
Модель обучается так: через нее проходит наш вход, а мы считаем градиенты, чтобы с помощью градиентного спуска обновлять веса модели — числа, которые были подобраны при обучении. Поэтому дорогие видеокарточки с большим количеством памяти нужны в большей степени для обучения крупных моделей, а затем для запуска на них разных моделей и сервисов.
Также бывают легковесные модели, которые показывают качество пониже, но зато работают очень быстро и не так сильно нагружают систему.
Как тип процессора влияет на работу моделей ИИ
Однако не только выбор модели влияет на скорость работы, но и используемое железо, причем порой даже гораздо больше. Исторически взлет машинного обучения произошел благодаря тому, что люди научились запускать модели машинного обучения на видеокартах (GPU).
Почему так? На самом деле ML-модели внутри себя выполняют на каждый входной объект примерно от 10⁶ до 10⁹ матричных операций, которые на обычном процессоре (CPU) выполняются довольно медленно, так как CPU изначально разрабатываются как универсальные и гибкие инструменты вычислений.
GPU, в отличие от универсальных CPU, изначально проектировались для обработки многомерных изображений, для которой как раз нужны матричные вычисления. Они исполняются с помощью вычислительных блоков, которых в GPU гораздо больше, чем в CPU. Таким образом, нейронные сети довольно успешно можно запускать на GPU.
Важные параметры для машинного обучения — размер оперативной видеопамяти и в целом производительность процессора GPU. Крупные ML-модели требуют много видеопамяти. Например, карта RTX 3090 имеет 24 ГБ оперативной памяти и производительность: 35,58 TFLOPS. Это немало, но эта карточка является одной из топовых и стоит от 120 000 ₽.
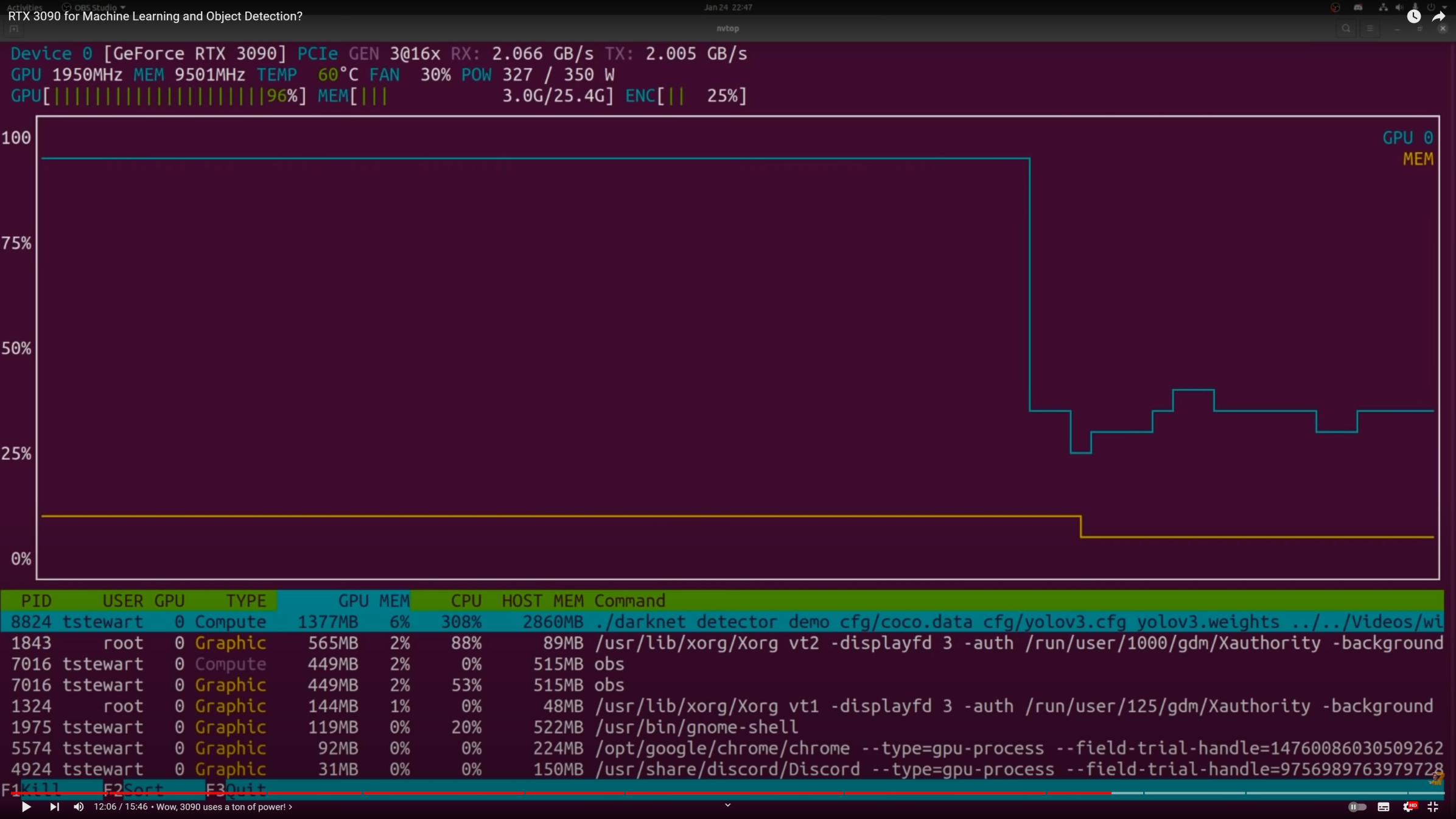
Определение объектов на ранее записанном видео (доступно по ссылке: https://youtu.be/mDUa5sY4Jeo?t=726). При этом видеокарта RTX 3090 была загружена на 96%
TPU как альтернатива CPU и GPU
Помимо CPU и GPU, еще есть TPU — тензорные процессоры, которые разработаны специально для максимально эффективного запуска нейронных сетей. При этом они, к сожалению, не умеют ничего другого.
Изначально TPU — это разработка Google, предназначенная для фреймворка машинного обучения TensorFlow. Однако Google не продает своих решений напрямую. Компания всего лишь предоставляет облачный доступ к TPU-серверам по подписке, к которой у россиян нет доступа.
Несмотря на это, свойства облачных решений можно воспроизвести и на физических устройствах. Например, отказоустойчивость облачных решений можно воспроизвести, если купить несколько TPU-серверов.
Мы выбрали в качестве аналога NVIDIA TPU-серверы SOPHON, разработанные в Китае, из-за опыта и профессиональных достижений производителя.
Сравниваем характеристики GPU и китайских TPU
Производительность
Заявляемая производительность устройства SOPHON AI Micro Server SE8-192 — 96 TFLOPS. При этом она рассчитана для вычислений с весами в виде чисел формата float32. Но есть способ еще сильнее ускорить вычисления — использовать числа формата int8. В таком случае производительность вырастет до 192 TOPS.
Особенности конкретных моделей TPU
Приведу пример того, как TPU заточены под работу с нейросетями. Мы разрабатываем для Краснодара систему видеоаналитики и поиска злоумышленников «Умный город», для которой создаем много моделей. Систему еще не выпустили в продакшен, поэтому точно сказать не можем, что нам хватит одного сервера на 192 TOPS SOPHON AI Micro Server SE8-192.
Но есть надежда на это, потому что этот TPU имеет дополнительные вычислительные блоки по декодированию видео и изображений. В результате он умеет обрабатывать 192 видеоканала, то есть можно обслуживать 192 камеры в режиме реального времени.
При этом в обычных GPU гораздо меньше декодеров, поэтому они умеют обрабатывать меньше потоков. RTX 3090 с производительностью 35,58 TFLOPS не умеет обрабатывать 36 каналов.
Цена
Стоимость TPU в целом ниже, чем игровых и серверных GPU. Например, сейчас топовая серверная видеокарта Tesla H100 стоит 4 000 000 ₽.
Более или менее аналогичный TPU стоит чуть более 1 000 000 ₽ и заточен больше под видеоаналитику — то, что нам нужно больше всего для проекта «Умный город».
Сложности в работе с TPU
Когда мы начали работать с TPU, то столкнулись со сложностями.
Не хватает информации и библиотек
Основная сложность с использованием китайских TPU — малое количество доступной информации для разработки ввиду того, что используется новая иностранная технология. Китайцы предоставляют минимальные библиотеки для запуска моделей на TPU , однако они очень низкоуровневые и не позволяют бесплатно адаптировать решение, которое изначально написано для GPU. Поэтому мы создаем свои более удобные библиотеки-обертки на основе китайских.
Перевод чисел float32 в int8, чтобы повысить производительность модели ИИ
Обычно нейронные сети производят вычисления с 32-битными числами в формате float32, но с небольшими потерями в качестве можно обрезать эти числа и получить float16, int8 или даже int4.
Перевод чисел нужен, потому что менее битными числами можно быстрее проводить вычисления и они занимают меньше памяти. При этом чем больше мы обрезаем числа, тем сильнее проседает качество.
Если мы заранее знаем, что будем квантизировать модель, стоит использовать Quantization Aware Training (QAT) — обучение, при котором мы включаем ошибку квантования. Сейчас это наиболее предпочтительный метод для уменьшения потери качества.
Для перехода из float32 в int8 нам нужно подобрать калибровочный датасет, с помощью которого модель подстраивает веса в формате int8, чтобы на этих картинках или текстах из калибровочного датасета получались нормальные результаты. То есть это дополнительная доработка моделей. После этого уже получается квантизованная модель, потому что она была перекомпилирована из float32 в int8.
Важно, чтобы калибровочный датасет был максимально приближен к реальности. Допустим, если мы хотим классифицировать автомобили, а данные приходят с камеры видеонаблюдения, то в калибровочном датасете должны быть картинки желательно с этих камер. Автомобили с выставок для калибровочного датасета в этом случае не подойдут.
Фотографии должны быть мутными и блеклыми, как на обычных камерах видеонаблюдения. Если цель — также получать приемлемый результат на нечетких фотографиях, то они должны быть включены в набор вместе с качественными изображениями.
При этом надо понимать: если в основном данные приходят в виде незашумленных картинок, то качество их анализа просядет, когда мы добавим в набор мутные изображения. В этом случае результат будет лучше, если не включать в набор зашумленные картинки и оставить только изображения хорошего качества.
При обучении датасет тоже должен отражать реальный мир, но калибровочному датасету нужно в еще большей степени соответствовать реальности, иначе модель очень сильно просядет в точности.
Модели, разработанные для GPU, не запускаются на TPU
Китайские библиотеки предоставляют нам низкоуровневые методы для запуска модели. В основном они все написаны на языке C++, а мы разрабатываем модели машинного обучения на Python с помощью фреймворка PyTorch. Чтобы не переписывать весь код на С++, мы решили, что будет удобнее и проще написать обертки над функциями, которые предоставляются китайскими библиотеками.
Мы изучаем документацию, которую предоставили китайцы. Пытаемся понять, какие функции есть, что они принимают на вход, что делают и что отдают. На основании этой информации пишем обертки на Python с помощью специальных фреймворков , которые связывают Python с С++.