Удаление элемента из односвязного списка

Почему не работает функция удаления идентификатора? Как ее можно переделать?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93
#include"stdafx.h" #include "conio.h" #include "stdio.h" #include "stdlib.h" #include "string.h" void print(struct spisok *p); struct spisok { char id[8]; struct spisok *next; }; struct spisok* vvod(struct spisok *p, char i[8]); struct spisok* udalenie(struct spisok *p); int main() { int i; char j[8]; struct spisok *p,*f; p=NULL; for(i=0;i3;i++) { printf("vvedite identificatori\n"); gets(j); p= vvod(p,j); } f=udalenie(p); print(f); getch(); return 0; } struct spisok* vvod(struct spisok *p, char j[8] ) struct spisok *pt,*k,*f; pt = (struct spisok *) malloc(sizeof( struct spisok)); strcpy(pt->id, j); if(p==NULL else { k=p; while(k!=NULL && strcmp(pt->id,k->id)>=0) { f=k; k=k->next; } f->next=pt; pt->next=k; } return p; } void print(struct spisok *p) { struct spisok *pt; for(pt=p;pt!=NULL;pt=pt->next) puts(pt->id); } struct spisok* udalenie(struct spisok *p) { char j[8]; struct spisok *pt,*f,*k; printf("vvedite identificator kotorii nugno udalit\n"); gets(j); pt=p; f=p; while(pt->next!=NULL) { k=pt->next; if(!strcmp(j,pt->id)) f->next=k; if(pt!=p) f->next=pt; pt=pt->next; } return p; }
Односвязные списки. Удаление элемента?
Есть ли способ удалить элемент из односвязного списка за О(1)? При условии, что у нас есть указатель на удаляемый элемент.
За О(n) с поиском такое сделать не проблема, а как без него за О(1)?
- Вопрос задан более двух лет назад
- 593 просмотра
3 комментария
Простой 3 комментария

а как вы поменяете ссылку на этот объект у того объекта, который ссылается на текущий на найдя его?

Apathy666 @Apathy666 Автор вопроса
Максим Федоров, вот в этом то и проблема, что не знаю как эту ссылку поменять. Значит нет способа, чтобы за О(1)?
Apathy666, при такой постановке и таких ограничениях — нет
Решения вопроса 1
Wataru @wataru Куратор тега Алгоритмы
Разработчик на С++, экс-олимпиадник.
Только если вам известен ПРЕДЫДУЩИЙ элемент. Иначе за честные О(1) вы из односвязного списка ничего не удалите.
Можно амортизационно удалить за О(1) просто пометив этот элемент удаленным. Но тогда все функции, которые проходятся по списку, должны такие помеченные элементы действительно удалять во время прохода.
Суммарное время работы алгоритма будет как если бы удаление было за О(1). Но некоторые отдельные операции могут быть сильно медленнее, чем при честной константе. Например, если вы кучу раз добавите элемент в начало списка и тут же удалите, то потом вывод списка будет медленным, несмотря на то, что список должен быть пустым.
Но на практике этот метод, наверно, не применяется. Потому что вы же где-то берете указатель на удаляемый элемент. Обычно можно вместе с ним получать и указатель на предыдущий. Или тупо использовать двусвязные списки.
Односвязный линейный список

Каждый узел однонаправленного (односвязного) линейного списка (ОЛС) содержит одно поле указателя на следующий узел. Поле указателя последнего узла содержит нулевое значение (указывает на NULL).
Узел ОЛС можно представить в виде структуры
struct list
int field; // поле данных
struct list *ptr; // указатель на следующий элемент
>;
Основные действия, производимые над элементами ОЛС:
- Инициализация списка
- Добавление узла в список
- Удаление узла из списка
- Удаление корня списка
- Вывод элементов списка
- Взаимообмен двух узлов списка
Инициализация ОЛС

Инициализация списка предназначена для создания корневого узла списка, у которого поле указателя на следующий элемент содержит нулевое значение.
struct list * init( int a) // а- значение первого узла
struct list *lst;
// выделение памяти под корень списка
lst = ( struct list*)malloc( sizeof ( struct list));
lst->field = a;
lst->ptr = NULL ; // это последний узел списка
return (lst);
>
Добавление узла в ОЛС
Функция добавления узла в список принимает два аргумента:
- Указатель на узел, после которого происходит добавление
- Данные для добавляемого узла.

Процедуру добавления узла можно отобразить следующей схемой:
Добавление узла в ОЛС включает в себя следующие этапы:
- создание добавляемого узла и заполнение его поля данных;
- переустановка указателя узла, предшествующего добавляемому, на добавляемый узел;
- установка указателя добавляемого узла на следующий узел (тот, на который указывал предшествующий узел).
Таким образом, функция добавления узла в ОЛС имеет вид:
1
2
3
4
5
6
7
8
9
10
struct list * addelem(list *lst, int number)
struct list *temp, *p;
temp = ( struct list*)malloc( sizeof (list));
p = lst->ptr; // сохранение указателя на следующий узел
lst->ptr = temp; // предыдущий узел указывает на создаваемый
temp->field = number; // сохранение поля данных добавляемого узла
temp->ptr = p; // созданный узел указывает на следующий элемент
return (temp);
>
Возвращаемым значением функции является адрес добавленного узла.
Удаление узла ОЛС
В качестве аргументов функции удаления элемента ОЛС передаются указатель на удаляемый узел, а также указатель на корень списка.
Функция возвращает указатель на узел, следующий за удаляемым.

Удаление узла может быть представлено следующей схемой:
Удаление узла ОЛС включает в себя следующие этапы:
- установка указателя предыдущего узла на узел, следующий за удаляемым;
- освобождение памяти удаляемого узла.
1
2
3
4
5
6
7
8
9
10
11
12
struct list * deletelem(list *lst, list *root)
struct list *temp;
temp = root;
while (temp->ptr != lst) // просматриваем список начиная с корня
< // пока не найдем узел, предшествующий lst
temp = temp->ptr;
>
temp->ptr = lst->ptr; // переставляем указатель
free(lst); // освобождаем память удаляемого узла
return (temp);
>
Удаление корня списка
Функция удаления корня списка в качестве аргумента получает указатель на текущий корень списка. Возвращаемым значением будет новый корень списка — тот узел, на который указывает удаляемый корень.
struct list * deletehead(list *root)
struct list *temp;
temp = root->ptr;
free(root); // освобождение памяти текущего корня
return (temp); // новый корень списка
>
Вывод элементов списка
В качестве аргумента в функцию вывода элементов передается указатель на корень списка.
Функция осуществляет последовательный обход всех узлов с выводом их значений.
void listprint(list *lst)
struct list *p;
p = lst;
do printf( «%d » , p->field); // вывод значения элемента p
p = p->ptr; // переход к следующему узлу
> while (p != NULL );
>
Взаимообмен узлов ОЛС
В качестве аргументов функция взаимообмена ОЛС принимает два указателя на обмениваемые узлы, а также указатель на корень списка. Функция возвращает адрес корневого элемента списка.
Взаимообмен узлов списка осуществляется путем переустановки указателей. Для этого необходимо определить предшествующий и последующий узлы для каждого заменяемого. При этом возможны две ситуации:
- заменяемые узлы являются соседями;
- заменяемые узлы не являются соседями, то есть между ними имеется хотя бы один элемент.
При замене соседних узлов переустановка указателей выглядит следующим образом: 
При замене узлов, не являющихся соседними переустановка указателей выглядит следующим образом: 
При переустановке указателей необходима также проверка, является ли какой-либо из заменяемых узлов корнем списка, поскольку в этом случае не существует узла, предшествующего корневому.
Функция взаимообмена узлов списка выглядит следующим образом:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
struct list * swap( struct list *lst1, struct list *lst2, struct list *head)
// Возвращает новый корень списка
struct list *prev1, *prev2, *next1, *next2;
prev1 = head;
prev2 = head;
if (prev1 == lst1)
prev1 = NULL ;
else
while (prev1->ptr != lst1) // поиск узла предшествующего lst1
prev1 = prev1->ptr;
if (prev2 == lst2)
prev2 = NULL ;
else
while (prev2->ptr != lst2) // поиск узла предшествующего lst2
prev2 = prev2->ptr;
next1 = lst1->ptr; // узел следующий за lst1
next2 = lst2->ptr; // узел следующий за lst2
if (lst2 == next1)
< // обмениваются соседние узлы
lst2->ptr = lst1;
lst1->ptr = next2;
if (lst1 != head)
prev1->ptr = lst2;
>
else
if (lst1 == next2)
// обмениваются соседние узлы
lst1->ptr = lst2;
lst2->ptr = next1;
if (lst2 != head)
prev2->ptr = lst2;
>
else
// обмениваются отстоящие узлы
if (lst1 != head)
prev1->ptr = lst2;
lst2->ptr = next1;
if (lst2 != head)
prev2->ptr = lst1;
lst1->ptr = next2;
>
if (lst1 == head)
return (lst2);
if (lst2 == head)
return (lst1);
return (head);
>
Структуры данных
Связный список (Linked List) представляет набор связанных узлов, каждый из которых хранит собственно данные и ссылку на следующий узел. В реальной жизни связный список можно представить в виде поезда, каждый вагон которого может содержать некоторый груз или пассажиров и при этом может быть связан с другим вагоном.
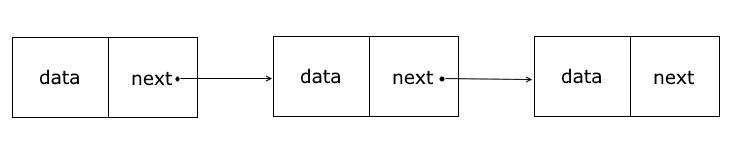
Таким образом, если в массиве положение элементов определяется индексами, то в связном списке — указателями на следующий и (или) на предыдущий элемент.
Связные списки могут различаться. Есть односвязные списки, в которых каждый узел хранит указатель только на следующий узел. Есть двусвязные списки: в них каждый элемент хранит ссылку как на следующий элемент, так и на предыдущий. Есть кольцевые замкнутые списки. В данном случае мы рассмотрим создание односвязного списка.
Перед созданием списка нам надо определить класс узла, который будет представлять одиночный объект в списке:
public class Node < public Node(T data) < Data = data; >public T Data < get; set; >public Node? Next < get; set; >>
Класс Node является обобщенным, поэтому может хранить данные любого типа. Для хранения данных предназначено свойство Data . Для ссылки на следующий узел определено свойство Next .
Далее определим сам класс списка:
using System.Collections; using System.Collections.Generic; public class LinkedList : IEnumerable // односвязный список < Node? head; // головной/первый элемент Node? tail; // последний/хвостовой элемент int count; // количество элементов в списке // добавление элемента public void Add(T data) < Nodenode = new Node(data); if (head == null) head = node; else tail!.Next = node; tail = node; count++; > // удаление элемента public bool Remove(T data) < Node? current = head; Node? previous = null; while (current != null && current.Data != null) < if (current.Data.Equals(data)) < // Если узел в середине или в конце if (previous != null) < // убираем узел current, теперь previous ссылается не на current, а на current.Next previous.Next = current.Next; // Если current.Next не установлен, значит узел последний, // изменяем переменную tail if (current.Next == null) tail = previous; >else < // если удаляется первый элемент // переустанавливаем значение head head = head?.Next; // если после удаления список пуст, сбрасываем tail if (head == null) tail = null; >count--; return true; > previous = current; current = current.Next; > return false; > public int Count < get < return count; >> public bool IsEmpty < get < return count == 0; >> // очистка списка public void Clear() < head = null; tail = null; count = 0; >// содержит ли список элемент public bool Contains(T data) < Node? current = head; while (current != null && current.Data !=null) < if (current.Data.Equals(data)) return true; current = current.Next; >return false; > // добвление в начало public void AppendFirst(T data) < Nodenode = new Node(data); node.Next = head; head = node; if (count == 0) tail = head; count++; > IEnumerator IEnumerable.GetEnumerator() < Node? current = head; while (current != null) < yield return current.Data; current = current.Next; >> // реализация интерфейса IEnumerable IEnumerator IEnumerable.GetEnumerator() < return ((IEnumerable)this).GetEnumerator(); > >
Разберем основные моменты. В зависимости от конкретных задач реализация списков может отличаться, но для всех реализаций характерны прежде всего два метода: добавление и удаление.
Но прежде чем выполнять различные операции с данными, в классе списка определяются три переменные:
Node? head; // головной/первый элемент Node? tail; // последний/хвостовой элемент int count; // количество элементов в списке
public void Add(T data) < Nodenode = new Node(data); if (head == null) head = node; else tail!.Next = node; tail = node; count++; >
Если у нас не установлена переменная head (то есть список пуст), то устанавливаем head и tail. После добавления первого элемента они будут указывать на один и тот же объект.
Если же в списке есть как минимум один элемент, то устанавливаем свойство tail.Next — теперь оно хранит ссылку на новый узел. И переустанавливаем tail — теперь она ссылается на новый узел.
Сложность данного метода составляет O(1) . Графически это выглядит так:
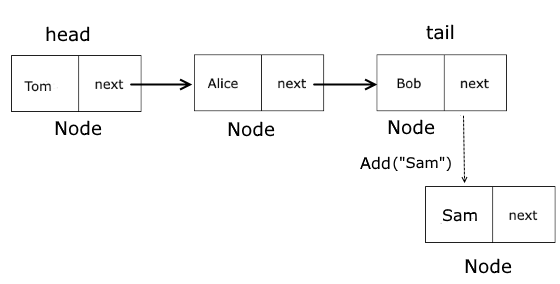
Важно отметить наличие переменной tail, которая указывает на последний элемент. Ряд реализаций не используют подобную переменную и добавляют иным образом:
public void AddWithoutTail(T data) < Nodenode = new Node(data); if (head == null) < head = node; >else < Nodecurrent = head; // ищем последний элемент while (current.Next!=null) < current = current.Next; >//устанавливаем последний элемент current.Next = node; > count++; >
Данный способ вполне рабочий и нередко встречается, однако необходимость перебора элементов для нахождения последнего увеличивает время на поиск и сложность алгоритма. Она равна O(n) .
Особняком стоит метод добавления в начало списка, где нам достаточно переустановить ссылку на головной элемент:
public void AppendFirst(T data) < Nodenode = new Node(data); node.Next = head; head = node; if (count == 0) tail = head; count++; >
public bool Remove(T data) < Node? current = head; Node? previous = null; while (current != null && current.Data != null) < if (current.Data.Equals(data)) < // Если узел в середине или в конце if (previous != null) < // убираем узел current, теперь previous ссылается не на current, а на current.Next previous.Next = current.Next; // Если current.Next не установлен, значит узел последний, // изменяем переменную tail if (current.Next == null) tail = previous; >else < // если удаляется первый элемент // переустанавливаем значение head head = head?.Next; // если после удаления список пуст, сбрасываем tail if (head == null) tail = null; >count--; return true; > previous = current; current = current.Next; > return false; >
Алгоритм удаления элемента представляет следующую последовательность шагов:
- Поиск элемента в списке путем перебора всех элементов
- Установка свойства Next у предыдущего узла (по отношению к удаляемому) на следующий узел по отношению к удаляемому.
Для отслеживания предыдущего узла применяется переменная previous . Если элемент найден, и переменная previous равна null, то удаление идет сначала, и в этом случае происходит переустановка переменной head, то есть головного элемента.
Если же previous не равна null, то реализуются шаги выше описанного алгоритма.
Сложность такого алгоритма составляет O(n) . Графически удаление можно представить так:
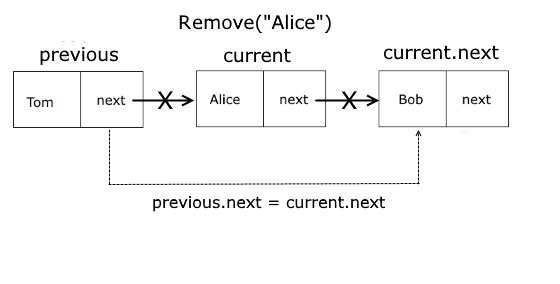
Чтобы проверить наличие элемента, исползуется метод Contains:
public bool Contains(T data) < Node? current = head; while (current != null && current.Data !=null) < if (current.Data.Equals(data)) return true; current = current.Next; >return false; >
Здесь опять же просто осуществляется перебор. Сложность алгоритма метода составляет O(n) .
И для того, чтобы список можно было бы перебрать во внешней прграмме с помощью цикла for-each, класс списка реализует интерфейс IEnumerable :
// реализация интерфейса IEnumerable IEnumerator IEnumerable.GetEnumerator() < return ((IEnumerable)this).GetEnumerator(); > IEnumerator IEnumerable.GetEnumerator() < Node? current = head; while (current != null) < yield return current.Data; current = current.Next; >>
Реализация данного интерфейса не является неотъемлимой частью односвязных списков, однако предоставляет эффективный метод для перебора коллекции в цикле foreach. Иначе нам бы пришлось реализовать какие-то собственные конструкции по перебору списка.
LinkedList linkedList = new LinkedList < // добавление элементов "Tom", "Alice", "Bob", "Sam" >; // выводим элементы foreach (var item in linkedList) < Console.WriteLine(item); >// удаляем элемент linkedList.Remove("Alice"); Console.WriteLine("\nПосле удаления Alice"); foreach (var item in linkedList) Console.WriteLine(item); // проверяем наличие элемента bool isPresent = linkedList.Contains("Sam"); Console.WriteLine(isPresent ? "Sam присутствует" : "Sam отсутствует"); // добавляем элемент в начало linkedList.AppendFirst("Bill"); Console.WriteLine("\nПосле добавления Billa"); foreach (var item in linkedList) Console.WriteLine(item);
Tom Alice Bob Sam После удаления Alice Tom Bob Sam Sam присутствует После добавления Billa Bill Tom Bob Sam