Как сделать красивый вывод словарей в консоль Python?
Ребята, подскажите пожалуйста как сделать. Гугл ничего хорошего не предложил. Заранее спасибо!
- Вопрос задан более трёх лет назад
- 23005 просмотров
Комментировать
Решения вопроса 1

Сеньор-помидор
for key, value in t.items(): print(": ".format(key,value))Ответ написан более трёх лет назад
Комментировать
Нравится 6 Комментировать
Ответы на вопрос 2

Dimonchik @dimonchik2013
non progredi est regredi
10 приемов Python Pandas, которые сделают вашу работу более эффективной
Pandas — это широко используемый пакет Python для структурированных данных. Существует много хороших учебных пособий на данную тематику, но здесь мы бы хотели раскрыть несколько интересных приемов, которые, вероятно, еще пока неизвестны читателю, но могут оказаться крайне полезными.
read_csv
Все знают эту команду. Но если данные, которые вы пытаетесь прочитать, слишком большие, попробуйте добавить команду nrows = 5 , чтобы прочитать сначала небольшую часть данных перед загрузкой всей таблицы. В этом случае вам удастся избежать ситуации выбора неверного разделителя (не всегда в данных есть разделение в виде запятой).
(Или вы можете использовать команду ‘head’ в linux для проверки первых 5 строк в любом текстовом файле: head -c 5 data.txt )
Затем вы можете извлечь список столбцов, используя df.columns.tolist() , а затем добавить команду usecols = [‘c1’, ‘c2’,…], чтобы извлечь только нужные вам столбцы. Кроме того, если вы знаете типы данных определенных столбцов, вы можете добавить dtype = для более быстрой загрузки. Еще одно преимущество этой команды в том, что если у вас есть столбец, который содержит как строки, так и числа, рекомендуется объявить его тип строковым, чтобы не возникало ошибок при попытке объединить таблицы, используя этот столбец в качестве ключа.
select_dtypes
Если предварительная обработка данных должна выполняться в Python, то эта команда сэкономит ваше время. После чтения из таблицы типами данных по умолчанию для каждого столбца могут быть bool, int64, float64, object, category, timedelta64 или datetime64. Вы можете сначала проверить распределение с помощью
df.dtypes.value_counts()
чтобы узнать все возможные типы данных вашего фрейма, затем используйте
df.select_dtypes(include=[‘float64’, ‘int64’])
чтобы выбрать субфрейм только с числовыми характеристиками.
сopy
Это важная команда. Если вы сделаете:
import pandas as pd
df1 = pd.DataFrame(< ‘a’:[0,0,0], ‘b’: [1,1,1]>)
df2 = df1
df2[‘a’] = df2[‘a’] + 1
df1.head()
Вы обнаружите, что df1 изменен. Это потому, что df2 = df1 не делает копию df1 и присваивает ее df2, а устанавливает указатель, указывающий на df1. Таким образом, любые изменения в df2 приведут к изменениям в df1. Чтобы это исправить, вы можете сделать либо:
df2 = df1.copy ()
from copy import deepcopy
df2 = deepcopy(df1)
map
Это классная команда для простого преобразования данных. Сначала вы определяете словарь, в котором «ключами» являются старые значения, а «значениями» являются новые значения.
level_map =
df[‘c_level’] = df[‘c’].map(level_map)
Например: True, False до 1, 0 (для моделирования); определение уровней; определяемые пользователем лексические кодировки.
apply or not apply?
Если нужно создать новый столбец с несколькими другими столбцами в качестве входных данных, функция apply была бы весьма полезна.
def rule(x, y):
if x == ‘high’ and y > 10:
return 1
else:
return 0
df = pd.DataFrame(< 'c1':[ 'high' ,'high', 'low', 'low'], 'c2': [0, 23, 17, 4]>)
df['new'] = df.apply(lambda x: rule(x['c1'], x['c2']), axis = 1)
df.head()
В приведенных выше кодах мы определяем функцию с двумя входными переменными и используем функцию apply, чтобы применить ее к столбцам ‘c1’ и ‘c2’.
но проблема «apply» заключается в том, что иногда она занимает очень много времени.
Скажем, если вы хотите рассчитать максимум из двух столбцов «c1» и «c2», конечно, вы можете применить данную команду
df[‘maximum’] = df.apply(lambda x: max(x[‘c1’], x[‘c2’]), axis = 1)
но это будет медленнее, нежели:
df[‘maximum’] = df[[‘c1’,’c2']].max(axis =1)
Вывод: не используйте команду apply, если вы можете выполнить ту же работу используя другие функции (они часто быстрее). Например, если вы хотите округлить столбец ‘c’ до целых чисел, выполните округление (df [‘c’], 0) вместо использования функции apply.
value counts
Это команда для проверки распределения значений. Например, если вы хотите проверить возможные значения и частоту для каждого отдельного значения в столбце «c», вы можете применить
df[‘c’].value_counts()
Есть несколько полезных приемов / функций:
A. normalize = True : если вы хотите проверить частоту вместо подсчетов.
B. dropna = False : если вы хотите включить пропущенные значения в статистику.
C. sort = False : показать статистику, отсортированную по значениям, а не по количеству.
D. df[‘c].value_counts().reset_index().: если вы хотите преобразовать таблицу статистики в датафрейм Pandas и управлять ими.
количество пропущенных значений
При построении моделей может потребоваться исключить строку со слишком большим количеством пропущенных значений / строки со всеми пропущенными значениями. Вы можете использовать .isnull () и .sum () для подсчета количества пропущенных значений в указанных столбцах.
import pandas as pd
import numpy as np
df = pd.DataFrame(< ‘id’: [1,2,3], ‘c1’:[0,0,np.nan], ‘c2’: [np.nan,1,1]>)
df = df[[‘id’, ‘c1’, ‘c2’]]
df[‘num_nulls’] = df[[‘c1’, ‘c2’]].isnull().sum(axis=1)
df.head()
выбрать строки с конкретными идентификаторами
В SQL мы можем сделать это, используя SELECT * FROM… WHERE ID в («A001», «C022»,…), чтобы получить записи с конкретными идентификаторами. Если вы хотите сделать то же самое с pandas, вы можете использовать:
df_filter = df ['ID']. isin (['A001', 'C022', . ])
df [df_filter]
Percentile groups
Допустим, у вас есть столбец с числовыми значениями, и вы хотите классифицировать значения в этом столбце по группам, скажем, топ 5% в группу 1, 5–20% в группу 2, 20–50% в группу 3, нижние 50% в группу 4. Конечно, вы можете сделать это с помощью pandas.cut, но мы бы хотели представить другую функцию:
import numpy as np
cut_points = [np.percentile(df[‘c’], i) for i in [50, 80, 95]]
df[‘group’] = 1
for i in range(3):
df[‘group’] = df[‘group’] + (df[‘c’] < cut_points[i])
# or Которая быстро запускается (не применяется функция apply).to_csv
Опять-таки, это команда, которую используют все. Отметим пару полезных приемов. Первый:print(df[:5].to_csv())Вы можете использовать эту команду, чтобы напечатать первые пять строк того, что будет записано непосредственно в файл.
Еще один прием касается смешанных вместе целых чисел и пропущенных значений. Если столбец содержит как пропущенные значения, так и целые числа, тип данных по-прежнему будет float, а не int. Когда вы экспортируете таблицу, вы можете добавить float_format = '%. 0f', чтобы округлить все числа типа float до целых чисел. Используйте этот прием, если вам нужны только целочисленные выходные данные для всех столбцов – так вы избавитесь от всех назойливых нулей ‘.0’ .
Решение модуля 6.1 Добрый, добрый Python
Отметьте все правильные определения словаря.
dict([[1, 'one'], [2, 'two'], [3, 'three']]) <> dict() dict(you='ты', we='мы', they='они', us='нам')Отметьте все правильные указания ключей словаря d = <>:
d['dict'] = d[True] = 'истина' d[1] = 'one' d["house"] = ['дом', 'жилище', 'хижина'] d[5.6] = 5.6Вводятся данные в формате ключ=значение в одну строчку через пробел. Значениями здесь являются целые числа (см. пример ниже). Необходимо на их основе создать словарь d с помощью функции dict() и вывести его на экран командой:
print(*sorted(d.items()))
s = input().split() # ввод данных 'one=1','two=2','three=3' lst = [s[i].split('=') for i in range(len(s))] # разбивка данных .,через list comprehension [s[элемент].split('=') пробегаемся по длинне списка (всего 3 элемента)].Таким образом у нас сейчас данные получаются 'one' '1' и т.д. d = dict(lst) # делаем словарь for key in d: # цикл чтобы получить пару строка : число d[key] = int(d[key]) print(*sorted(d.items()))На вход программы поступают данные в виде набора строк в формате:
ключ1=значение1
ключ2=значение2
…
ключN=значениеNКлючами здесь выступают целые числа (см. пример ниже). Необходимо их преобразовать в словарь d (без использования функции dict()) и вывести его на экран командой:
print(*sorted(d.items()))
P. S. Для считывания списка целиком в программе уже записаны начальные строчки.
import sys # считывание списка из входного потока lst_in = list(map(str.strip, sys.stdin.readlines())) # здесь продолжайте программу (используйте список lst_in) d = <> for s in lst_in: row = s.split('=') d[int(row[0])] = row[1] print(*sorted(d.items()))Вводятся данные в формате ключ=значение в одну строчку через пробел. Необходимо на их основе создать словарь, затем проверить, существуют ли в нем ключи со значениями: ‘house’, ‘True’ и ‘5’ (все ключи — строки). Если все они существуют, то вывести на экран ДА, иначе — НЕТ.
dict_1 = dict([value.split('=') for value in input().split()])# Сохраняем введенную информацию разделяя по пробелам # так же каждый полученный элемент после ввода разделяем по знаку = count = 0 for key, value in dict_1.items(): # Перебираю словарь извлекаю ключи и значения print () if key == 'house' or key == 'True' or key == '5': # Проверю условиe задания count += 1 # Проверяю значения flag и вывожу советующее сообщение в игру # print("ДА" if 'house' in dict_1 and 'True' in dict_1 and '5' in dict_1 else "НЕТ") # Отличный вариант if count == 3: print('ДА') else: print('НЕТ')Вводятся данные в формате ключ=значение в одну строчку через пробел. Необходимо на их основе создать словарь d, затем удалить из этого словаря ключи ‘False’ и ‘3’, если они существуют. Ключами и значениями словаря являются строки. Вывести полученный словарь на экран командой:
print(*sorted(d.items()))
dict_1 = dict([value.split('=') for value in input().split()]) # Сохраняем введенную информацию разделяя по пробелам # так же каждый полученный элемент после ввода разделяем по знаку = if 'False' in dict_1: # Проверяю наличие значение в словаре del dict_1['False'] # Удаляю их по ключу if '3' in dict_1: del dict_1['3'] print(*sorted(dict_1.items())) # Вывожу результатВводятся номера телефонов в одну строчку через пробел с разными кодами стран: +7, +6, +2, +4 и т.д. Необходимо составить словарь d, где ключи — это коды +7, +6, +2 и т.п., а значения — список номеров (следующих в том же порядке, что и во входной строке) с соответствующими кодами. Полученный словарь вывести командой:
print(*sorted(d.items()))
lst = input().split() # создаём список номеров d_keys = dict([[number[:2], 0] for number in lst]) # создаём словарь, состоящий из кодов операторов в качестве клюей и "пустых значений". (Поскольку нам от этого словаря нужны только ключи, лучше бы мы использовали set(), но, пока мы не знаем, что такое set(), такой костыль) d = dict([[key, [number for number in lst if key in number]] for key in d_keys]) # по найденым ключам формируем требуемый словарь. print(*sorted(d.items()))Вводятся номера телефонов в формате:
номер_1 имя_1
номер_2 имя_2
…
номер_N имя_NНеобходимо создать словарь d, где ключами будут имена, а значениями — список номеров телефонов для этого имени. Обратите внимание, что одному имени может принадлежать несколько разных номеров. Полученный словарь вывести командой:
print(*sorted(d.items()))
P. S. Для считывания списка целиком в программе уже записаны начальные строчки.
import sys lst_in = list(map(str.strip, sys.stdin.readlines())) d = <> # Создаю новый массив for x in lst_in: key = x.split(" ")[1] # Ключ второе значение в списке (в результате split(" ")) Имя value = x.split(" ")[0] # Значение второе значение в списке (в результате split(" ")) Телефон if key not in d.keys(): # Ели такого имени (ключа) нет тогда создаем, значение список list d[key] = [value] else: d[key] += [value] # Если есть имя (ключ) добавляем в значение list еще один номер print(*sorted(d.items()))Пользователь вводит в цикле целые положительные числа, пока не введет число 0. Для каждого числа вычисляется квадратный корень (с точностью до сотых) и значение выводится на экран (в столбик). С помощью словаря выполните кэширование данных так, чтобы при повторном вводе того же самого числа результат не вычислялся, а бралось ранее вычисленное значение из словаря. При этом на экране должно выводиться:
значение из кэша:
import math # для вычисления корня импорт math.sqrt slov = <> # создаем пустой словарь while True: num = int(input()) # циклим ввод if num == 0: # если число 0 = выключаем цикл break if num not in slov: # если такого числа нет slov[num] = round(math.sqrt(num), 2) # вычисляем корень и заносим его в словарь print(slov[num]) # выводим else: print("значение из кэша:", slov[num]) # если число уже былоТестовый веб-сервер возвращает HTML-страницы по URL-адресам (строкам). На вход программы поступают различные URL-адреса. Если адрес пришел впервые, то на экране отобразить строку (без кавычек):
«HTML-страница для адреса »
Если адрес приходит повторно, то следует взять строку «HTML-страница для адреса » из словаря и вывести на экран сообщение (без кавычек):
«Взято из кэша: HTML-страница для адреса »
Сообщения выводить каждое с новой строки.
P. S. Для считывания списка целиком в программе уже записаны начальные строчки.
import sys # считывание списка из входного потока lst_in = list(map(str.strip, sys.stdin.readlines())) # лист с запросами URL_adress = [] # созданный картеж для записи уже приходивших запросов URL_word = for URL in lst_in: # берем текст запроса count = URL_adress.count(URL) # Проверяем приходил ли запрос ранее if count == 0: # Проверяем результат поиска URL_adress.append(URL) # записываем запрос в картеж print(URL_word['One'], URL) # выводим запрос в консоль с текстом if count == 1: # Проверяем результат поиска print(URL_word['Duble'], URL) # выводим запрос в консоль с текстомЕсли у вас не отображается решение последних задач, значит у вас включен блокировщик рекламы который вырезает эти ответы
Как вывести словарь в столбик в python
В предыдущих уроках мы учились выводить текст разными способами (а именно - в уроке 11 и уроке 12).
Сегодня усложним структуру вывода строк и текста в Питоне - изучим операторы вывода строк текста в столбик.
Для этого можно использовать команду \n . А можно использовать тройные кавычки. И то, и другое в Python называется "управляющая последовательность". В 15 уроке я более подробно остановлюсь на этих последовательностях. А теперь - только две из них.
Практический пример
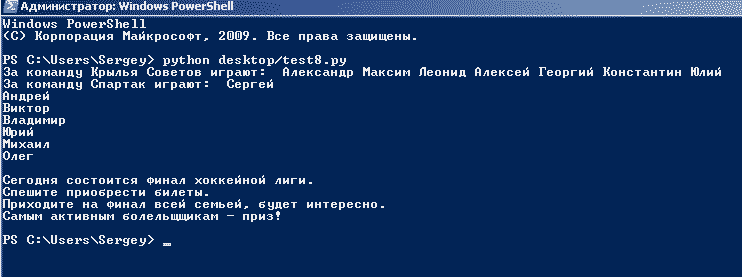
Создаем на рабочем столе файл test8.py Пишем в него руками следующий программный код:
# -*- coding: utf- 8 -*- igroki_1 = u"Александр Максим Леонид Алексей Георгий Константин Юлий" igroki_2 = u"Сергей\nАндрей\nВиктор\nВладимир\nЮрий\nМихаил\nОлег" print u"За команду Крылья Советов играют: ", igroki_1 print u"За команду Спартак играют: ", igroki_2 print u""" Сегодня состоится финал хоккейной лиги. Спешите приобрести билеты. Приходите на финал всей семьей, будет интересно. Самым активным болельщщикам - приз! """Теперь открываем программу PowerShell и прописываем команду python desktop/test8.py
У вас должно получиться следующее:
Как вы можете наблюдать, и в первой части программы и во второй строки могут выводиться в столбик, каждая – с новой строки. Вы можете использовать оба варианта вывода текста, какой вам больше нравится.
Домашнее задание
Составьте программу с перечислением имен учеников в классе или группе ВУЗа. Попробуйте записать ее как с использованием команды \n , так и с использованием тройных кавычек.
Напоминаю про лайфхак в случае постоянных ошибок при вводе текста - нажимаем курсор вправо и можно не вводить путь заново (подробнее ЗДЕСЬ).
В следующем уроке мы освоим более сложные приемы работы с операторами форматирования - перейти в урок 14.
- Вы здесь:
- Главная
- Python 2.7 с нуля
- Урок 13. Вывод строк в столбик: команда n и тройные кавычки