ORM — отвратительный анти-паттерн
От автора перевода: Написанный далее текст может не совпадать с мнением автора перевода. Все высказывания идут от лица оригинального автора, просьба воздержаться от неоправданных минусов. Оригинальная статья выпущена в 2014 году, поэтому некоторые фрагменты кода могут быть устаревшими или «нежелаемыми».
Вступление
ORM — это ужасный анти-паттерн, который нарушает все принципы объектно-ориентированного программирования, разбирая объекты на части и превращая их в тупые и пассивные пакеты данных. Нет никаких оправданий существованию ORM в любом приложении, будь то небольшое веб-приложение или система корпоративного размера с тысячами таблиц и манипуляциями CRUD с ними. Какова альтернатива? Объекты, говорящие на языке SQL (SQL-speaking objects).
Как работают ORM
Object-relational mapping (ORM) — это способ (он же шаблон проектирования) доступа к реляционной базе данных с помощью объектно-ориентированного языка (например, Java). Существует несколько реализаций ORM почти на каждом языке, например: Hibernate для Java, ActiveRecord для Ruby on Rails, Doctrine для PHP и SQLAlchemy для Python. В Java ORM даже стандартизирован как JPA.
Во-первых, рассмотрим на примере как работает ORM. Давайте использовать Java, PostgreSQL и Hibernate. Допустим, у нас есть единственная таблица в базе данных, называемая post:
+-----+------------+--------------------------+ | id | date | title | +-----+------------+--------------------------+ | 9 | 10/24/2014 | How to cook a sandwich | | 13 | 11/03/2014 | My favorite movies | | 27 | 11/17/2014 | How much I love my job | +-----+------------+--------------------------+Теперь мы хотим манипулировать этой таблицей CRUD-методами из нашего Java-приложения (CRUD расшифровывается как create, read, update и delete). Для начала мы должны создать класс Post (извините, что он такой длинный, но это лучшее, что я могу сделать):
@Entity @Table(name = "post") public class Post < private int id; private Date date; private String title; @Id @GeneratedValue public int getId() < return this.id; >@Temporal(TemporalType.TIMESTAMP) public Date getDate() < return this.date; >public String getTitle() < return this.title; >public void setDate(Date when) < this.date = when; >public void setTitle(String txt) < this.title = txt; >>Перед любой операцией с Hibernate мы должны создать SessionFactory:
SessionFactory factory = new AnnotationConfiguration() .configure() .addAnnotatedClass(Post.class) .buildSessionFactory();Эта фабрика будет выдавать нам “сеансы” каждый раз, когда мы захотим работать с объектами Post. Каждая манипуляция с сеансом должна быть заключена в этот блок кода:
Session session = factory.openSession(); try < Transaction txn = session.beginTransaction(); // your manipulations with the ORM, see below txn.commit(); >catch (HibernateException ex) < txn.rollback(); >finally
Когда сеанс будет готов, вот так мы получаем список всех записей из этой таблицы:
List posts = session.createQuery("FROM Post").list(); for (Post post : (List) posts)
Я думаю, вам ясно, что здесь происходит. Hibernate — это большой, мощный движок, который устанавливает соединение с базой данных, выполняет необходимые SELECT запросы и извлекает данные. Затем он создает экземпляры класса Post и заполняет их данными. Когда объект приходит к нам, он заполняется данными, и чтобы получить доступ к ним, необходимо использовать геттеры, как пример getTitle() выше.
Когда мы хотим выполнить обратную операцию и отправить объект в базу данных, мы делаем все то же самое, но в обратном порядке. Мы создаем экземпляр класса Post, заполняем его данными и просим Hibernate сохранить его:
Post post = new Post(); post.setDate(new Date()); post.setTitle("How to cook an omelette"); session.save(post);Так работает почти каждая ORM. Основной принцип всегда один и тот же — объекты ORM представляют собой немощные/анемичные (прямой перевод слова anemic) оболочки с данными. Мы разговариваем с ORM фреймворком, а фреймворк разговаривает с базой данных. Объекты только помогают нам отправлять запросы в ORM framework и понимать его ответ. Кроме геттеров и сеттеров, у объектов нет других методов. Они даже не знают, из какой базы данных они пришли.
Вот как работает object-relational mapping.
Что в этом плохого, спросите вы? Все!
Что не так с ORM?
Серьезно, что не так? Hibernate уже более 10 лет является одной из самых популярных библиотек Java. Почти каждое приложение в мире с интенсивным использованием SQL использует его. В каждом руководстве по Java будет упоминаться Hibernate (или, возможно, какой-либо другой ORM, такой как TopLink или OpenJPA) для приложения, подключенного к базе данных. Это стандарт де-факто, и все же я говорю, что это неправильно? Да.
Я утверждаю, что вся идея, лежащая в основе ORM, неверна. Его изобретение было, возможно, второй большой ошибкой в ООП после NULL reference.
ORM, вместо того чтобы инкапсулировать взаимодействие с базой данных внутри объекта, извлекает его, буквально разрывая на части прочный и сплоченный живой организм.
На самом деле, я не единственный, кто говорит что-то подобное, и определенно не первый. Многое на эту тему уже опубликовано очень уважаемыми авторами, в том числе OrmHate автора Martin Fowler (не против ORM, но в любом случае стоит упомянуть), Object-Relational Mapping is the Vietnam of Computer Science от Jeff Atwood, The Vietnam of Computer Science автора Ted Neward, ORM Is an Anti-Pattern от Laurie Voss и многие другие.
Однако мои аргументы отличаются от того, что они говорят. Несмотря на то, что их доводы практичны и обоснованны, например, “ORM работает медленно” или “обновление базы данных затруднено”, они упускают главное. Вы можете увидеть очень хороший, практический ответ на эти практические аргументы, от Bozhidar Bozhanov в его блоге ORM Haters Don’t Get It.
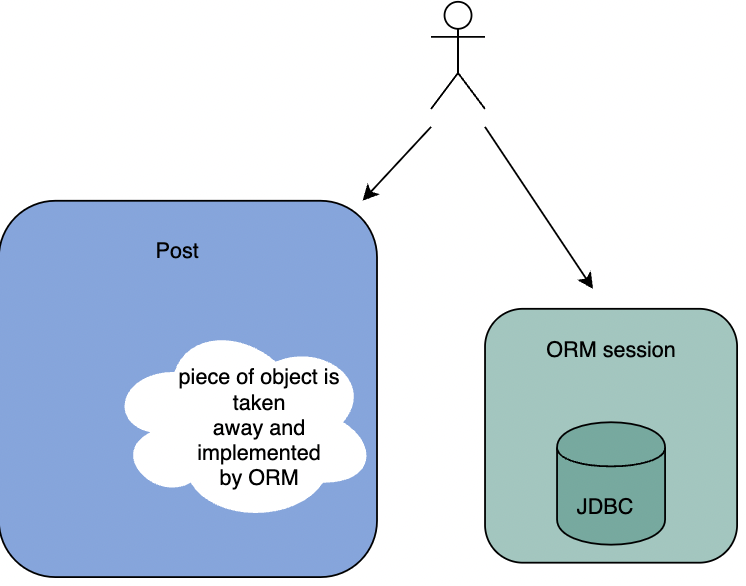
Суть в том, что ORM вместо того, чтобы инкапсулировать взаимодействие с базой данных внутри объекта, извлекает его, буквально разрывая на части прочный и сплоченный живой организм. Одна часть объекта хранит данные, в то время как другая, реализованная внутри механизма ORM ( sessionFactory ), знает, как обращаться с этими данными, и передает их в реляционную базу данных. Посмотрите на эту картинку; она иллюстрирует, что делает ORM.
Я, будучи читателем сообщений, должен иметь дело с двумя компонентами: 1) ORM и 2) возвращенный мне объект “ob-truncated”. Предполагается, что поведение, с которым я взаимодействую, должно предоставляться через единую точку входа, которая является объектом в ООП. В случае ORM я получаю такое поведение через две точки входа — механизм ORM и “предмет”, который мы даже не можем назвать объектом.
Из-за этого ужасного и оскорбительного нарушения объектно-ориентированной парадигмы у нас есть много практических проблем, уже упомянутых в уважаемых публикациях. Я могу добавить еще только несколько.
SQL Не Скрыт. Пользователи ORM должны говорить на SQL (или его диалекте, например, HQL). Смотрите пример выше; мы вызываем session.CreateQuery(«FROM Post») , чтобы получить все сообщения. Несмотря на то, что это не SQL, он очень похож на него. Таким образом, реляционная модель не инкапсулируется внутри объектов. Вместо этого он доступен для всего приложения. Каждому, с каждым объектом, неизбежно приходится иметь дело с реляционной моделью, чтобы что-то получить или сохранить. Таким образом, ORM не скрывает и не переносит SQL, а загрязняет им все приложение.
Трудно протестировать. Когда какой-либо объект работает со списком записей, ему необходимо иметь дело с экземпляром SessionFactory . Как мы можем замокать эту зависимость? Мы должны создать имитацию этого? Насколько сложна эта задача? Посмотрите на приведенный выше код, и вы поймете, насколько подробным и громоздким будет этот модульный тест. Вместо этого мы можем написать интеграционные тесты и подключить все приложение к тестовой версии PostgreSQL. В этом случае нет необходимости имитировать SessionFactory , но такие тесты будут довольно медленными, и, что еще более важно, наши объекты, не имеющие ничего общего с базой данных, будут протестированы на экземпляре базы данных. Ужасный замысел.
Позвольте мне еще раз повторить. Практические проблемы ORM — это всего лишь последствия. Фундаментальный недостаток заключается в том, что ORM разрывает объекты на части, ужасно и оскорбительно нарушая саму идею того, что такое объект.
SQL-speaking объекты

Какова альтернатива? Позвольте мне показать вам это на примере. Давайте попробуем спроектировать класс Post. Нам придется разбить его на два класса: Post и Posts , единственное и множественное число. Я уже упоминал в одной из своих предыдущих статей, что хороший объект — это всегда абстракция реальной сущности. Вот как этот принцип работает на практике. У нас есть две сущности: таблица базы данных и строка таблицы. Вот почему мы создадим два класса. Posts будет представлять таблицу, а Post будет представлять строку.
Как я также упоминал в этой статье, каждый объект должен работать по контракту и реализовывать интерфейс. Давайте начнем наш дизайн с двух интерфейсов. Конечно, наши объекты будут неизменяемыми. Вот как будут выглядеть Posts :
interface Posts < Iterableiterate(); Post add(Date date, String title); >Вот как будет выглядеть один Post :
interface Post
Вот так мы будем перечислять все записи в таблице базы данных:
Posts posts = // we'll discuss this right now for (Post post : posts.iterate())
Вот так создаётся новый Post :
Posts posts = // we'll discuss this right now posts.add(new Date(), "How to cook an omelette");Как вы видите, теперь у нас есть настоящие объекты. Они отвечают за все операции, и они прекрасно скрывают детали их реализации. Нет никаких транзакций, сеансов или фабрик. Мы даже не знаем, действительно ли эти объекты взаимодействуют с PostgreSQL или они хранят все данные в текстовых файлах. Все, что нам нужно от Posts — это возможность перечислить все записи для нас и создать новую. Детали реализации идеально скрыты внутри. Теперь давайте посмотрим, как мы можем реализовать эти два класса.
Я собираюсь использовать jcabi-jdbc в качестве оболочки JDBC, но вы можете использовать что-то другое, например jOOQ, или просто JDBC, если хотите. На самом деле это не имеет значения. Важно то, что ваши взаимодействия с базой данных скрыты внутри объектов. Давайте начнем с Posts и реализуем его в классе PgPosts (“pg” означает PostgreSQL):
final class PgPosts implements Posts < private final Source dbase; public PgPosts(DataSource data) < this.dbase = data; >public Iterable iterate() < return new JdbcSession(this.dbase) .sql("SELECT id FROM post") .select( new ListOutcome( new ListOutcome.Mapping() < @Override public Post map(final ResultSet rset) < return new PgPost( this.dbase, rset.getInt(1) ); >> ) ); > public Post add(Date date, String title) < return new PgPost( this.dbase, new JdbcSession(this.dbase) .sql("INSERT INTO post (date, title) VALUES (?, ?)") .set(new Utc(date)) .set(title) .insert(new SingleOutcome(Integer.class)) ); > >Далее давайте реализуем интерфейс Post в классе PgPost :
final class PgPost implements Post < private final Source dbase; private final int number; public PgPost(DataSource data, int id) < this.dbase = data; this.number = id; >public int id() < return this.number; >public Date date() < return new JdbcSession(this.dbase) .sql("SELECT date FROM post WHERE .set(this.number) .select(new SingleOutcome(Utc.class)); > public String title() < return new JdbcSession(this.dbase) .sql("SELECT title FROM post WHERE .set(this.number) .select(new SingleOutcome(String.class)); > >Вот как будет выглядеть сценарий полного взаимодействия с базой данных с использованием только что созданных нами классов:
Posts posts = new PgPosts(dbase); for (Post post : posts.iterate()) < System.out.println("Title: " + post.title()); >Post post = posts.add( new Date(), "How to cook an omelette" ); System.out.println("Just added post #" + post.id());Вы можете увидеть полный практический пример здесь. Это веб—приложение с открытым исходным кодом, которое работает с PostgreSQL, используя точный подход, описанный выше, — объекты, говорящие на SQL.
Как насчет производительности?
Я слышу, как вы спрашиваете: “А как же производительность?” В этом сценарии, приведенном несколькими строками выше, мы совершаем множество избыточных обходов базы данных. Сначала мы извлекаем идентификаторы записей с помощью SELECT id , а затем, чтобы получить их заголовки, мы выполняем дополнительный вызов SELECT title для каждой записи. Это неэффективно или, проще говоря, слишком медленно.
Не беспокойтесь, это объектно-ориентированное программирование, а это значит, что оно гибкое! Давайте создадим декоратор PgPost , который будет принимать все данные в своем конструкторе и кэшировать их внутри навсегда:
final class ConstPost implements Post < private final Post origin; private final Date dte; private final String ttl; public ConstPost(Post post, Date date, String title) < this.origin = post; this.dte = date; this.ttl = title; >public int id() < return this.origin.id(); >public Date date() < return this.dte; >public String title() < return this.ttl; >>Обратите внимание: этот декоратор ничего не знает о PostgreSQL или JDBC. Он просто декорирует объект типа Post и предварительно кэширует дату и заголовок. Как обычно, этот декоратор также неизменяем.
Теперь давайте создадим другую реализацию Posts , которая будет возвращать “постоянные” объекты:
final class ConstPgPosts implements Posts < // . public Iterableiterate() < return new JdbcSession(this.dbase) .sql("SELECT * FROM post") .select( new ListOutcome( new ListOutcome.Mapping() < @Override public Post map(final ResultSet rset) < return new ConstPost( new PgPost( ConstPgPosts.this.dbase, rset.getInt(1) ), Utc.getTimestamp(rset, 2), rset.getString(3) ); >> ) ); > >Теперь все записи, возвращаемые iterate() этого нового класса, предварительно снабжены датами и заголовками, полученными за одно обращение к базе данных.
Используя декораторы и несколько реализаций одного и того же интерфейса, вы можете создать любую функциональность, которую пожелаете. Что наиболее важно, так это то, что, хотя функциональность расширяется, сложность дизайна не возрастает, потому что классы не увеличиваются в размерах. Вместо этого мы вводим новые классы, которые остаются сплоченными и прочными, потому что они маленькие.
Что касается транзакций
Каждый объект должен иметь дело со своими собственными транзакциями и инкапсулировать их так же, как запросы SELECT или INSERT . Это приведет к вложенным транзакциям, что вполне нормально при условии, что сервер базы данных их поддерживает. Если такой поддержки нет, создайте объект транзакции для всего сеанса, который будет принимать “вызываемый” класс. Например:
final class Txn < private final DataSource dbase; public T call(Callable callable) < JdbcSession session = new JdbcSession(this.dbase); try < session.sql("START TRANSACTION").exec(); T result = callable.call(); session.sql("COMMIT").exec(); return result; >catch (Exception ex) < session.sql("ROLLBACK").exec(); throw ex; >> >Затем, когда вы хотите обернуть несколько манипуляций с объектами в одну транзакцию, сделайте это следующим образом:
new Txn(dbase).call( new Callable() < @Override public Integer call() < Posts posts = new PgPosts(dbase); Post post = posts.add( new Date(), "How to cook an omelette" ); post.comments().post("This is my first comment!"); return post.id(); >> );Этот код создаст новую запись и опубликует комментарий к ней. Если один из вызовов завершится неудачей, вся транзакция будет откачена.
Мне этот подход кажется объектно-ориентированным. Я называю это “объектами, говорящими на SQL”, потому что они знают, как разговаривать на SQL с сервером базы данных. Это их мастерство, идеально заключенное в их границах.
Spring
Spring — это фреймворк с открытым исходным кодом для языка программирования Java. Он был создан для упрощения разработки и поддержки масштабируемых, слабосвязанных и повторно используемых приложений. Фреймворк нужен, чтобы разработчикам было легче проектировать и создавать приложения. Spring не связан с конкретной парадигмой или моделью программирования, поэтому его могут использовать как каркас для разных видов приложений.

Освойте профессию «Java-разработчик»
Чаще всего Spring используется в крупных корпоративных проектах: это характерно для Java и связанных с ним инструментов. Но благодаря универсальности применять Spring можно и в других случаях. Его задача — дать разработчикам больше свободы в проектировании и реализации.
Spring — открытый бесплатный проект, просмотреть его исходный код может любой желающий. Он написан на Java, Kotlin и Groovy, поэтому в теории может использоваться с любым из этих языков. На практике Spring чаще всего применяют с Java. Название читается как «Спринг».
Профессия / 14 месяцев
Java-разработчик
Освойте востребованный язык

История создания Spring Framework
Spring был разработан компанией Pivotal Software и впервые выпущен в 2002 году.
История создания Spring началась в 2001 году, когда Pivotal стала работать над проектом под названием Sprinkler — это была система управления контентом для веб-сайтов. В то время команда разработчиков состояла из четырех человек: Роя Филдинга, Марка Стеббинса, Дейва Буша и Саймона Кокса.
В процессе работы над проектом команда столкнулась с рядом проблем, связанных с необходимостью написания большого количества кода для реализации базовых функций, таких как управление транзакциями, обработка исключений, внедрение зависимостей и т.д. Это привело к тому, что команда приняла решение создать фреймворк для упрощения и стандартизации разработки веб-приложений.
Так и началась разработка Spring. Название Spring было выбрано из-за его простоты и ассоциации с весной — временем обновления и роста.
Первый релиз Spring был выпущен в апреле 2002 года. Он содержал в себе несколько основных компонентов, включая механизм внедрения зависимостей, поддержку аспектов AOP и интеграцию с Hibernate ORM.
Кто пользуется Spring
- Java-разработчики, которые занимаются созданием десктопных, мобильных или веб-приложений, — Spring можно использовать в любом из направлений. Чаще всего речь идет о проектах enterprise-масштаба.
- Kotlin-разработчики, так как этот язык написан на основе Java и использовался для создания Spring.
- Системные архитекторы и инженеры, основная задача которых — проектировать будущие проекты. Spring можно использовать как каркас, шаблон для приложения, поэтому он важен в проектировании и анализе.
- Иногда — бэкенд-разработчики, так как в некоторых случаях серверная часть сайта может быть написана на Java.
Для чего нужен Spring
- Для более быстрого и легкого создания приложений — набор инструментов фреймворка позволяет выполнять те же задачи с меньшим количеством затрат, чем при написании с нуля.
- Для архитектурной «гибкости»: Spring универсален, поэтому позволяет реализовать нестандартные решения.
- Для гибкого использования возможностей — к проекту можно подключать разнообразные модули и тем самым настраивать инструментарий под свои нужды.
- Для удобного построения зависимостей, благодаря которому разработчики могут сконцентрироваться на логике приложения, а не на том, как подключить одно к другому.
- Для реализации парадигмы аспектно-ориентированного программирования, о котором мы подробнее расскажем ниже.
- Для решения задач, связанных со связями между компонентами или разными приложениями, для доступа различных частей системы друг к другу и многого другого.
Принципы Spring
Универсальность. Spring иногда называют платформой: он действительно предлагает разработчикам как бы фундамент, на основе которого можно реализовать приложение. Основная философия — универсальность. Это отличает Spring от других похожих фреймворков.
Облегченность. Второй важный принцип — минимальное воздействие, благодаря которому Spring называют облегченным. Это относится не к размеру фреймворка, а к концепции использования. Благодаря подходу задачи можно реализовать с меньшим количеством кода и минимальной зависимостью от фреймворка.
Поддержка инфраструктуры. На русскоязычном сайте Spring фреймворк сравнивают с водопроводом: основное внимание в нем уделено настройке зависимостей и связей между технологиями. В фреймворке реализован подход IoC, Inversion of Control — инверсия контроля, принцип, который облегчает зависимости между компонентами. Функциональность помогает поддерживать инфраструктуру внутри проекта.
Перед началом работы проект нужно сконфигурировать — указать, какие модули фреймворка к нему подключить и какие технологии использовать . В зависимости от конфигурации разработчику доступны те или иные инструменты.
Как устроен фреймворк
Spring — модульный, то есть состоит из множества компонентов, мини-фреймворков. Компоненты (модули) иногда называют фреймворками во фреймворке. Опишем основные — те, которые обеспечивают фреймворку функциональность.
IoC. Выше мы говорили про зависимости и инверсию контроля. Модуль, который управляет ей, считается основным в фреймворке. Это контейнер, которому делегировано управление зависимостями и конфигурирование разных компонентов. Он пользуется технологией, которая называется Dependency lnjection — инъекция зависимостей. При инверсии контроля создание зависимостей выносится за пределы создания самого объекта — вместо этого они создаются в специальном методе или конструкторе в зависимости от выбранного подхода.
Модуль АОП. АОП — аббревиатура аспектно-ориентированного программирования, парадигмы, для которой и нужен модуль. Чаще всего ее используют в Java и похожих языках.

Станьте Java-разработчиком
и создавайте сложные сервисы
на востребованном языке
Java — язык с сильным упором на объектно-ориентированное программирование. Но возможностей ООП не всегда достаточно — существуют задачи, для которых подход не оптимален. Это сквозная функциональность — функциональность, которую невозможно выделить в отдельные сущности с помощью ООП. В итоге ее реализация разбрасывается по разным объектно-ориентированным сущностям, код становится сложнее и запутаннее.
АОП нужно, чтобы облегчить поддержку сквозной функциональности. Эта парадигма позволяет описать ее отдельно и выделить в самостоятельную сущность. Но методы, которые при этом используются, лежат за пределами ООП и потому требуют отдельной реализации. В Spring за эту реализацию отвечает соответствующий модуль.
Модуль доступа к данным. Эта часть фреймворка отвечает за взаимодействие с СУБД — системами управления базами данных. С помощью модуля Spring можно «связать» логику на Java с управлением базой, настроить доступ к ней разных частей кода. Например, если в приложении выполнится скрипт, которому потребуется информация из базы данных, он сможет к ней обратиться. Задача Spring — в организации грамотного и безопасного доступа.
Для доступа к данным в Spring используется стандарт JDBC, или Java DataBase Connectivity — соединение с базой данных на Java. База соединяется с приложением по уникальному URL с помощью особых сущностей — драйверов.
Кроме этого стандарта, Spring поддерживает ORM — Object-Relational Mapping, или объектно-реляционное отображение. Так называется технология, которая «связывает» реляционные базы данных с сущностями ООП. Spring может работать со всеми основными реализациями ORM.
Модуль транзакций. Транзакция — это последовательность запросов к базе данных, собранная в единый блок. Spring позволяет управлять транзакциями и координировать их, чтобы работа была прозрачной и безопасной. Функциональность фреймворка включает в себя возможность работать с локальными, глобальными и вложенными транзакциями, использовать для них точки сохранения и многое другое. Он поддерживает и абстракции — они нужны для некоторых форматов данных в базе.
Модуль MVC. MVC — это популярная схема приложения, при которой оно как бы разделяется на три основных части: модель данных, отображение и контроллер. Модель представляет собой данные, с которыми работает приложение, отображение отвечает за интерфейс и общение с пользователем, а контроллер — это логика изменения модели в ответ на действия пользователя. Чаще всего схему используют для веб-приложений.
В Spring есть собственная функциональность для реализации MVC. Изначально разработчики ее не планировали, но добавили, когда оказалось, что альтернативные реализации не очень хорошо решают поставленные задачи. Особенности модуля MVC для Spring — прозрачное и четкое разделение между слоями, возможность быстро заменить один интерфейс на другой, привязка функциональности к конкретному интерфейсу. При создании приложений по схеме MVC можно пользоваться не только одноименным модулем, но и другими инструментами Spring.
Модуль авторизации и аутентификации. В нем собраны инструменты, отвечающие за авторизацию и аутентификацию пользователя в системе. В коммерческой разработке в этой области сейчас огромное количество возможных решений, и Spring позволяет работать с большинством современных протоколов и процессов. Этот модуль тесно связан с другой разработкой — Spring Security, отдельным фреймворком на базе Spring. Он позволяет создавать сложные механизмы аутентификации и авторизации, рассчитанные в том числе на масштабные корпоративные Spring-проекты. Spring Security официально включен в Spring как дочерняя разработка.
Другие модули и возможности. Как уже говорилось, модулей в Spring несколько десятков. Кроме описанных выше, стоит упомянуть еще несколько:
- организация удаленного доступа, при котором сущности языка Java передаются через сеть по специальным протоколам и технологиям. Благодаря возможности приложение может вызвать функцию или сервис, которые хранятся на другом сервере, — это важно для больших проектов;
- модуль удаленного управления — это не то же самое, что удаленный доступ. Удаленное управление помогает настраивать и конфигурировать Java-объекты, даже находящиеся на других серверах;
- модуль работы с сообщениями помогает организовать отправку, получение и чтение системных сообщений. Сообщения — способ разных Java-приложений «общаться» друг с другом;
- модуль для тестирования содержит классы и методы для автоматизированного тестирования кода.
Дочерние фреймворки. Мы намеренно отделили их от модулей: хотя дочерние проекты могут быть компонентами Spring, их можно применять с другими разработками. Один из фреймворков, Spring Security, мы упомянули выше. Это отдельный инструментарий. И он не единственный:
- Spring Roo — фреймворк для быстрого создания бизнес-приложений. Он связан со Spring и частично пользуется его возможностями, но задача у него другая, более специфическая. Он реализует подход «соглашение прежде конфигурации», или CoC (Convention over Configuration). Это означает, что фреймворк включает ряд соглашений по структуре проекта, и они превыше конкретных конфигурационных решений. Подход нужен, чтобы быстро создавать типовые приложения и не заботиться о разработке уникальных соглашений;
- Spring Integration — фреймворк для интеграции разных корпоративных приложений в единую сеть. Он позволяет обмениваться сообщениями, маршрутизировать потоки данных, активировать сервисы, интегрироваться с различными технологиями и строить архитектуру сети. Это бывает нужно, например, на больших предприятиях.
Станьте Java-разработчиком
и создавайте сложные сервисы
на востребованном языке
В чем разница между Spring и Spring Boot
В начале работы с фреймворком можно перепутать Spring и Spring Boot. Это не отдельный фреймворк, а дополнение к Spring, которое облегчает работу с ним. Spring нужно конфигурировать для каждого нового проекта. Конфигурация может занять много времени и не дать ощутимые преимущества в дальнейшей работе. Чтобы исправить проблему, был создан Spring Boot. Он включает комплекс утилит для автоматизации настройки.
- автоматически конфигурирует проекты на основе одного из стартовых пакетов для них;
- облегчает создание и развертывание приложений на Spring;
- быстро и легко управляет зависимостями и подгружает необходимые модули;
- поддерживает встроенный сервер для запуска приложений;
- может автоматически создать и настроить базу данных для приложения.
При необходимости настройки Spring Boot можно изменить, чтобы он конфигурировал и настраивал компоненты иначе. Набор утилит облегчает работу со Spring, поэтому некоторые туториалы по умолчанию написаны с учетом использования Spring Boot.
Преимущества Spring
Возможность комплексного использования. Благодаря огромному количеству компонентов и технологий, которые поддерживает Spring, он универсален. Его можно использовать комплексно, например для разных частей архитектуры MVC или решения других сложных задач. Не нужно собирать большой стек технологий. Если чего-то окажется недостаточно, помогут дополнительные инструменты и другое ПО экосистемы Spring.
Облегчение и ускорение работы. Цель любого фреймворка — делать работу эффективнее и быстрее. То, на что ушло бы несколько месяцев на «чистом» языке, с фреймворком делается за считанные дни, а в коммерческой разработке время имеет ключевое значение. Фреймворк — как каркас, вокруг которого пишется остальной код программы. Некоторые компоненты и логика уже реализованы, и задача программиста — в том, чтобы грамотно ими воспользоваться.
Масштабность. Благодаря огромной экосистеме можно подобрать решение для любой задачи. Дополнительные модули, технологии и программное обеспечение от разработчиков существуют для большинства актуальных направлений: веб-разработки, создания микросервисов, реализации той или иной программной модели. Все дополнительные технологии описаны на официальном сайте, там же есть примеры их использования для решения разных задач.
Большое сообщество. Spring востребован и нужен на рынке труда. С ним работают много энтузиастов, поэтому вы, скорее всего, сможете найти ответ на свой вопрос на тематических порталах. У него обширная документация, часть которой переведена на русский язык. Энтузиасты постоянно улучшают фреймворк или дополняют его новыми технологиями — в долговременной перспективе это облегчает программирование.
Открытый исходный код. Spring бесплатный, а его код открыт всем желающим. Технологии, связанные с Java, чаще других бывают проприетарными и закрытыми, поэтому открытость Spring особенно важна — она снижает порог входа и облегчает изучение фреймворка.
Недостатки Spring
Долгая настройка. «Чистый» Spring требует длительной конфигурации с нуля для каждого проекта. Это отнимает время и силы. Для решения проблемы существует Spring Boot. Он упрощает работу с фреймворком, но может стать причиной путаницы из-за схожести названий.
Сложный старт. Java и связанные с ней технологии — не самые простые для старта. Поэтому новичкам может быть сложно начать изучение программирования именно со Spring и дочерних инструментов.
Как начать пользоваться Spring Framework
Начинать работу с Spring и осваивать фреймворк лучше после того, как вы познакомились с базой программирования на «чистом» Java. На официальном сайте есть инструкция по подключению фреймворка: достаточно указать несколько параметров, и сайт сам сгенерирует код. Его нужно вставить в конфигурацию сборки Java — после этого фреймворком можно пользоваться в проектах. На ранних этапах изучения можно воспользоваться обучающими материалами, которые есть в открытом доступе даже на официальном сайте. Существуют русскоязычные сообщества энтузиастов, тематические сайты и порталы, где можно общаться с единомышленниками.
Java-разработчик
Java уже 20 лет в мировом топе языков программирования. На нем создают сложные финансовые сервисы, стриминги и маркетплейсы. Освойте технологии, которые нужны для backend-разработки, за 14 месяцев.

Статьи по теме:
Spring и Hibernate простыми словами: обзор для новичков
Spring и Hibernate — два популярных инструмента для Java, которые используются в разработке приложений. В этой статье мы исследуем их основные функции и особенности, как они работают вместе и почему так высоко ценятся в IT-индустрии. А сложные концепции разбираем на понятные кусочки, которые мягко введут в курс дела любого новичка: программиста, аналитика, менеджера по продукту или дизайнера.

Что такое Spring
В двух словах, Spring (англ. «весна») — это свободный комплексный фреймворк для программирования на языке Java, который упрощает разработку сложных корпоративных приложений.
Появление этого инструмента в 2002 году стало ассоциироваться с наступлением тёплой весны после долгой зимы: Род Джонсон с выходом своей книги «Expert One-on-One J2EE Design and Development» предложил новый дизайн разработки как антидот к тяжеловесным, сложным процессам программирования, которые были распространены тогда. Основной целью было упростить процесс разработки, сделать его более гибким и лёгким.
Spring — это контейнер, который может быть запущен без использования веб-сервера или серверного ПО. Это как набор инструментов, предлагающий различные модули для выполнения задач, таких как доступ к данным, безопасность, транзакции и обмен сообщениями. Красота Spring заключается в том, что вы можете использовать эти модули отдельно или вместе, в зависимости от потребностей вашего проекта.
Что такое ORM
ORM (Object-Relational Mapping) — это техника проектирования, широко используемая в Java, особенно при работе с фреймворками.
Представьте себе ORM как переводчика: в мире разработки существует языковой барьер между объектно-ориентированными языками программирования, такими как Java, и базами данных, которые понимают реляционный язык. ORM умело преодолевает этот барьер, обеспечивая возможность беспрепятственного контакта между языками. Она в основном «отображает» данные из объектной модели в реляционную.
Красота ORM заключается в её простоте и удобстве. Вместо написания сложных SQL-запросов для взаимодействия с базой данных, ORM берёт на себя тяжёлую работу по преобразованию между двумя моделями и позволяет вам взаимодействовать с данными в терминах объектов и классов. Это делает ваш код более чистым, читаемым и эффективным.
С помощью ORM вы можете больше сосредоточиться на бизнес-логике вашего приложения и меньше заботиться о технических аспектах взаимодействия с базой данных, что делает её любимым инструментом как для новичков, так и для опытных разработчиков на Java.
О модулях Spring
Spring имеет модульную структуру, т. е. состоит из различных модулей, каждый из которых выполняет определенную функцию. Это как набор инструментов: у вас есть отвёртка для винтов, молоток для гвоздей и т. д. Аналогично, в фреймворке Spring есть модули, такие как Core, AOP, Data, MVC, Boot и другие, и все они предназначены для разных аспектов разработки приложений на Java.
Теперь представьте, что вы столкнулись с упрямым винтом, который тяжело вкручивается. В этот момент внимания заслуживает Hibernate — ещё один Java-фреймворк, который упрощает работу с базами данных, действуя как смазка, которая позволяет винту (т. е. обработке данных) вращаться плавно. Hibernate часто используется в паре с Spring, и в следующих разделах статьи мы расскажем об их взаимодействии более подробно.
Spring Boot для Spring
Spring и Spring Boot представляют собой два значимых концепта в экосистеме Java. Однако понимание их различий является важным, особенно для начинающих.
Вот простое объяснение: представьте себе Spring как огромный инструментарий, наполненный всеми гаджетами, которые вам могут понадобиться для любого проекта по улучшению дома. Он предлагает комплексную модель программирования и конфигурации для предприятий, основанных на Java, обеспечивая всеобъемлющую систему поддержки инфраструктуры. Он мощный, однако настройка приложения Spring часто оказывается сложной для новичка.
С другой стороны, Spring Boot похож на готовый комплект для сборки. Он берёт обширный инструментарий, который представляет собой Spring, и упаковывает его в удобный набор, предназначенных для определённых задач. Например, создание автономных приложений Spring высокого качества с минимальными хлопотами. Spring Boot упрощает процесс с помощью функции автоматической конфигурации, устраняя значительную часть ручной настройки проекта. Это идеальная отправная точка для начинающих, поскольку позволяет начать работу сразу, не нуждаясь в глубоком понимании каждого инструмента из набора.
Особенности и преимущества Spring
- Простота, гибкость, универсальность. Фреймворк разработан для поддержки всех типов развертывания, от небольших приложений до крупных корпоративных решений. А для начинающих это означает, что кривая обучения будет крута, но потенциал для применения — огромен.
- Возможность внедрения зависимостей (DI). DI — это шаблон проектирования, который позволяет реализовывать слабую связь, что упрощает тестирование и поддержку кода. Его можно сравнить с личным помощником, который приносит вам то, что вам нужно, именно когда вам это нужно. Это делает процесс написания кода более гладким и эффективным, что особенно полезно для новичков.
- Контейнер инверсии управления (IoC) Spring предоставляет мощный способ управления компонентами вашего приложения. Это похоже на главный контроллер, который обрабатывает создание и связывание ваших объектов, что помогает избежать большого объёма ручной работы.
- Поддержка аспектно-ориентированного программирования (АОР). Это парадигма программирования, которая стремится увеличить модульность, позволяя разделять сквозные аспекты разработки. Она как волшебная палочка, которая может добавлять дополнительную функциональность там, где вам это нужно, не затрагивая существующий код. Это позволяет изменять подход к организации кода, что делает его более понятным для начинающих и упрощает навигацию по структуре сложных проектов.
- Интеграция с другими Java-фреймворками и технологиями. Spring хорошо совместим с другими популярными фреймворками, такими как Hibernate, Struts и JUnit, JPA и даже облачными платформами. Вы можете объединить преимущества различных моделей для создания надёжного и эффективного приложения. Возможность работать в гармонии с другими инструментами может значительно улучшить опыт обучения для новичков, предоставив им более широкое понимание Java-экосистемы.
- Spring Boot, проект в составе экосистемы Spring, предоставляет более быстрый и эффективный способ настройки и запуска приложений Spring. Он устраняет много шаблонного кода конфигурации, позволяя вам сконцентрироваться на написании бизнес-логики.
Кто и где использует Spring?
Spring Framework — незаменимый инструмент программистов разных уровней и областей. Он особенно важен для тех, кто разрабатывает приложения для предприятий. Фреймворк используют и разработчики бэкэнда, создающие надёжные API, и архитекторы ПО, проектирующие сложные системы.
Так, с ним следует познакомиться и разработчику-новичку, и опытному сеньору, и менеджеру продукта, который стремится понять технические основы своего продукта.
Как Spring помогает в работе?
Spring помогает формировать каркас, в котором будут работать программисты. У фреймворка есть своя большая библиотека разнообразных функций, которая позволяет программисту не писать код с нуля, внедряя в проект необходимый функционал.
Например, если аналитик хочет создать приложение, основанное на данных, он может использовать функцию доступа/интеграции данных Spring. Это включает поддержку JDBC, ORM, управление транзакциями и многое другое, что упрощает взаимодействие с базами данных и выполнение различных операций, таких как обновление, удаление или извлечение записей.
А вот контейнер IoC Spring выручает так: представим, что продакт-менеджер работает над проектом, который включает несколько взаимозависимых объектов. Вместо ручного управления этими зависимостями он может положиться на контейнер IoC, который берёт на себя эту ответственность. Он обрабатывает создание экземпляров, конфигурацию и сборку объектов, снижая нагрузку на программистов и повышая эффективность.
Как начать работать с фреймворком
Шаг 1: Понять основы
Прежде чем приступить к кодированию, уделите время для понимания основных концепций Spring. Ознакомьтесь с Dependency Injection (DI), Aspect Oriented Programming (AOP) и архитектурой Model-View-Controller (MVC).
Шаг 2: Установить и настроить среду
Убедитесь, что на вашем компьютере установлена последняя версия Java Development Kit (JDK). После этого вам потребуется настроить интегрированную среду разработки (IDE). Spring Tool Suite (STS) или IntelliJ IDEA отлично подходят для разработки на Spring — они имеют встроенную поддержку для Spring.
После установки (например, STS) запустите программу. Вас могут попросить выбрать рабочую область, где будут храниться ваши будущие проекты — выберите подходящее место.
Затем убедитесь, что STS знает, где установлен JDK:
«Window» -> «Preferences» -> «Java» -> «Installed JREs»
Проверьте, есть ли JDK там. Если нет, нажмите «Add», найдите место установки JDK и добавьте его.
Шаг 3: Создать первый проект
Начните с создания простого проекта в своей IDE. Spring Initializr — отличный инструмент, который поможет вам создать новый проект. Этот веб-сервис сгенерирует для вас базовую структуру проекта, которую вы сможете импортировать в свою IDE.
Затем попробуйте создать простое приложение, например, список дел. Это позволит вам ознакомиться с экосистемой Spring и тем, как взаимодействуют различные компоненты.
Что такое Hibernate
В начале статьи мы сравнили Hibernate с переводчиком. И это действительно мощный инструмент, который владеет и языком объектов и классов (на Java), и языком таблиц, строк и столбцов (в базе данных). Он переводит ваш объектно-ориентированный код в то, что способна понять ваша база данных, и наоборот.
Представьте, что вам пришлось бы вручную переводить каждое предложение между двумя людьми, которые говорят на разных языках. Довольно утомительно, верно? Hibernate автоматизирует этот процесс перевода, экономя вам много времени и усилий при разработке приложения. Более того, он берёт на себя всю сложную работу с базами данных, чтобы вы смогли сфокусироваться на логике вашего проекта.
Особенности и преимущества Hibernate
- Упрощенное управление данными. Снова о том самом объектно-реляционном отображении (ORM). Оно позволяет разработчикам работать с данными более интуитивно, используя объекты Java, вместо написания сложных SQL-запросов.
- Независимость от базы данных. Hibernate может работать с практически любым типом базы данных, будь то MySQL, Oracle или SQL Server. Это позволяет разработчикам изменять используемую систему БД, не переписывая свой код, что увеличивает гибкость и обеспечивает защиту от устаревания приложения.
- Оптимизация производительности. Фреймворк включает несколько функций, которые помогают оптимизировать производительность ваших приложений. Например, кэш первого уровня — хранит данные, к которым часто обращаются; ленивая загрузка — откладывает загрузку определенных данных до момента их необходимости. Обе функции могут значительно увеличить скорость и эффективность ваших приложений.
- Надежное управление транзакциями. Hibernate обеспечивает согласованность и целостность данных, позволяя разработчикам определить границы транзакции и автоматически управлять откатами и подтверждениями операций. Это снижает вероятность повреждения данных и делает приложение более надежным.
Кто и где использует Hibernate?
Java-, Backend-разработчики, администраторы баз данных — основные пользователи Hibernate. Этот фреймворк упрощает взаимодействие между Java-приложениями и базами данных и отлично подходят для создания, тестирования и поддержки серверной части веб-приложений. Enterprise-архитекторы отвечают за определение архитектуры программной системы. Гибкость и адаптивность Hibernate делают его мощным инструментом для них.
Что касается сфер, Hibernate используется в отраслях, где сохранение данных является неотъемлемой потребностью:
- Электронная коммерция. Фреймворк облегчает обработку сложных каталогов товаров и больших баз данных клиентов.
- Банки и финансы. Hibernate помогает управлять обширными записями о транзакциях и данными клиентов.
- Здравоохранение. Записи пациентов, истории лечения и многое другое могут быть эффективно управляемыми с помощью этого фреймворка.
- Телекоммуникации. Hibernate помогает в управлении обширными данными о клиентах и использовании продукта.
- Образование. Онлайн-платформы для обучения используют его для управления курсами и обработки данных студентов.
Как Hibernate помогает в работе?
На примере электронной коммерции:
- Вам нужно сохранять и извлекать данные о покупках клиентов для поддержки вашей системы рекомендаций. Вместо написания сложных SQL-запросов Hibernate позволяет вам взаимодействовать с базой данных напрямую с помощью Plain Old Java Object (POJO), делая обработку данных более интуитивной и менее подверженной ошибкам, позволяя экономить время и повышать общую производительность проекта.
- Приложению может потребоваться обрабатывать несколько базовых транзакций одновременно. Например, когда несколько пользователей пытаются купить последний экземпляр популярного товара на вашем сайте одновременно. Сделать так, чтобы такие транзакции проходили гладко и без конфликтов, очень трудозатратно. Но Hibernate, благодаря встроенной системе управления транзакциями, справляется с этим проще. Он автоматически управляет открытием и закрытием сессий, обеспечивая выполнение всех операций безопасным и эффективным способом.
Как начать работать с Hibernate
Шаг 1: Понять основы
Hibernate — это инструмент объектно-реляционного отображения (ORM). Основная концепция, которую нужно освоить, — это то, как Hibernate отображает экземпляры классов Java на таблицы базы данных и наоборот.
Изучите такие понятия, как сессии, транзакции и отображения. Официальная документация Hibernate — первый и необходимый ресурс для изучения.
Шаг 2: Установить и настроить среду
Установите последнюю версию Java Development Kit (JDK) на ваш компьютер, затем — любую удобную для вас IDE (например, Eclipse и IntelliJ IDEA совместимы с этим фреймворком).
После этого загрузите фреймворк Hibernate ORM с официального веб-сайта Hibernate.
Шаг 3: Создать первый проект
Создайте новый проект в вашей IDE, дайте ему удобное название, например, FirstHibernateProject.
Чтобы использовать Hibernate в вашем проекте, вам необходимо добавить его библиотеку. Перейдите в «Project Structure» или «Properties» (в зависимости от вашей IDE), выберите «Libraries», а затем «Add Library». Найдите Hibernate и добавьте его в ваш проект.
Затем настройте файл hibernate.cfg.xml, чтобы подключить фреймворк к вашей базе данных. Этот файл важен, так как содержит информацию о конфигурации Hibernate: детали базы данных, учётные данные и файлы сопоставления.
Теперь можно начинать решать простые задачи. Например, создать Java-объект и отобразить его на таблицу базы данных. Для этого напишите код для выполнения основных операций с базой данных — создание, чтение, обновление и удаление (CRUD).
По мере того, как вы становитесь более уверенными, переходите к более сложным задачам, таким как отношения между таблицами и стратегии извлечения данных. Используйте онлайн-учебники, официальную документацию и форумы сообщества, чтобы решать вопросы и улучшать понимание фреймворков.
И помните, что практика — ключ к глубокому и увлекательному изучению новых технологий и инструментов. Опыта и компетенций экспертов международного онлайн-университета ProductStar хватит на то, чтобы теперь помочь вам уверенно встать на путь Java-разработчика: научиться программировать на Java, получить специализацию (Android, WebDev), добавить сильные кейсы в портфолио и пройти стажировку в IT-компании уже во время обучения.
- Блог компании ProductStar
- Java
Выборка данных с ORM — это просто! Или нет?

Практически любая информационная система так или иначе взаимодействует с внешними хранилищами данных. В большинстве случаев это реляционная база данных, и, зачастую, для работы с данными используется какой-либо ORM фреймворк. ORM устраняет большую часть рутинных операций, взамен предлагая небольшой набор дополнительных абстракций для работы с данными.
Мартин Фаулер опубликовал интересную статью, одна из ключевых мыслей там: “ORM’ы помогают нам решать большое количество задач в энтерпрайз приложениях… Этот инструмент нельзя назвать симпатичным, но и проблемы, с которыми он имеет дело, тоже не милашки. Я думаю, что ORM заслуживают больше уважения и больше понимания”
Мы очень интенсивно используем ORM во фреймворке CUBA , так что не понаслышке знаем о проблемах и ограничениях этой технологии, поскольку CUBA используется в различных проектах по всему миру. Есть много тем, которые можно обсудить в связи с ORM, но мы сосредоточимся на одной из них: выбор между “ленивым” (lazy) и “жадным” (eager) способами выборки данных. Поговорим о разных подходах к решению этой проблемы с иллюстрациями из JPA API и Spring, а также расскажем, как (и почему именно так) ORM используется в CUBA и какие работы мы ведем, чтобы улучшить работу с данными в нашем фреймворке.
Выборка данных: ленивая или нет?
Если в вашей модели данных только одна сущность, то никаких проблем при работе с ORM вы, скорее всего, не заметите. Давайте рассмотрим небольшой пример. Пусть у нас есть сущность User (Пользователь) , у которой есть два атрибута ID и Name (Имя) :
public class User < @Id @GeneratedValue private int id; private String name; //Getters and Setters here >Чтобы вытащить экземпляр этой сущности из БД, нам нужно всего лишь вызвать один метод объекта EntityManager :
EntityManager em = entityManagerFactory.createEntityManager(); User user = em.find(User.class, id); Все становится немного интереснее, когда появляется отношение “один-ко-многим”:
public class User < @Id @GeneratedValue private int id; private String name; @OneToMany private Listaddresses; //Getters and Setters here > Если нам нужно извлечь из БД экземпляр пользователя, возникает вопрос: “А адреса тоже выбираем?”. И “правильный” ответ здесь: “Зависит от. ” В некоторых случаях нам адреса будут нужны, в некоторых — нет. Обычно ORM предоставляет два способа выборки зависимых записей: ленивый и жадный. По умолчанию в большинстве ORM используется ленивый способ. Но, если мы напишем такой код:
EntityManager em = entityManagerFactory.createEntityManager(); User user = em.find(User.class, 1); em.close(); System.out.println(user.getAddresses().get(0)); … то получим исключение “LazyInitException” , которое ужасно сбивает с толку новичков, которые только начали работать с ORM. И тут наступает момент, когда нужно начинать рассказ о том, что такое “Attached” и “Detached” экземпляры сущности, что такое сессии и транзакции.
Ага, значит сущность должна быть “присоединена” к сессии, чтобы можно было выбирать зависимые данные. Хорошо, давайте не будем сразу закрывать транзакции, и жизнь сразу станет проще. И тут возникает другая проблема — транзакции становятся длиннее, что увеличивает риск взаимной блокировки. Делать транзакции короче? Можно, но если создавать много-много маленьких транзакций, то получим “Сказку про Комара Комаровича — длинный нос и про мохнатого Мишу — короткий хвост” про то, как орда крохотных комаров медведя победила — так получится и с базой данных. Если число мелких транзакций значительно возрастет, то возникнут проблемы с производительностью.
Как было сказано, при выборке данных о пользователе адреса могут или потребоваться или нет, поэтому, в зависимости от бизнес-логики, нужно или делать выборку коллекции, или нет. Нужно добавлять новые условия в код… Гммм… Что-то как-то все усложняется.
Так, а если попробовать другой тип выборки?
public class User < @Id @GeneratedValue private int id; private String name; @OneToMany(fetch = FetchType.EAGER) private Listaddresses; //Getters and Setters here > Ну… нельзя сказать, что это сильно поможет. Да, избавимся от ненавистного LazyInit и не надо проверять, прикреплена сущность к сессии или нет. Но теперь у нас могут возникнуть проблемы с производительностью, потому что адреса нам нужны не всегда, а мы все равно выбираем эти объекты в память сервера.
Spring JDBC
Некоторые разработчики настолько устают от ORM, что переключаются на альтернативные фреймворки. Например, на Spring JDBC, который предоставляет возможность преобразования реляционных данных в объектные в “полуавтоматическом” режиме. Разработчик пишет запросы для каждого случая, где нужен тот или иной набор атрибутов (или один и тот же код повторно используется для случаев, где нужны одинаковые структуры данных).
Это дает нам большую гибкость. Например, можно выбрать только один атрибут, не создавая соответствующий объект-сущность:
String name = this.jdbcTemplate.queryForObject( "select name from t_user where new Object[], String.class); Или выбрать объект в привычном виде:
User user = this.jdbcTemplate.queryForObject( "select id, name from t_user where new Object[], new RowMapper() < public User mapRow(ResultSet rs, int rowNum) throws SQLException < User user = new User(); user.setName(rs.getString("name")); user.setId(rs.getInt("id")); return user; >>); Также можно выбрать и список адресов для пользователя, нужно только написать чуть больше кода и правильно составить SQL запрос, чтобы избежать проблемы n+1 запроса.
Тааак, опять сложновато. Да, мы контролируем все запросы и то, как данные отображаются на объекты, но надо писать больше кода, учить SQL и знать, как запросы выполняются в базе данных. Лично я думаю, что знание SQL — это обязательный навык для прикладного программиста, но так думают не все, и я не собираюсь вступать в полемику. В конце концов, знание инструкций x86 ассемблера в наши дни тоже необязательно. Давайте лучше подумаем о том, как облегчить жизнь программистам.
JPA EntityGraph
А давайте сделаем шаг назад и подумаем, что нам вообще нужно? Похоже, что нам просто надо указывать, какие точно атрибуты нам нужны в каждом конкретном случае. Ну и давайте это делать! В JPA 2.1 появился новый API — EntityGraph (граф сущностей). Идея — очень простая: используем аннотации для того, чтобы описать то, что будем выбирать из базы. Вот пример:
@Entity @NamedEntityGraphs(< @NamedEntityGraph(name = "user-only-entity-graph"), @NamedEntityGraph(name = "user-addresses-entity-graph", attributeNodes = ) >) public class User < @Id @GeneratedValue private int id; private String name; @OneToMany(fetch = FetchType.LAZY) private Setaddresses; //Getters and Setters here > Для данной сущности описано два графа: user-only-entity-graph не выбирает атрибут Addresses (помеченный как lazy), в то время, как второй граф указывает ORM выбирать этот атрибут. Если мы пометим Addresses как eager, то граф будет проигнорирован и адреса будут выбраны в любом случае.
Итак, в JPA 2.1 можно делать выборку данных вот так:
EntityManager em = entityManagerFactory.createEntityManager(); EntityGraph graph = em.getEntityGraph("user-addresses-entity-graph"); Map properties = Map.of("javax.persistence.fetchgraph", graph); User user = em.find(User.class, 1, properties); em.close(); Этот подход сильно упрощает работу, не нужно отдельно думать про lazy атрибуты, и длину транзакций. Дополнительный бонус — граф применяется на уровне SQL запроса, таким образом “лишние” данные не выбираются в Java приложение. Но есть одна небольшая проблема: нельзя сказать, какие атрибуты были выбраны, а какие — нет. Для проверки есть API, это делается при помощи класса PersistenceUnit :
PersistenceUtil pu = entityManagerFactory.getPersistenceUnitUtil(); System.out.println("User.addresses loaded: " + pu.isLoaded(user, "addresses")); Но это довольно-таки уныло и не все готовы делать такие проверки. А можно ещё что-нибудь упростить и просто не показывать атрибуты, которые не были выбраны?
Проекции Spring
В Spring Framework есть отличная штука, которая называется “Проекции” (и это не то же самое, что проекции в Hibernate). Если нужно выбрать только некоторые атрибуты сущности, то создается интерфейс с нужными атрибутами, и Spring выбирает “экземпляры” этого интерфейса из БД. В качестве примера, рассмотрим следующий интерфейс:
interface NamesOnly
Теперь можно определить Spring JPA репозиторий для выборки сущностей User следующим образом:
interface UserRepository extends CrudRepository < CollectionfindByName(String lastname); > В этом случае, после вызова метода findByName, в полученном списке мы получим сущности, у которых доступ открыт только к атрибутам, которые определены в интерфейсе! По такому же принципу можно выбирать и зависимые сущности, т.е. выбираем сразу отношение “master-detail”. Более того, Spring генерирует “правильный” SQL в большинстве случаев, т.е. из БД выбираются только те атрибуты, которые описаны в проекции, это очень похоже на то, как работают графы сущностей.
Это очень мощный API, при определении интерфейсов можно использовать выражения SpEL, использовать классы с какой-то встроенной логикой вместо интерфейсов и ещё много чего, в документации все расписано очень подробно.
Единственная проблема с проекциями в том, что внутри они реализованы в виде пар “ключ — значение”, т.е. предназначены только для чтения. А это значит, что, даже если мы и определим setter метод для проекции, то изменения сохранить не сможем ни через CRUD репозитории, ни через EntityManager. Так что проекции — это такие DTO, которые можно преобразовать обратно в Entity и сохранять, только если написать свой собственный код для этого.
Как выбираются данные в CUBA
С самого начала разработки фреймворка CUBA мы старались оптимизировать часть кода, который работает с БД. В CUBA мы используем EclipseLink как основу для API доступа к данным. Что хорошо в EclipseLink — он с самого начала поддерживал частичную загрузку сущностей, и это стало решающим фактором в выборе между ним и Hibernate. В EclipseLink можно было указать атрибуты для загрузки задолго до того, как появился стандарт JPA 2.1. В CUBA существует собственный способ описания графа сущностей, называется CUBA Views (представления CUBA). Представления CUBA — довольно-таки развитый API, можно наследовать одни представления от других, комбинировать их, применяя как к master, так и к detail сущностям. Ещё одна мотивация для создания CUBA представлений — мы хотели использовать короткие транзакции, чтобы можно было работать с открепленными сущностями в пользовательском web-интерфейсе.
В CUBA представления описываются в XML файле, как в примере ниже:
Это представление выбирает сущность User и его локальный атрибут name , а также выбирает адреса, применяя к ним представление address-street-only-view . Все это происходит (внимание!) на уровне SQL запроса. Когда представление создано, можно его использовать в выборке данных при помощи класса DataManager:
List users = dataManager.load(User.class).view("user-edit-view").list(); Этот подход отлично работает, при этом экономно расходуя сетевой трафик, поскольку неиспользуемые атрибуты просто не передаются от БД к приложению, но, как и в случае с JPA, есть проблема: нельзя сказать, какие атрибуты сущности были загружены. И в CUBA есть исключение “IllegalStateException: Cannot get unfetched attribute [. ] from detached object” , которое, как и LazyInit , наверняка встречалось всем, кто пишет с использованием нашего фреймворка. Как и в JPA, есть способы проверки того, какие атрибуты были загружены, а какие нет, но, опять же, написание таких проверок — нудное, кропотливое занятие, которое очень расстраивает разработчиков. Нужно придумать что-то ещё, чтобы не нагружать людей работой, которую, в теории, могут сделать машины.
Концепт — CUBA View Interfaces
А что, если все-таки попробовать совместить графы сущностей и проекции? Мы решили попробовать это сделать и разработали интерфейсы для представления сущностей (entity view interfaces), которые повторяют подход из проекций Spring. Эти интерфейсы транслируются в CUBA представления при старте приложения и могут быть использованы в DataManager. Идея проста: описываем интерфейс (или набор интерфейсов), который и представляет из себя граф сущностей.
interface UserMinimalView extends BaseEntityView < String getName(); void setName(String val); ListgetAddresses(); interface AddressStreetOnly extends BaseEntityView < String getStreet(); void setStreet(String street); >> Стоит отметить, что для каких-то конкретных случаев можно делать локальные интерфейсы, как в случае AddressStreetOnly из примера выше, чтобы не “загрязнять” публичный API своего приложения.
В процессе старта CUBA приложения (бОльшая часть которого — это инициализация контекста Spring), мы программно создаем CUBA представления и помещаем их во внутренний бин — репозиторий в контексте.
Теперь нужно немного изменить имплементацию класса DataManager, чтобы он принимал представления-интерфейсы, и можно делать выборку сущностей вот таким образом:
List users = dataManager.loadWithView(UserMinimalView.class).list(); Под капотом генерируется прокси-объект, который реализует интерфейс и оборачивает экземпляр сущности, выбранный из БД (примерно так же, как это делается в Hibernate). И, когда разработчик обращается за значением атрибута, то прокси делегирует вызов метода “настоящему” экземпляру сущности.
При разработке этого концепта мы пытаемся убить одним выстрелом двух зайцев:
- Данные, которые не описаны в интерфейсе, не загружаются в приложение, тем самым мы экономим ресурсы сервера.
- Разработчик может использовать только те атрибуты, которые доступны через интерфейс (и, следовательно, выбраны из БД), тем самым убираются UnfetchedAttribute исключения, про которые мы писали выше.
В отличие от проекций Spring, мы оборачиваем сущности в прокси-объекты, кроме того, каждый интерфейс наследует стандартный интерфейс CUBA — Entity. Это значит, что атрибуты Entity View можно изменять, а потом сохранять эти изменения в БД, используя стандартный API CUBA для работы с данными.
И, кстати, “третий заяц” — можно делать атрибуты доступными только для чтения, если определить интерфейс только с getter методами. Таким образом, мы уже на уровне API сущности задаем правила модификации.
В дополнение, можно сделать некоторые локальные операции для открепленных сущностей, используя доступные атрибуты, например, преобразование строки имени, как в примере ниже:
@MetaProperty default String getNameLowercase()
Заметьте, что вычисляемые атрибуты можно вынести из модели классов сущностей и перенести в интерфейсы, применимые к конкретной бизнес логике.
Ещё одна интересная возможность — наследование интерфейсов. Можно сделать несколько представлений с разными наборами атрибутов, а затем их комбинировать. Например, можно создать интерфейс для сущности User с атрибутами name и email, и другой — с атрибутами name и addresses. Теперь, если нужно выбирать name, email и addresses, то не нужно копировать эти атрибуты в третий интерфейс, нужно просто унаследоваться от первых двух представлений. И да, экземпляры третьего интерфейса можно передавать в методы, которые принимают параметры с типом интерфейсов-родителей, правила ООП одинаковы для всех.
Также было реализовано преобразование между представлениями — в каждом интерфейсе есть метод reload(), в который можно передать класс представления в качестве параметра:
UserFullView userFull = userMinimal.reload(UserFullView.class); Представление UserFullView может содержать дополнительные атрибуты, так что сущность будет загружена заново из БД, если необходимо. И этот процесс — отложенный. Обращение к БД будет произведено только тогда, когда произойдет первое обращение к атрибутам сущности. Это немного замедлит первое обращение, но такой подход был выбран намеренно — если экземпляр сущности используется в модуле “web”, в котором находится UI и собственные REST контроллеры, то этот модуль может быть развернут на отдельном сервере. А это значит, что принудительная перегрузка сущности создаст дополнительный сетевой трафик — обращение к модулю core и затем к БД. Таким образом, откладывая перегрузку до того момента, когда это необходимо, мы экономим трафик и уменьшаем количество запросов к БД.
Концепт оформлен в виде модуля для CUBA, пример использования можно скачать с GitHub.
Заключение
Кажется, что в ближайшем будущем мы все ещё будем массово использовать ORM в энтерпрайз приложениях просто потому, что нам нужно что-то, что будет превращать реляционные данные в объекты. Конечно, для сложных, уникальных, сверхвысоконагруженных приложений будут разрабатываться какие-то специфичные решения, но, похоже, что ORM фреймворки будут жить столько же, сколько реляционные базы данных.
В CUBA мы стараемся упростить работу с ORM по максимуму, и в следующих версиях мы будем вводить новые возможности для работы с данными. Будут ли это интерфейсы-представления или что-то другое — сейчас сложно сказать, но я уверен в одном: мы будем продолжать упрощать работу с данными в следующих версиях фреймворка.