Строка в массив байтов, массив байтов в строку в Java
Сегодня мы узнаем, как преобразовать строку в массив байтов в java. Мы также узнаем, как преобразовать массив байтов в строку в Java.
Строка в байтовый массив
Мы можем использовать метод класса String getBytes() для кодирования строки в последовательность байтов, используя кодировку платформы по умолчанию. Этот метод перегружен, и мы также можем передать Charset в качестве аргумента. Вот простая программа, показывающая, как преобразовать строку в массив байтов в java.
package com.journaldev.util; import java.util.Arrays; public class StringToByteArray < public static void main(String[] args) < String str = "PANKAJ"; byte[] byteArr = str.getBytes(); // print the byte[] elements System.out.println("String to byte array: " + Arrays.toString(byteArr)); >> 
byte[] byteArr = str.getBytes("UTF-8"); Однако, если мы укажем имя набора символов, нам придется либо перехватывать исключение UnsupportedEncodingException , либо выбрасывать его. Лучшим подходом является использование класса StandardCharsets , представленного в Java 1.7, как показано ниже.
byte[] byteArr = str.getBytes(StandardCharsets.UTF_8); Вот и все способы преобразования строки в байтовый массив в java.
Массив байтов Java в строку
Давайте рассмотрим простую программу, показывающую, как преобразовать массив байтов в строку на Java.
package com.journaldev.util; public class ByteArrayToString < public static void main(String[] args) < byte[] byteArray = < 'P', 'A', 'N', 'K', 'A', 'J' >; byte[] byteArray1 = < 80, 65, 78, 75, 65, 74 >; String str = new String(byteArray); String str1 = new String(byteArray1); System.out.println(str); System.out.println(str1); > > 
String str = new String(byteArray, StandardCharsets.UTF_8); Класс String также имеет метод для преобразования подмножества массива байтов в строку.
byte[] byteArray1 = < 80, 65, 78, 75, 65, 74 >; String str = new String(byteArray1, 0, 3, StandardCharsets.UTF_8); Вышеприведенный код совершенно прекрасен, и значение «str» будет «PAN». Это все о преобразовании массива байтов в строку в Java.
Вы можете проверить больше примеров массивов из нашего репозитория GitHub.
Ссылка: документ API getBytes
Преобразование из String в массив байтов и обратно
Вопрос: так как кириллица в юникоде имеет кодепойнты, превышающие 1 тысячу (кодепойнт буквы А , к примеру, равен 1040), а байт в Java может принимать значения от -128 до 127, следовательно при попытке преобразовать строку в массив типа byte должна происходить потеря информации, как следствие — при вызове метода toString() строка должна восстановиться некорректно. Но этого не произошло. В чем тут причина?
Отслеживать
задан 28 ноя 2018 в 14:20
485 5 5 серебряных знаков 20 20 бронзовых знаков
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Это не юникод. String.getBytes() использует кодировку по-умолчанию платформы:
Encodes this String into a sequence of bytes using the platform’s default charset, storing the result into a new byte array.
Кодировка по-умолчанию задается настройками Java, ее можно проверить с помощью:
System.getProperty("file.encoding"); Для получения байтов в юникоде, задайте кодировку явно:
byte[] bytes="новая строка".getBytes("UTF-8"); Получится больше 12 байтов.
Обновление по вопросам в комментарии:
Разве UTF-8 выдает байты, эквивалентные юникодовскому представлению?
У юникода бывают разные представления. UTF-8 — одно из них.
Я знаю, что char выдает кодепойнты юникода. Если вывести System.out.println((byte)’н’), то это будет равно 61.
Здесь можно посмотреть как строчная кириллическая «н» представляется в разных кодировках: https://unicode-table.com/en/043D/
UTF-8:
Десятичное значение: 53437
Байты: 208 189UTF-16BE:
Десятичное значение: 1085
Байты: 4 61
Для char в Java, согласно спецификации (§3.1 Unicode) используется кодировка UTF-16. Это тоже двухбайтовая кодировка. Соответственно, когда Вы приводите char к byte Вы получаете младший байт в этой кодировке.
Получить байты в «UTF-16BE» можно так:
byte[] bytes="новая строка".getBytes("UTF-16BE"); Если вывести байты, как Вы предложили byte[] bytes=»новая строка».getBytes(«UTF-8»), то там первый байт равен -48, а не 61.
Кодировка UTF-8, как указано ранее беззнаковые (от 0 до 255) байты: 208 и 189. Знаковые байты, соответственно, -48 и -67.
[Перевод] Java Best Practices. Преобразование Char в Byte и обратно
Сайт Java Code Geeks изредка публикует посты в серии Java Best Practices — проверенные на production решения. Получив разрешение от автора, перевёл один из постов. Дальше — больше.
Продолжая серию статей о некоторых аспектах программирования на Java, мы коснёмся сегодня производительности String, особенно момент преобразования character в байт-последовательность и обратно в том случае, когда используется кодировка по умолчанию. В заключение мы приложим сравнение производительности между неклассическими и классическими подходами для преобразования символов в байт-последовательность и обратно.
Все изыскания базируются на проблемах в разработке крайне эффективных систем для задач в области телекоммуникации (ultra high performance production systems for the telecommunication industry).
Перед каждой из частей статьи очень рекомендуем ознакомиться с Java API для дополнительной информации и примеров кода.
Эксперименты проводились на Sony Vaio со следующими характеристиками:
ОС: openSUSE 11.1 (x86_64)
Процессор (CPU): Intel® Core(TM)2 Duo CPU T6670 @ 2.20GHz
Частота: 1,200.00 MHz
ОЗУ (RAM): 2.8 GB
Java: OpenJDK 1.6.0_0 64-Bit
Со следующими параметрами:
Одновременно тредов: 1
Количество итераций эксперимента: 1000000
Всего тестов: 100
Преобразование Char в Byte и обратно:
Задача преобразования Char в Byte и обратно широко распространена в области коммуникаций, где программист обязан обрабатывать байтовые последовательности, сериализовать String-и, реализовывать протоколы и т.д.
Для этого в Java существует набор инструментов.
Метод «getBytes(charsetName)» класса String, наверное, один из популярнейших инструментов для преобразования String в его байтовый эквивалент. Параметр charsetName указывает на кодировку String, в случае отсутствия оного метод кодирует String в последовательность байт используя стоящую в ОС по умолчанию кодировку.
Ещё одним классическим подходом к преобразованию массива символов в его байтовый эквивалент является использование класса ByteBuffer из пакета NIO (New Input Output).
Оба подхода популярны и, безусловно, достаточно просты в использовании, однако испытывают серьёзные проблемы с производительностью по сравнению с более специфическими методами. Помните: мы не конвертируем из одной кодировки в другую, для этого вы должны придерживаться «классических» подходов с использованием либо «String.getBytes (charsetName)» либо возможностей пакета NIO.
В случае ASCII мы имеем следующий код:
public static byte[] stringToBytesASCII(String str) < char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length]; for (int i = 0; i < b.length; i++) < b[i] = (byte) buffer[i]; >return b; > Массив b создаётся путём кастинга (casting) значения каждого символа в его байтовый эквивалент, при этом учитывая ASCII-диапазон (0-127) символов, каждый из которых занимает один байт.
Массив b можно преобразовать обратно в строку с помощью конструктора «new String(byte[])»:
System.out.println(new String(stringToBytesASCII("test"))); Для кодировки по умолчанию мы можем использовать следующий код:
public static byte[] stringToBytesUTFCustom(String str) < char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length >8); b[bpos + 1] = (byte) (buffer[i]&0x00FF); > return b; > Каждый символ в Java занимает 2 байта, для преобразования строки в байтовый эквивалент нужно перевести каждый символ строки в его двухбайтовый эквивалент.
И обратно в строку:
public static String bytesToStringUTFCustom(byte[] bytes) < char[] buffer = new char[bytes.length >> 1]; for(int i = 0; i < buffer.length; i++) < int bpos = i return new String(buffer); > Мы восстанавливаем каждый символ строки из его двухбайтового эквивалента и затем, опять же с помощью конструктора String(char[]), создаём новый объект.
Примеры использования возможностей пакета NIO для наших задач:
public static byte[] stringToBytesUTFNIO(String str) < char[] buffer = str.toCharArray(); byte[] b = new byte[buffer.length public static String bytesToStringUTFNIO(byte[] bytes)
А теперь, как и обещали, графики.
String в byte array:
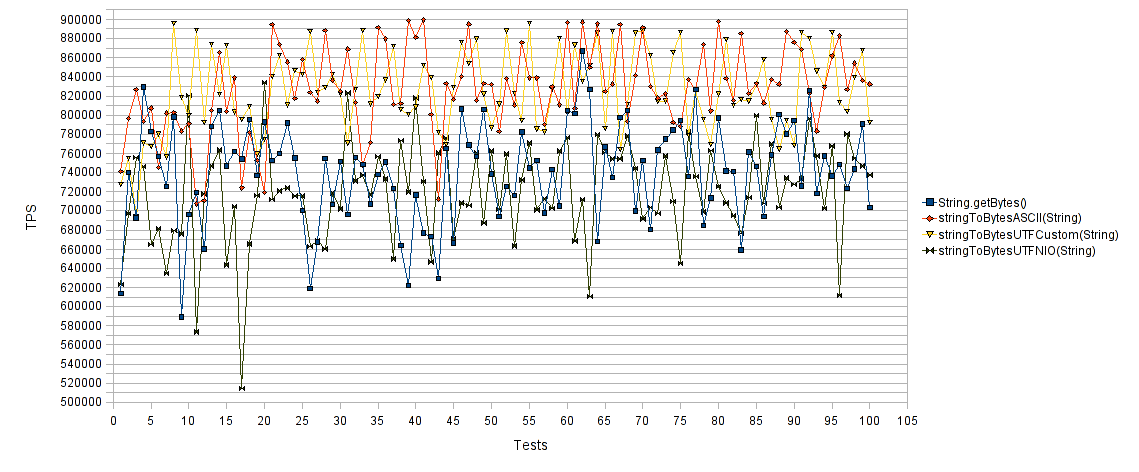
Ось абсцисс — количество тестов, ординат — количество операций в секунду для каждого теста. Что выше — то быстрее. Как и ожидалось, «String.getBytes()» и «stringToBytesUTFNIO(String)» отработали куда хуже «stringToBytesASCII(String)» и «stringToBytesUTFCustom(String)». Наши реализации, как можно увидеть, добились почти 30% увеличения количества операций в секунду.
Byte array в String:
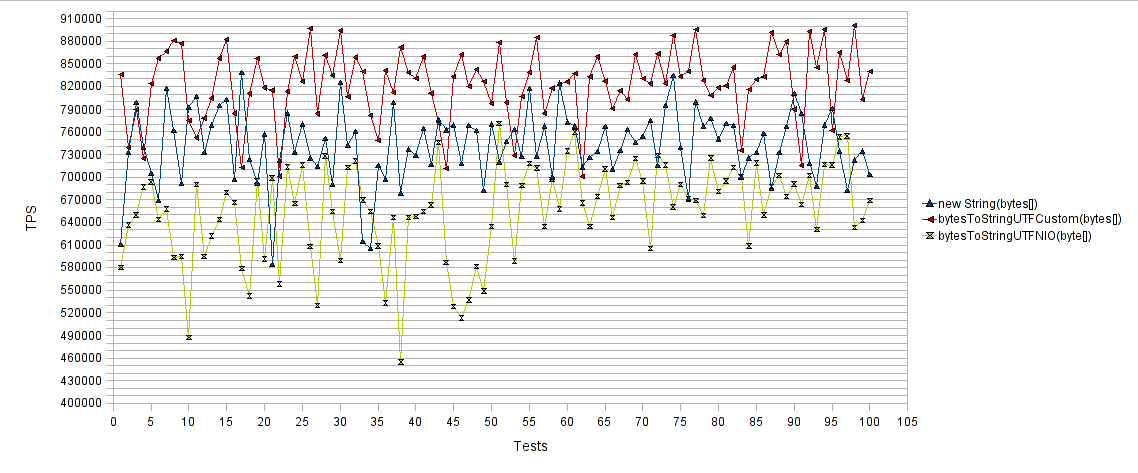
Результаты опять же радуют. Наши собственные методы добились 15% увеличения количества операций в секунду по сравнению с «new String(byte[])» и 30% увеличения количества операций в секунду по сравнению с «bytesToStringUTFNIO(byte[])».
В качестве вывода: в том случае, если вам необходимо преобразовать байтовую последовательность в строку или обратно, при этом не требуется менять кодировки, вы можете получить замечательный выигрыш в производительности с помощью самописных методов. В итоге, наши методы добились в общем 45% ускорения по сравнению с классическими подходами.
Java: Как преобразовать массив байтов [] в строку

Как преобразовать массив байтов [] в строку в Java ?
Есть два способа сделать это.
- Создав новый объект String и присвоив ему byte [].
- Лучший способ сделать это через « UTF-8 Расшифровка.
toString() Функция на объекте String не будет возвращать фактическую строку, а только HashValue. Посмотрите на все комментарии, упомянутые ниже в Java-программе.
Java-код: