Как я html-парсер на php писал, и что из этого вышло. Вводная часть
Сегодня я хочу рассказать, как написать html парсер, а также с какими проблемами я столкнулся, разрабатывая подобный парсер на php. А проблем было много. И в первой части я расскажу о проектировании парсера, и о возникших проблемах, ведь html парсер отличается от парсера привычных всем языков программирования.
Введение
Я старался написать текст этой статьи максимально понятно, чтобы любой, кто даже не знаком с общим устройством парсеров мог понять то, как работает html парсер.
Здесь и далее в статье я буду называть документ, содержащий html просто «Документ».
Dom дерево, находящееся в элементе, будет называться «Подмассив».
Что должен делать парсер?
Давайте сначала определимся, что должен делать парсер, чтобы в будущем отталкиваться от этого при разработке. А именно, парсер должен:
- Проектировать dom-дерево на основе документа
- Если есть ошибки в документе, то он должен их решать
- Находить элементы в dom-дереве
- Находить children элементы
- Находить текст
Впрочем, это мелочи. Основного функционала вполне хватит, чтобы поломать голову пару ночей напролет.
Но тут есть проблема, с которой я столкнулся сразу же: Html — это не просто язык, это язык гипертекста. У такого языка свой синтаксис, и обычный парсер не подойдет.
Разделяй и властвуй
Для начала, нужно разделить работу парсера на два этапа:
- Отделение обычного текста от тегов
- Сортировка всех полученных тегов в dom дерево
Для описания первого этапа я нарисовал схему, которая наглядно показывает, как обрабатываются данные на первом этапе:
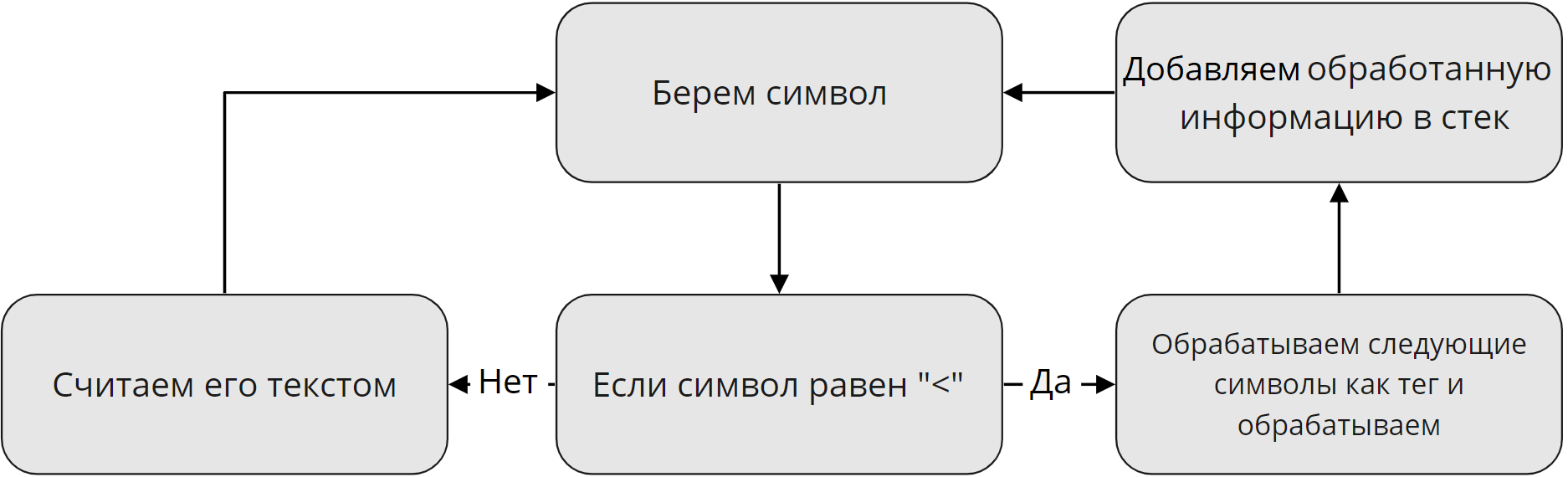
Я решил опустить все мелкие детали. Например, как отличить, что после открывающего »
Также тут стоит уточнить. Логично, что в документе помимо тегов есть еще и текст. Говоря простым языком, если парсер найдет открывающий тег и если в нем будет текст, он запишет его после открывающего тега в виде отдельного тега. Такой тег будет считаться как одиночный и не будет участвовать в дальнейшей работе парсера.
Ну и второй этап. Самый сложный с точки зрения проектирования, и самый простой на первый взгляд с точки зрения понимания:
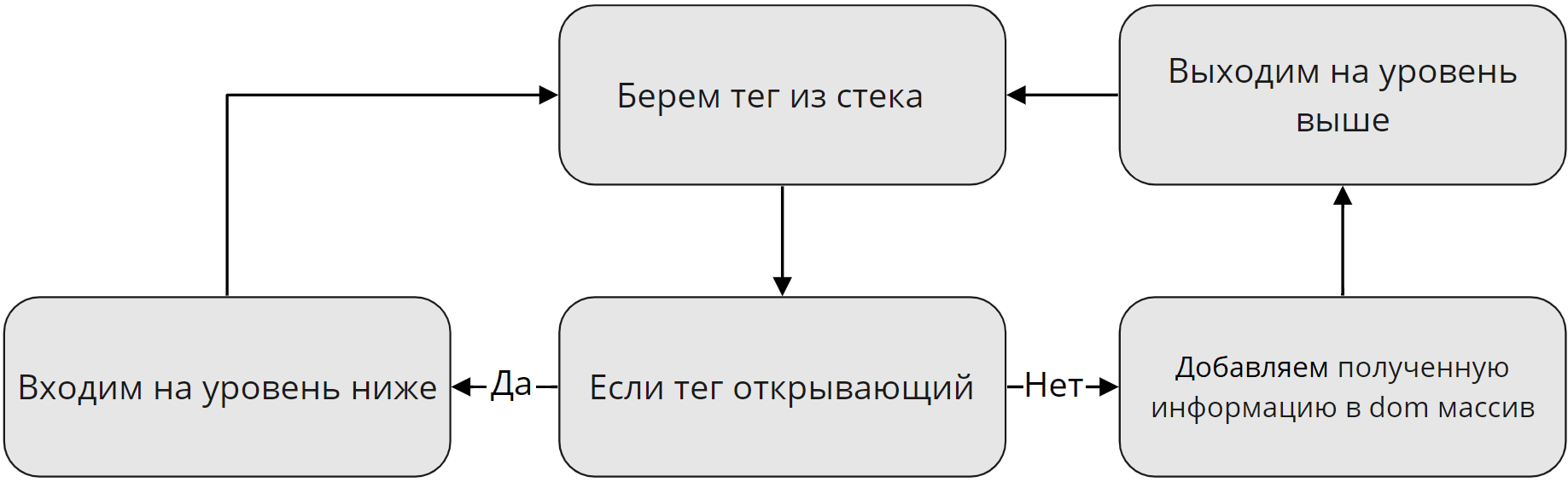
В данном случаи уровень означает уровень рекурсии. То есть если парсер нашел открывающий тег, он вызывает самого себя, «входит на уровень ниже», и так будет продолжаться до тех пор, пока не будет найден закрывающий тег. В этом случаи рекурсия выдает результат, «Выходит на уровень выше». Но, как обстоят дела с одиночными тегами? Такие теги считаются рекурсией ни как открывающие, ни как закрывающие. Они просто переходят в dom «Как есть».
В итоге у нас получится что-то вроде этого:
[0] => Array ( [is_closing] => [is_singleton] => [pointer] => 215 [tag] => div [0] => Array //открывается подмассив ( [0] => Array ( [is_closing] => [is_singleton] => [pointer] => 238 [tag] => div [id] => Array ( [0] => tjojo ) [0] => Array //открывается подмассив ( [0] => Array //Текст записывается в виде отдельного тега ( [tag] => __TEXT [0] => Привет! ) [1] => Array ( [is_closing] => 1 [is_singleton] => [pointer] => 268 [tag] => div ) ) ) ) )
Что там насчет поиска элементов?
А теперь давайте поговорим про поиск элементов. Но тут не все так однозначно, как можно подумать. Сначала стоит разобраться, по каким критериям мы ищем элементы. Тут все просто, мы ищем их по тем же критериям, как это делает Javascript: теги, классы и идентификаторы. Но тут проблема. Дело в том, что тег может быть только один, а вот классов и идентификаторов у одного элемента — множество, либо вообще не быть. Поэтому, поиск элемента по тегу будет отличаться от поиска по классу или идентификатору. Я нарисовал схему поиска по тегу, но не волнуйтесь: поиск по классу или идентификатору не особо отличаются.
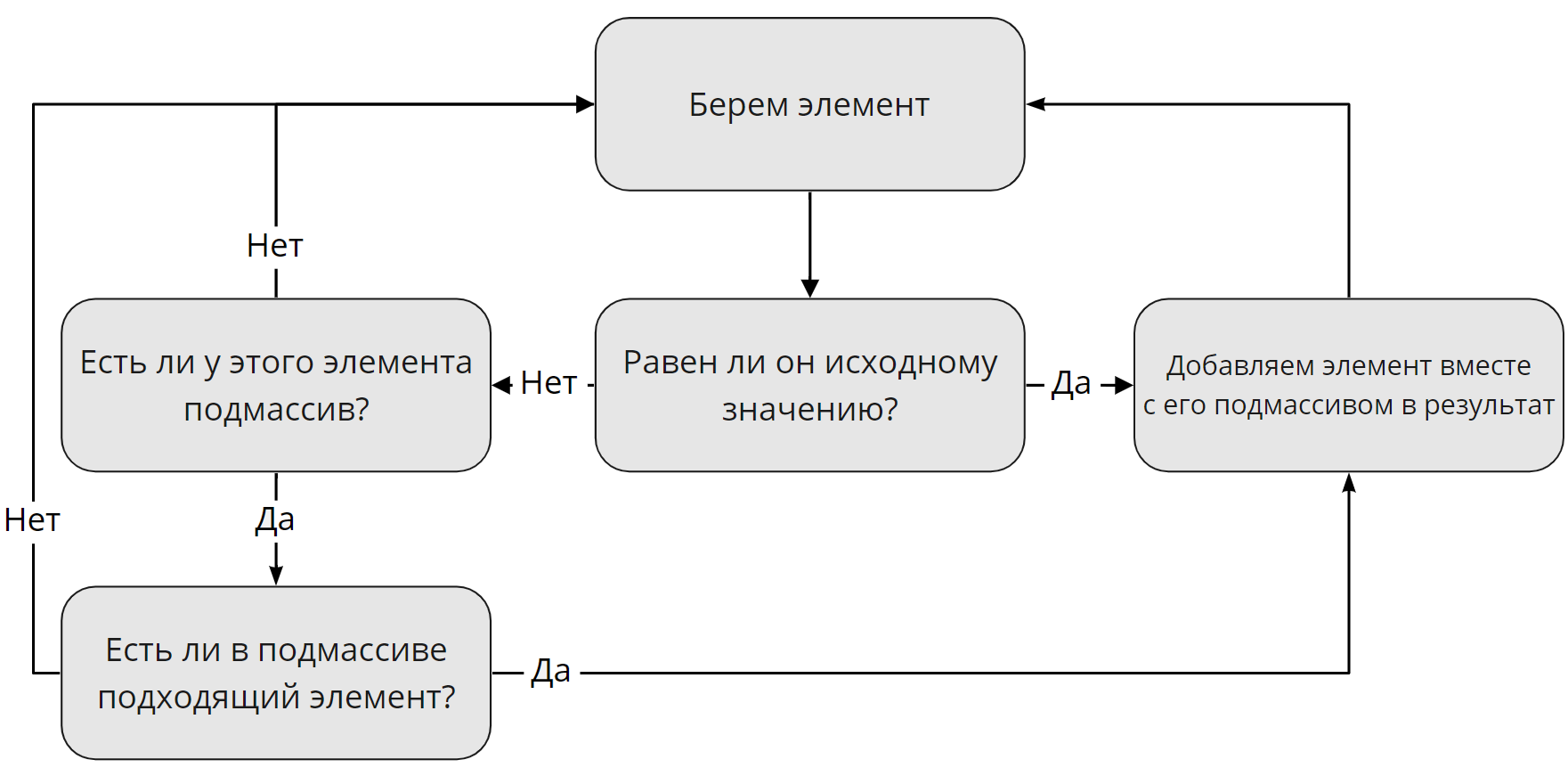
Немного уточнений. Под исходным значением я имел в виду название тега, «div» например. Также, если элемент не равен исходному значению, но у него есть подмассив с подходящим элементом, в результат запишется именно подходящий элемент с его подмассивом, если таковой существует.
Стоит также сказать, что у парсера будет функция, позволяющая искать определенный элемент в документе. Это заметно ускорит производительность парсера, что позволит ему выполняться быстрее. Можно будет, например, взять только первый найденный элемент, или пятый, как вы захотите. Согласитесь, в таком случаи парсеру будет гораздо проще искать элементы.
Поиск children элементов
Хорошо, с поиском элементов разобрались, а как насчет children элементов? Тут тоже все просто: наш парсер будет брать все вложенные подмассивы найденных до этого элементов, если таковые существуют. Если таковых нет, парсер выведет пустой результат и пойдет дальше:
![]()
Поиск текста
Тут говорить особо не о чем. Парсер просто будет брать весь полученный текст из подмассива и выводить его.
Ошибки
Документ может содержать ошибки, с которыми наш скрипт должен успешно справляться, либо, если ошибка критическая, выводить ее на экран. Тут будет приведен список всех возможных ошибок, о которых, в будущем, мы будем говорить:
- Символ «>» не был найден
Такая ошибка будет возникать в том случаи, если парсер дошел до конца документа и не нашел закрывающего символа «>». - Неизвестное значение атрибута
Данная ошибка сигнализирует о том, что была проведена попытка передачи значения атрибуту когда закрывающий тег был найден.
Script, style и комментарии
В парсере теги script и style будут сразу же пропускаться, поскольку я не вижу смысл их записывать. С комментариями ситуация другая. Если вы захотите из записывать, то вы сможете включить отдельную функцию скрипта, и тогда он будет их записывать. Комментарии будут записываться точно так же как и текст, то есть как отдельный тег.
Заключение
Эту статью скорее нужно считать небольшим экскурсом в тему парсеров html. Я ее написал для тех, кто задумывается над написанием своего парсера, либо для тех, кому просто интересно. Поверьте, это действительно весело!
Данная статья является первой вводной частью. В следующих частях этого цикла уже будет участвовать непосредственно код, и будет меньше картинок с алгоритмами(что прекрасно, потому что рисовать я их не умею). Stay tuned!
Парсер на PHP – это просто
Вебмастеры часто сталкиваются с такой проблемой, когда нужно взять с какого-либо сайта определенную информацию и перенести ее на другой. Можно сначала сохранить информацию на промежуточный носитель, а уже с него загрузить куда-либо, но подобный подход не всегда удобен. В некоторых случаях гораздо быстрее залить парсер на сам сайт, поддерживающий PHP и запустить его удаленно, чтобы он автоматически спарсил информацию и загрузил ее в базу данных ресурса.
Среди уже готовых решений имеются популярные вроде Content Downloader и ZennoPoster, они конечно очень удобны и понятны любому человеку, даже незнакомому с программированием, однако имеют некоторые минусы. К примеру, они платные и не обладают достаточной гибкостью, которую можно вдохнуть в обычный php скрипт. Тем более, что разработка сложного парсера на них нисколько не уступает по времени написанию аналога на php.
Еще есть такая бесплатная вещь как iMacros – скриптовый язык, который может эмулировать действия пользователя в браузере, но тоже не везде такой подход работает лучшим образом.
Многие думают, что программирование, и уж тем более написание парсеров, – очень сложное занятие. На самом деле php – один из самых простых языков, изучить который можно на достаточном уровне за пару недель или месяц.
Парсеры тоже просты в написании, именно поэтому начинающие программисты пишут именно их, чтобы освоить язык.
Первое, что приходит на ум человеку, который решил написать подобный скрипт, — нужно использовать функции для работы со строками (strpos, substr и аналогичные) или регулярные выражения. Это совершенно верно, однако есть один нюанс. Если парсеров нужно будет писать много, то придется разрабатывать свою библиотеку, чтобы не переписывать сто раз одни и те же конструкции, но на это уйдет тонна времени, а учитывая то, что уже существуют аналогичные библиотеки, такое занятие и вовсе оказывается бессмысленным.
Идеальным вариантом для новичка станет изучение библиотеки PHP Simple HTML DOM Parser. Как можно догадаться из названия, она очень проста в освоении. Рассмотрим базовый код:
$html = file_get_html(‘http://www.yandex.ru’);
$a_links = $html->find(‘a’);
Первая строка создает объект страницы, источником которой в данном случае является Яндекс, и записывает в переменную $html, которая имеет несколько функций, например find. Find – ищет элемент по какому-либо параметру, например find (‘a’) – вернет массив всех ссылок страницы. Find(‘#myid’) – вернет массив элементов, id которых равен ‘myid’.
Доступ к параметру href первой попавшейся ссылки осуществляется так:
echo $a_links[ 0 ]->href;
Более подробно можно посмотреть на сайте:
simplehtmldom.sourceforge.net
Библиотека, как уже было сказано выше, очень проста и лучше всего подходит для начинающего программиста, плюс ко всему она работает достаточно быстро и не сильно требовательна к ресурсам сервера.
Есть у этой библиотеки один минус – далеко не все страницы ей оказываются по зубам. Если какой-либо элемент не отображается, но точно известно, что он там есть, лучше воспользоваться библиотекой DOM (Document Object Model). Она хороша во всем, кроме скорости разработки и понятности.
$doc = new DOMDocument();
$doc->loadHTML ( $data );
$searchNodes = $doc->getElementsByTagName( «a» );
echo $searchNodes[ 0 ]->getAttribute( ‘href’ );
Этот скрипт создает сначала объект типа DOM, при этом в переменной $data должен находиться код страницы. Затем находит все теги a (ссылки), с помощью вызова $doc->getElementsByTagName, затем записывает их в массив $searchNodes. Доступ к параметру href первой ссылки на странице осуществляется с помощью вызова $searchNodes[ 0 ]->getAttribute( ‘href’ ).
В итоге скрипт получается более громоздкий, и писать его уже не так удобно, но иногда приходится использовать именно эту библиотеку.
Парсинг страниц сайтов(html-контента) на php.
Заметка посвящается парсингу, в частности парсинг сайтов, парсинг страниц, парсинг в веб-среде, парсинг html-контента сайта. В процессе разработки различных веб-сервисов очень часто приходится сталкиваться с задачами, в которых требуется быстро получить различного рода информацию в больших объемах. В основном это связано с граббингом, кражей информации, как хотите это называйте. Дело в том, что информация доступна и открыта. Особенность парсинга — это быстрый и автоматизированный сбор данных, контента со страниц сайта. Сейчас очень популярно парсить в веб-среде, а именно парсить сайта, который содержать хоть какую-нибудь ценность и актуальность для людей. Особой ценностью является каталог товаров, включая картинки, базы данных справочников и многое другое, что может пригодиться для конкурентов. Давайте попробуем спарсить нужную информацию в html, попробуем достать все ссылки с нескольких страниц нашего сайта. Для начала нам необходимо получить контент сайта в формате html. Для этого нам достаточно знать адреса нужных страниц. Хочу показать 2 основных способа получения контента со страницы сайта: В первую очередь приготовим массив с нужными адресами страниц:
//3 ссылки нашего сайта: $urls = array('http://hello-site.ru/blog/','http://hello-site.ru/web-notes/','http://hello-site.ru/games/');
1 вариант — php функция file_get_contents. Функция возвращает html-строку, которую мы будем парсить на ссылки:
//помещаем каждую ссылку в функцию file_get_contents foreach($urls as $urlsItem) < $out .= file_get_contents($urlsItem); //и добавляем содержание каждой страницы в строку >echo $out; //здесь контент всех трех страниц
2 вариант — CURL. Библиотека, которая поддерживается php и имеет большой набор настроек, от POST-запросов до работы с FTP. Рассмотрим стандартный вызов библиотеки curl, который отдаст нам контент сайта:
foreach($urls as $urlsItem) < //пропускаем каждую ссылку в цикле $output = curl_init(); //подключаем курл curl_setopt($output, CURLOPT_URL, $urlsItem); //отправляем адрес страницы curl_setopt($output, CURLOPT_RETURNTRANSFER, 1); curl_setopt($output, CURLOPT_HEADER, 0); $out .= curl_exec($output); //помещаем html-контент в строку curl_close($output); //закрываем подключение >echo $out; //здесь контент всех трех страниц
Теперь в нашей строке $out находится контент всех трех страниц. Итак, переходим непосредственно к парсингу нашей строки. Опять же хочу показать 3 варианта решения нашей задачи: «нативный» способ на php, с помощью встроенной библиотеки DOMDocument и библиотеки SimpleHTMLDOM. 1. php функция explode. Функция находит искомый символ или часть строки и делит целую строку на элементы массива. Повторюсь, нам необходимо получить значения всех атрибутов href у тегов a, для этого будем делить общую строку на некоторые части\отрезки:
// explode $hrefs = explode(' foreach($hrefText as $hrefTextItem) < //избавляемся от ссылок с пустым атрибутом href if($hrefTextItem!='')< $clearHrefs[]=$hrefTextItem; >> $clearHrefs = array_unique($clearHrefs); //избавляемся от одинаковых ссылок print_r($clearHrefs); // в итоге у нас массив со всем ссылками с 3х страниц
Если распечатать наш массив, будет примерно следующее:
Array ( [0] => / [1] => /hello [3] => /timer/ [4] => /leftmenu/ [5] => /faq/ [6] => /blog/ [8] => /web-notes/ [9] => /ordersite/ [10] => /games )
2. встроенная библиотека DOMDocument. Работаем с классом примерно следующим образом:
//domelement $dom = new DOMDocument; //создаем объект $dom->loadHTML($out); //загружаем контент $node = $dom->getElementsByTagName('a'); //берем все теги a for ($i = 0; $i < $node->length; $i++) < $hrefText[] = $node->item($i)->getAttribute('href'); //вытаскиваем из тега атрибут href > foreach($hrefText as $hrefTextItem) < //избавляемся от ссылок с пустым атрибутом href if($hrefTextItem!='')< $clearHrefs[]=$hrefTextItem; >> $clearHrefs = array_unique($clearHrefs); //избавляемся от одинаковых ссылок print_r($clearHrefs); // в итоге у нас массив со всем ссылками с 3х страниц
Результат такого кода ровно такой же, что и с помощью функции explode. 3. библиотека SimpleHTMLDOM. Ее необходимо подключать из файла. Работа примерно схожа с DOMDocument. Работаем с классом:
//simplehtml include('simple_html_dom.php'); //подключаем файл с классом SimpleHTMLDOM $html = new simple_html_dom(); //создаем объект $html->load($out); //помещаем наш контент $collection = $html->find('a'); //собираем все теги a foreach($collection as $collectionItem) < $articles[] = $collectionItem->attr; //массив всех атрибутов, href в том числе > foreach($articles as $articlesItem) < $hrefText[] = $articlesItem['href']; //собираем в массив значения подмассива с ключом href >foreach($hrefText as $hrefTextItem) < //избавляемся от ссылок с пустым атрибутом href if($hrefTextItem!='')< $clearHrefs[]=$hrefTextItem; >> $clearHrefs = array_unique($clearHrefs); //избавляемся от одинаковых ссылок print_r($clearHrefs); // в итоге у нас массив со всем ссылками с 3х страниц
Повторюсь, результат в массив ровно такой же как и выше в двух вышеперечисленных. Теперь, имея массив со всеми ссылками, собранными с трех страниц сайта, можно отправить ссылки в нужное русло, все зависит от задачи и фантазии. Имея такие возможности, можно спарсить большое количество данных самого разного вида информации, картинки, тексты, логи и т.д. Чужая информация в ваших руках, распоряжайтесь как вам угодно, но сами защищайтесь, хотя это невозможно) Успехов!
Парсинг в PHP: что нужно знать новичкам
Серверная разработка требует от программиста определенного спектра знаний и навыков. Весьма полезным покажется парсер. Главное разобраться, каким образом его реализовать на PHP.
Статья расскажет о том, что такое парсинг, для чего он нужен и как функционирует. В ней будут приведены наглядные примеры, которые пригодятся для любого URL при веб-разработке.
Parsing – это…
Парсер – программное обеспечение, которое осуществляет анализ входных текстовых сведений. После этого занимается извлечением необходимой информации, на основе которых будет производиться результат в заранее заданном формате.
На PHP parser работает так:
- скрипт создает запрос по URL;
- осуществляется получение ответа от сервера в виде HTML или ином текстовом формате;
- сведения анализируются;
- из электронных материалов URL извлекаются (парсятся) нужные элементы;
- формируется и выводится результат.
Итог можно записывать в файлы и базы данных, а также непосредственно выводить на дисплей устройства.
Для чего необходим
При изучении парсеров в PHP стоит выяснить, для чего они вообще нужны. Подобное программное обеспечение:
- Автоматизируют информацию в пределах URL.
- Собирают и обрабатывают большие объемы данных.
- Сравнивают содержимое страниц с заданными параметрами. Пример – поисковые системы.
- Помогают организовывать спам-рассылку.
А еще парсером на PHP можно наполнять собственные веб-ресурсы «чужим» контентом. Подобные проекты стараются блокировать, но это не всегда выходит быстро.
Parser избавляет от перепечатывания информации однотипного характера. Пример – наполнение интернет-магазина тем или иным товаром.
Основа функционирования
Если мы парсим текст, не стоит думать, что парсер будет его читать. Соответствующее ПО:
- получает набор команд и инструкций от разработчика;
- считывает слова;
- сравнивает то, что обнаружено в Сети согласно заданным принципам.
Далее происходит непосредственная обработка. То, как робот ведет себя с информацией командной строки, носит название регулярного выражения. В русском языке также встречается в виде понятий «маски» и «шаблоны».
Для того, чтобы парсер воспринимал регулярные выражения, он должен быть составлен на языке, который поддерживает оные при использовании строк. PHP – один из вариантов, который пользуется спросом.
Регулярные выражения для URL прописываются через синтаксис Unix. Он уже устарел и редко применяется на практике при разработке софта. Но за счет свойств обратной совместимости по сей день Юникс задействован программистами и системными администраторами.
За счет Unix можно регулировать активность parsing. В зависимости от соответствующего значения будет меняться длина строки, копируемой с веб-страницы. Сверхжадный парсинг может считывать весь контент, а также HTML-кодификацию и внешние таблицы CSS.
Почему PHP
PHP – язык программирования, который используется для работы с веб-контентом. Позволяет создавать разнообразный софт: от бизнес-аналитики до игр. Его функции позволяют контактировать с парсерами максимально комфортно:
- Наличие библиотеки libcurl. Она отвечает за подключение скрипта ко всем видам серверов (даже при работе с http протоколами).
- Поддержка регулярных выражений. За их счет парсер осуществляет обработку информации.
- Наличие библиотеки DOM, используемой для работы с XML-расширяемым языком разметки текста. Он пригодится при выводе результатов обработки информации.
- Высокая совместимость с HTML.
При запуске URL сайта и внедрения парсера PHP станет настоящим спасением. Это не слишком сложный, но очень мощный язык.
Parse URL – особенности
Parse_url – функция, которая разбирает URL, а затем осуществляет возврат его компонентов. Применяется в PHP 4, 5, 7.
Стоит запомнить ее следующие особенности:
- mixed parse_url (string $url [int $component = -1]) – функция, которая разбирает URL и возвращает ассоциативный массив со всеми компонентами соответствующего адрес в Сети;
- не позволяет проверять корректность URL;
- разбивает адрес на части.
Parse_url старается разобрать частичные URL предельно корректно.
О параметрах
У рассматриваемой функции есть несколько параметров. Первый – URL.. Это – адрес для разбора. Символы, которые воспринимаются парсером как недопустимые, будут заменяться на подчеркивание.
Component – возможность считывания конкретного элемента адреса в виде строчки. Исключение – php_url_port. Этот вариант предусматривает возврат значения int.
Возвращаемые значения
Если URLs значительно некорректные, парсер может вернуть значение False. Когда component опускается, функция будет возвращать ассоциативный массив. В нем расположен хотя бы один элемент.
В массиве ассоциативного характера (array) могут встречаться такие ключи:
- scheme – пример: http;
- port;
- host;
- pass;
- user;
- query – после знака вопроса;
- fragment – после знака «решетка».
При определении component функция parse_url() вернет строчку или число вместо массива. Когда запрошенный элемент отсутствует в URL, «операция» возвращает значение null (пусто, ничего).
Наглядные примеры – CURL и phpQuery
Если нужно осуществить парсинг сайта, можно использовать для этого библиотеку CURL. Второй вариант – phpQuery, который представлен аналогом jQuery для PHP. Каждый подход имеет собственные преимущества.
Предварительная подготовка
Парсинг на сайте (ru) может быть проведен при помощи функции file_get_content. Помогает получить содержимое необходимой разработчику странички:

В качестве параметра используется желаемый адрес. Аналогичная функция помогает добавлять заголовки через потоковый контекст:
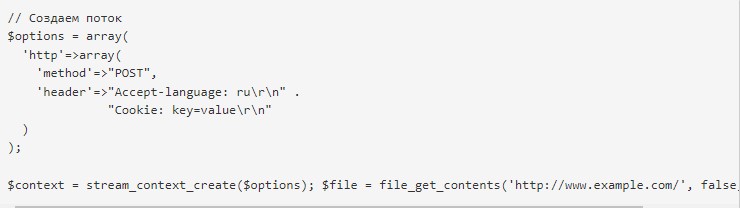
Для запуска соответствующего метода опция allow_url_fopen в php.ini должна быть активирована.
Второй вариант получения содержимого – через сокеты (pfsockopen). Но лучше использовать библиотеку php CURL.
CURL и парсинг
Теперь настало время запуска парсинга. Первый подход – с помощью CURL. Действовать предстоит следующим образом:
- Сначала требуется получить http страницы без параметров.
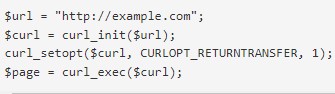
- Получение http странички с get-параметрами.
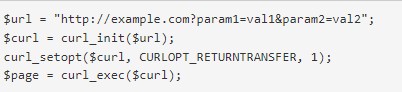
- Получение веб-ресурса по протоколам https.
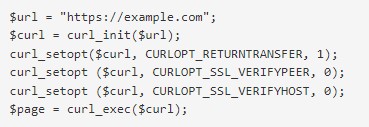
- Извлечение http, которая будет загружаться непосредственно через редиректы (следование 302).

- Нужно сформировать POST-запрос и отправить его. Делаются подобные операции через CURL.
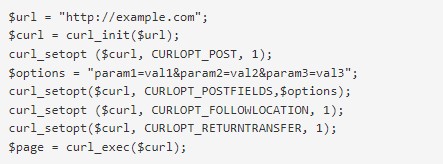
- Требуется активировать куки в запросе.
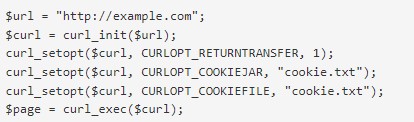
- В запросе GZIP активировать функцию сжатия. Требуется, когда тело ответа – это непонятный набор текста.
![]()
- Вывод заголовков ответов от сервера. Помогает при отладке. Пример – когда сервер не присылает правильное тело ответа или вовсе не дает его.
![]()
При парсинге огромную роль играют следующие параметры:

Первый будет всегда в «приложении». Остальные добавляются по мере необходимости. Параметр curlopt_header отвечает за поиск проблем. С ним наладить функционирование парсера php curl не составит никакого труда.
PhpQuery – принцип работы
Второй вариант применения парсинга – через phpQuery. Помогает тогда, когда страничка получена через CURL или иным методом.
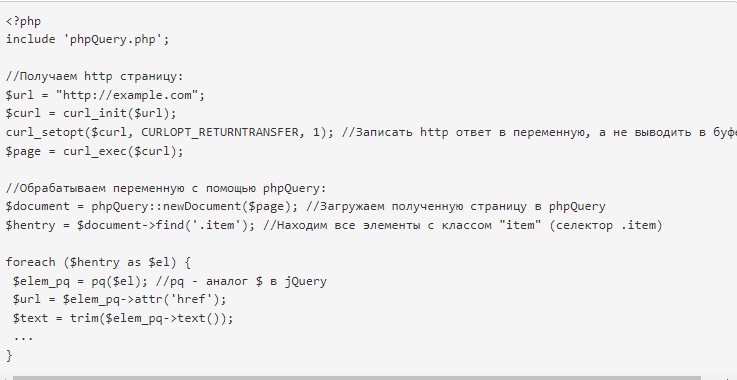
Код выше наглядно показывает, как создать парсер на php через phpQuery. Он выступает полноценным аналогом iQuery. Все функции соответствующей «возможности» прописаны в сопутствующей документации. По этой ссылке можно обнаружить селекторы и методы. А здесь – еще несколько кодов парсеров.
Быстрее освоиться в parsers, а также таких понятиях как print_r, echo, curl и других помогут специализированные дистанционные курсы. В срок от пары месяцев до года удастся освоить программирование «с нуля».