К чему может привести ослабление уровня изоляции транзакций в базах данных
Всем привет. На связи Владислав Родин. В настоящее время я являюсь руководителем курса «Архитектор высоких нагрузок» в OTUS, а также преподаю на курсах, посвященных архитектуре ПО.
Помимо преподавания, как вы могли заметить, я занимаюсь написанием авторского материала для блога OTUS на хабре и сегодняшнюю статью хочу приурочить к запуску курса «PostgreSQL», на который прямо сейчас открыт набор.

Введение
В прошлый раз мы с вами поговорили про то, что транзакции в базах данных служат для решения двух задач: обеспечения отказоустойчивости и доступа к данным в конкурентной среде. Для полноценного выполнения этих задач транзакция должна обладать свойствами ACID. Сегодня мы подробно поговорим про букву I (isolation) в данной аббревиатуре.
Изоляция
Изоляция решает задачу доступа к данным в конкурентной среде, фактически предоставляя защиту от race condition’ов. В идеале, изоляция означает сериализацию, то есть свойство, обеспечивающее то, что результат выполнения транзакций параллельно такой же, как если бы они выполнялись последовательно. Основная проблема данного свойства заключается в том, что оно очень тяжело обеспечивается технически и как следствие сильно бьет по производительности системы. Именно поэтому изоляцию часто ослабляют, принимая риски возникновения некоторых аномалий, о которых речь пойдет ниже. Возможность возникновения тех или иных аномалий как раз таки и характеризует уровень изоляции транзакций.
Наиболее известными аномалиями являются: dirty read, non-repeatable read, phantom read, но самом деле их еще 5: dirty write, cursor lost update, lost update, read skew, write skew.
Dirty write
Суть аномалии заключается в том, что транзакции могут перезаписывать незакоммиченные данные.
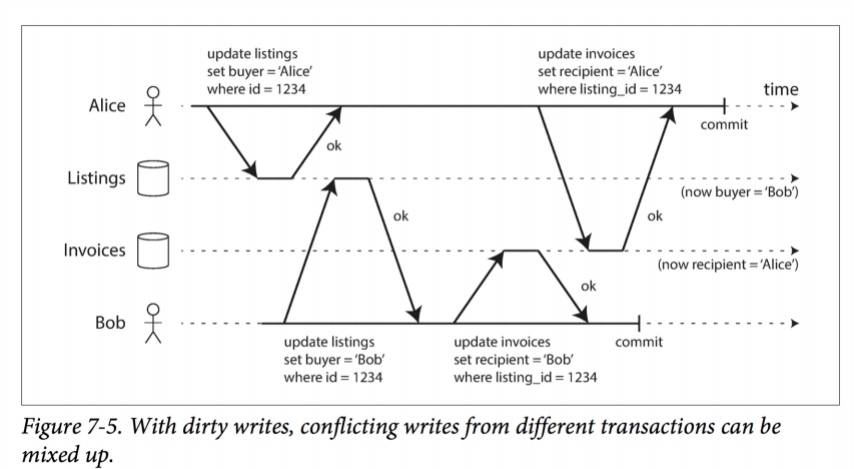
Данная аномалия опасна не только тем, что данные могут конфликтовать после коммита обеих транзакций (как на картинке), но и тем, что нарушается атомарность: потому что мы разрешим перезаписывать незакоммиченные данные, то непонятно, как откатить одну транзакцию, не задев при этом другую.
Лечится аномалия достаточно просто: вешаем блокировку на запись перед началом записи, запрещая другим транзакциям менять запись до тех пор, пока блокировка не будет снята.
Dirty read
Dirty read означает прочтение незакоммиченных данных.
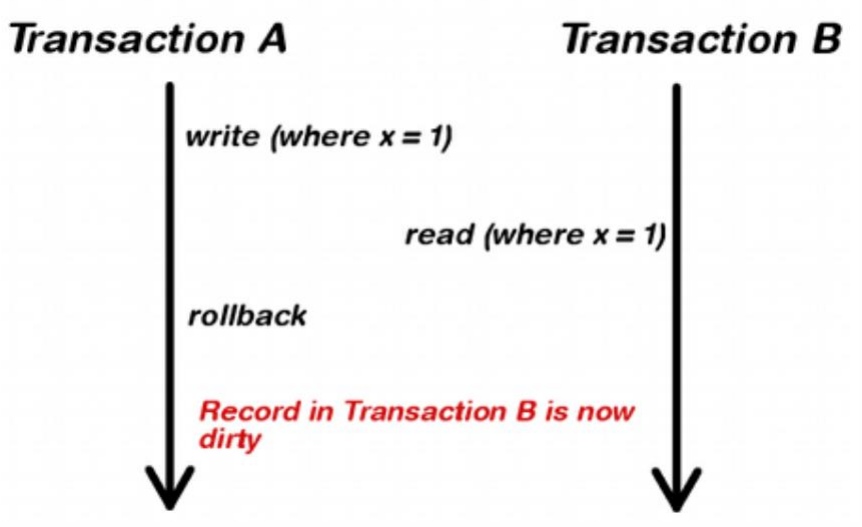
Проблемы возникают, когда на основе выборки необходимо осуществить какие-то действия или принять решения.
Для исправления аномалии можно повесить блокировку на чтение, но это сильно ударит по производительности. Гораздо проще сказать, что для rollback’а транзакции исходное состояние данных (до начала записи) обязательно должно быть сохранено в системе. Почему бы не читать оттуда? Это достаточно недорого, поэтому большинство баз данных убирают dirty read по-умолчанию.
Lost update
Lost update означает потерянные обновления, и перевод достаточно точно отображает суть проблемы:
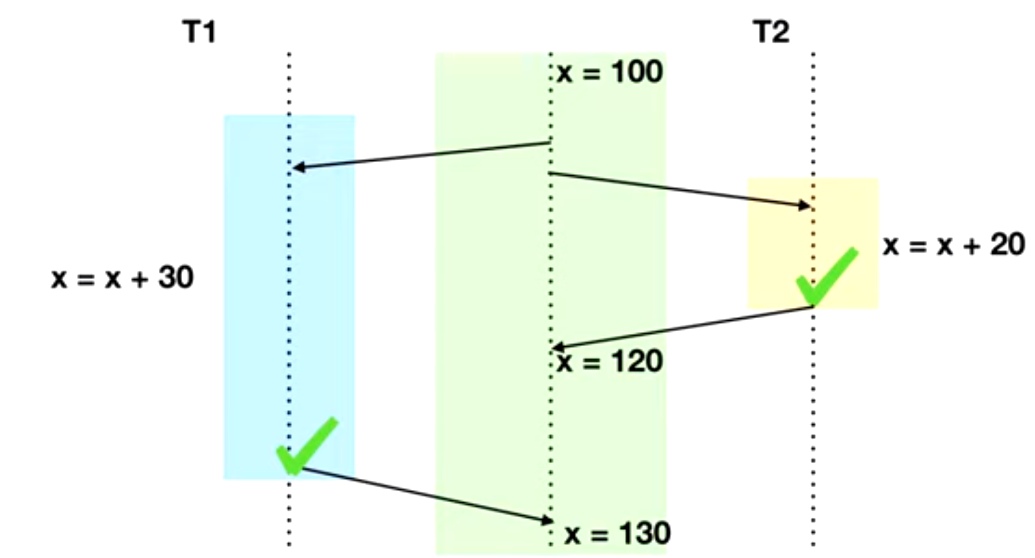
Фактически, результат транзакции Т2 был отменен. Исправляется такая ситуация явными или неявными блокировками записи. То есть мы либо просто осуществляем обновление записи, и тогда возникает неявная блокировка, либо мы выполняем select for update, вызывая возникновение блокировки на чтение и на записи. Обратите внимание на то, что такая операция достаточно опасна: своим «невинным» чтением, мы блокируем другие чтения. Некоторые базы предлагают более безопасный select for share, позволяющий читать данные, но не разрешающий их изменять.
Cursor lost update
Для более тонкого контроля базы могут предлагать другие инструменты, например, курсор. Курсор- это структура, содержащая набор строк и позволяющая по ним итерироваться. declare cursor_name for select_statement. Содержимое курсора описывается select’ом.
Зачем нужен курсор? Дело в том, что некоторые базы данных предлагают блокировку на все записи, выбранные select’ом (read stability), либо только на ту запись, на которой находится в данный момент курсор (cursor stability). При cursor stability осуществляется short lock, что позволяет снизить количество блокировок в том случае, если мы итерируемся по большой выборке данных. Поэтому аномалию lost update выделяют для курсора отдельно.
Non-repeatable read
Non-repeatable read заключается в том, что во время выполнения нашей транзакции 2 последовательных чтения одной и той же записи приведет к получению различных результатов, потому что другая транзакция вмешалась между этими двумя чтениями, поменяла наши данные и была закоммичена.
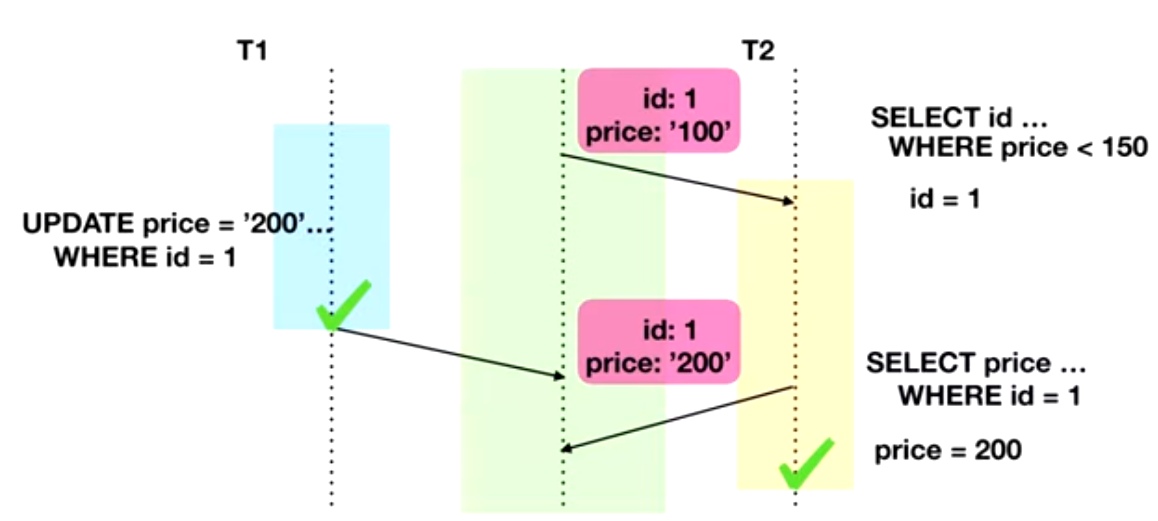
Почему это вообще проблема? Представьте себе, что цель транзакции Т2 на картинке выбрать все товары, цена которых меньше, чем 150 у.е. Кто-то другой обновил цену до 200 у.е. Таким образом, установленный фильтр не сработал.
Данные аномалии перестают возникать при добавлении двухфазных блокировок или при использовании механизма MVCC, о чем хотелось бы поговорить отдельно.
Phantom read
Фантомным называется чтение данных, которые были добавлены другой транзакцией.

В качестве примера можно наблюдать неправильную выборку самого дешевого товара при возникновении данной аномалии.
Избавиться от фантомных чтений уже достаточно сложно. Обычной блокировки недостаточно, ведь бы не можем заблокировать то, чего еще нету. 2PL-системы используют предикативную блокировку, тогда как MVCC-системы планировщик транзакций отменяет транзакции, которые могут быть нарушены вставкой. Как первый, так и второй механизмы достаточно тяжеловесны.
Read skew
Read skew возникает когда мы работаем с несколькими таблицами, содержание которых должно меняться согласованно.
Предположим, имеются таблицы, представляющие посты и их метаинформацию:

Одна транзакция читает из таблиц, другая их изменяет:
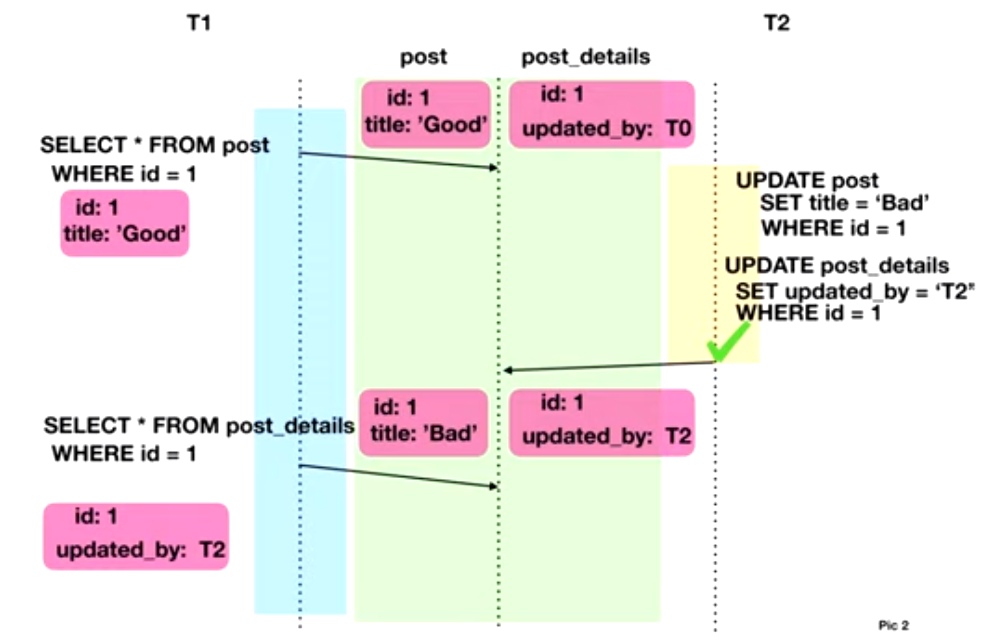
В результате выполнения транзакции Т1, у поста title = Good, а updated_by = T2, что является некоторым несоответствием.
Фактически, это non-repeatable read, но в составе нескольких таблиц.
Для исправления, Т1 может вешать блокировки на все строки, которые она будет читать, что не даст транзакции Т2 менять информацию. В случае MVCC транзакция Т2 будет отменена. Защита от данной аномалии может стать важной, если мы используем курсоры.
Write skew
Эту аномалию тоже проще объяснить на примере: предположим, что в нашей системе хотя бы один доктор должен быть на дежурстве, но оба доктора решили свое дежурство отменить:
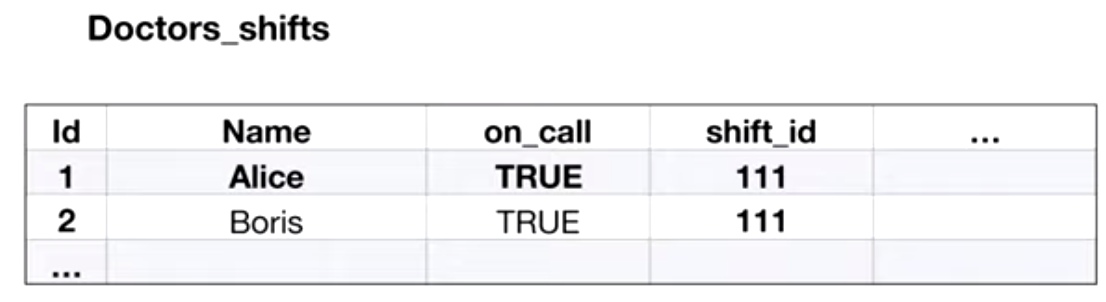

Аномалия привела к тому, что ни один из докторов не выйдет на дежурство. Почему так получилось? Потому что транзакция проверяла условие, которое может быть нарушено другой транзакцией, а из-за изоляции мы не увидели это изменение.
Это тот же non-repeatable read. Как вариант, select’ы могут вешать блокировки на эти записи.
Write skew и read skew являются комбинациями предыдущих аномалий. Можно рассмотреть write skew, являющийся по сути phantom read’ом. Рассмотрим таблицу, в которой есть имена сотрудников, их зарплата и проект, на котором они работают:
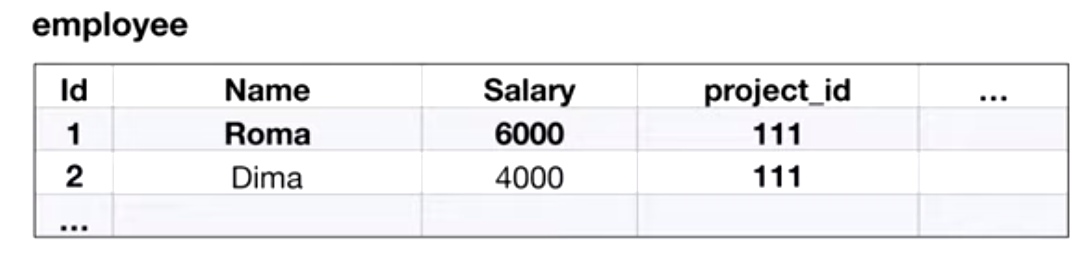

В итоге, мы получаем следующую картину: каждый менеджер думал, что его изменение не приведет к выходу за бюджет, поэтому они внесли кадровые изменения, которые в сумме привели к перерасходу.
Причина возникновения проблемы точно такая же, как и в фантомном чтении.
Выводы
Ослабление уровня изоляции транзакций в базе данных является компромиссом между безопасностью и производительностью, к выбору данного уровня следует подходить исходя из потенциальных рисков для бизнеса при возникновении тех или иных аномалий.
Нормализация отношений. Первая и вторая нормальные формы
Нормализация отношений (таблиц) — одна из основополагающих частей теории реляционных баз данных. Нормализация имеет своей целью избавиться от избыточности в отношениях и модифицировать их структуру таким образом, чтобы процесс работы с ними не был обременён различными посторонними сложностями. При игнорировании такого подхода эффективность проектирования стремительно снижается, что вкупе с прочими подобными вольностями может привести к критическим последствиям.
Любому специалисту, по роду своей деятельности так или иначе связанному с проектированием реляционных баз данных, полезно понимать и уметь осуществить нормализацию отношений. И этим постом хотелось бы начать небольшую серию публикаций, посвящённых нормальным формам, имеющую целью дать тем читателям Хабрахабра, которые по различным обстоятельствам ещё не освоили эту тему, возможность легко заполнить этот пробел в знаниях.
Статья не имеет своей целью подробное и точное изложение принципов нормализациии, поскольку это, очевидно, невозможно в рамках блога в силу больших объёмов информации, необходимых для публикации при таком подходе. Кроме этого, для такой цели существует большое количество литературы, написанной прекрасными специалистами. Моя же задача, как я считаю, заключается в том, чтобы популярно продемонстрировать и объяснить основные принципы.
Используемые термины
Атрибут — свойство некоторой сущности. Часто называется полем таблицы.
Домен атрибута — множество допустимых значений, которые может принимать атрибут.
Кортеж — конечное множество взаимосвязанных допустимых значений атрибутов, которые вместе описывают некоторую сущность (строка таблицы).
Отношение — конечное множество кортежей (таблица).
Схема отношения — конечное множество атрибутов, определяющих некоторую сущность. Иными словами, это структура таблицы, состоящей из конкретного набора полей.
Проекция — отношение, полученное из заданного путём удаления и (или) перестановки некоторых атрибутов.
Функциональная зависимость между атрибутами (множествами атрибутов) X и Y означает, что для любого допустимого набора кортежей в данном отношении: если два кортежа совпадают по значению X, то они совпадают по значению Y. Например, если значение атрибута «Название компании» — Canonical Ltd, то значением атрибута «Штаб-квартира» в таком кортеже всегда будет Millbank Tower, London, United Kingdom. Обозначение: -> .
Первая нормальная форма
Отношение находится в первой нормальной форме (сокращённо 1НФ), если все его атрибуты атомарны, то есть если ни один из его атрибутов нельзя разделить на более простые атрибуты, которые соответствуют каким-то другим свойствам описываемой сущности.
Будем называть исходное отношение основным, а значение неатомарного атрибута — подчинённым.
Для того, чтобы нормализовать исходное отношение, атрибуты которого неатомарны, необходимо объединить схемы основного и подчинённого отношений. Кроме того, если, например, таблица, соответствующая ненормализованному отношению уже содержится в БД и заполнена информацией, задача усложняется тем, что значение неатомарного атрибута может в свою очередь содержать несколько кортежей.
Следует пояснить сказанное на примере. Рассмотрим отношение, имеющее атрибуты «Код сотрудника», «ФИО», «Должность», «Проекты». Очевидно, что один сотрудник может работать над несколькими проектами. Предположим, что проект описывается идентификатором, названием и датой сдачи.
| Код сотрудника | ФИО | Должность | Проекты |
| 1 | Иванов Иван Иванович | Программист | ID: 123; Название: Система управления паровым котлом; Дата сдачи: 30.09.2011 ID: 231; Название: ПС для контроля и оповещения о превышениях ПДК различных газов в помещении; Дата сдачи: 30.11.2011 ID: 321; Название: Модуль распознавания лиц для защитной системы; Дата сдачи: 01.12.2011 |
Легко заметить, что не все атрибуты этого отношения атомарны (неделимы). В частности, атрибут «Проекты» можно разделить на три более простых атрибута: «Код проекта», «Название», «Дата сдачи», а значение этого атрибута для сотрудника Иван Иванович Иванов содержит несколько кортежей — информацию о трёх проектах.
Примечание: с некоторой точки зрения атрибут «ФИО» можно также считать неатомарным и в таком случае его также следует разделить на более простые, как «Фамилия», «Имя», «Отчество».
- Создать новое отношение, схема которого будет получена путём слияния основной и подчинённой схем исходного отношения в одну.
- Для каждого кортежа исходного отношения включить в новое столько строк, сколько кортежей содержится в подчинённом отношении этого кортежа.
- Заполнить значения атрибутов нового отношения, соответствующих атрибутам подчинённого отношения.
- Заполнить строки нового отношения значениями атомарных атрибутов исходного.
Результат будет выглядеть так:
| Код сотрудника | ФИО | Должность | Код проекта | Название | Дата сдачи |
| 1 | Иванов Иван Иванович | Программист | 123 | Система управления паровым котлом | 30.09.2011 |
| 1 | Иванов Иван Иванович | Программист | 231 | ПС для контроля и оповещения о превышениях ПДК различных газов в помещении | 30.11.2011 |
| 1 | Иванов Иван Иванович | Программист | 321 | Модуль распознавания лиц для защитной системы | 01.12.2011 |
Вторая нормальная форма
Ясно, что отношение, находящееся в 1НФ, также может обладать избыточностью. Для её устранения предназначена вторая нормальная форма. Но прежде чем приступить к её описанию, сначала следует выявить недостатки первой.
Пусть исходное отношение содержит информацию о поставке некоторых товаров и их поставщиках.
| Код поставщика | Город | Статус города | Код товара | Количество |
| 1 | Москва | 20 | 1 | 300 |
| 1 | Москва | 20 | 2 | 400 |
| 1 | Москва | 20 | 3 | 100 |
| 2 | Ярославль | 10 | 4 | 200 |
| 3 | Ставрополь | 30 | 5 | 300 |
| 3 | Ставрополь | 30 | 6 | 400 |
| 4 | Псков | 15 | 7 | 100 |
- Аномалия вставки. В отношение нельзя добавить информацию о поставщике, который ещё не поставил ни одного товара.
- Аномалия удаления. Если от поставщика была только одна поставка, то при удалении информации о ней будет удалена и вся информация о поставщике.
- Аномалия обновления. Если необходимо изменить какую-либо информацию о поставщике (например, поставщик переехал в другой город), то придётся изменять значения атрибутов во всех записях о поставках от него.
- В первую следует включить первичный ключ и все неключевые атрибуты явно зависимые от него.
- В остальные проекции (в данном случае она одна) будут включены неключевые атрибуты, зависящие от первичного ключа неявно, вместе с той частью первичного ключа, от которой эти атрибуты зависят явно.
| Код поставщика | Код товара | Количество |
| 1 | 1 | 300 |
| 1 | 2 | 400 |
| 1 | 3 | 100 |
| 2 | 4 | 200 |
| 3 | 5 | 300 |
| 3 | 6 | 400 |
| 4 | 7 | 100 |
Первому отношению теперь соответствуют следующие функциональные зависимости:
->
| Код поставщика | Город | Статус города |
| 1 | Москва | 20 |
| 2 | Ярославль | 10 |
| 3 | Ставрополь | 30 |
| 4 | Псков | 15 |
Такое разбиение устранило аномалии, описанные выше: можно добавить информацию о поставщике, который ещё не поставлял товар, удалить информацию о поставке без удаления информации о поставщике, а также легко обновить информацию в случае если поставщик переехал в другой город.
Теперь можно сформулировать определение второй нормальной формы, до которого, скорее всего, читатель уже смог догадаться самостоятельно: отношение находится во второй нормальной форме (сокращённо 2НФ) тогда и только тогда, когда оно находится в первой нормальной форме и каждый его неключевой атрибут неприводимо зависим от первичного ключа.
Литература
Для более глубокого и основательного изучения рассмотренной темы, рекомендуется книга «Введение в системы баз данных» Криса Дж. Дейта, на основе материалов которой и была написана данная статья.
- реляционные базы данных
- нормализация отношений
- нормальные формы
- первая нормальная форма
- 1НФ
- вторая нормальная форма
- 2НФ
Что такое нормализация базы данных?
![]()
Нормализация базы данных (БД) — это метод проектирования реляционных БД, который помогает правильно структурировать таблицы данных. Процесс направлен на создание системы с четким представлением информации и взаимосвязей, без избыточности и потери данных.
В данной статье рассказывается, что такое нормализация базы данных, и объясняются принципы ее работы на практическом примере.
Что такое нормализация базы данных?
Нормализация базы данных — это метод создания таблиц БД со столбцами и ключами путем разделения (или декомпозиции) таблицы большего размера на небольшие логические единицы. В данном методе учитываются требования, предъявляемые к среде БД.
Нормализация — это итеративный процесс. Как правило, нормализация БД выполняется через серию тестов. Каждый последующий шаг разбивает таблицу на более легкую в управлении информацию, чем повышается общая логичность системы и простота работы с ней.
Зачем нужна нормализация базы данных?
Нормализация позволяет разработчику БД оптимально распределять атрибуты по таблицам. Данная методика избавляет от:
- атрибутов с несколькими значениями;
- задвоения или повторяющихся атрибутов;
- атрибутов, не поддающихся классификации;
- атрибутов с избыточной информацией;
- атрибутов, созданных из других признаков.
Необязательно выполнять полную нормализацию БД. Однако она гарантирует полноценно функционирующую информационную среду. Этот метод:
- позволяет создать структуру базы данных, подходящую для общих запросов;
- сводит к минимуму избыточность данных, что повышает эффективность использования памяти на сервере БД;
- гарантирует максимальную целостность данных, устраняя аномалий вставки, обновления и удаления.
Нормализация базы данных преобразует общую целостность данных в удобную для пользователя среду.
Избыточность баз данных и аномалии
Когда вы вносите изменения в таблицу избыточностью, вам придется корректировать все повторяющиеся экземпляры данных и связанные с ними объекты. Если этого не сделать, то таблица станет несогласованной, и при внесении изменений возникнут аномалии.
Так выглядит таблица без нормализации:

Для таблицы характерна избыточность данных, а при изменении этих данных возникают 3 аномалии:
- Аномалия вставки. При добавлении нового «Сотрудника» (employee) в «Отдел» (sector) Finance, обязательно указывается его «Руководитель» (manager). Иначе вы не сможете вставить данные в таблицу.
- Аномалия обновления. Когда сотрудник переходит в другой отдел, поле «Руководитель» содержит ошибочные данные. К примеру, Джейкоб (Jacob) перешел в отдел Finance, но его руководителем по-прежнему показывается Адам (Adam).
- Аномалия удаления. Если Джошуа (Joshua) решит уволиться из компании, то при удалении строки с его записью потеряется информация о том, что отдел Finance вообще существует.
Для устранения подобных аномалий используется нормализация базы данных.
Основные понятия в нормализации базы данных
Простейшие понятия, используемые в нормализации базы данных:
- ключи — атрибуты столбцов, которые однозначно (уникально) определяют запись в БД;
- функциональные зависимости — ограничения между двумя взаимосвязанными атрибутами;
- нормальные формы — этапы для достижения определенного качества БД.
Нормальные формы базы данных
Нормализация базы данных выполняется с помощью набора правил. Такие правила называются нормальными формами. Основная цель данных правил — помочь разработчику БД в достижении нужного качества реляционной базы.
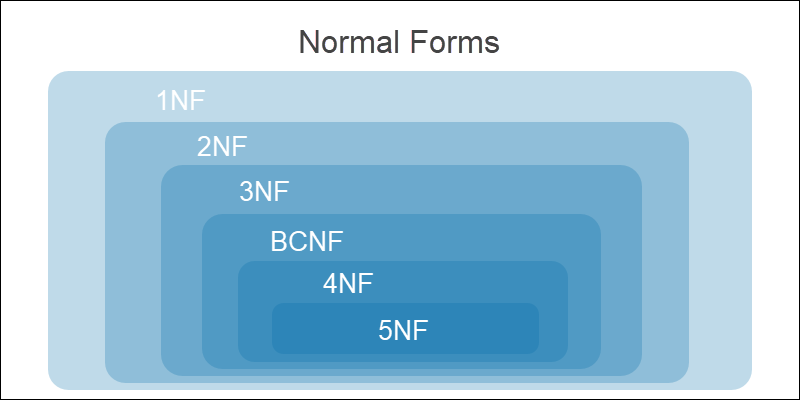
Все уровни нормализации считаются кумулятивными, или накопительными. Прежде чем перейти к следующему этапу, выполняются все требования к текущей форме.
Аномалии избыточности
Ненормализованная (нулевая) форма (UNF)
Это состояние перед любой нормализацией. В таблице присутствуют избыточные и сложные значения
Первая нормальная форма (1NF)
Разбиваются повторяющиеся и сложные значения; все экземпляры становятся атомарными
Вторая нормальная форма (2NF)
Частичные зависимости разделяются на новые таблицы. Все строки функционально зависимы от первичного ключа
Третья нормальная форма (3NF)
Транзитивные зависимости разбиваются на новые таблицы. Не ключевые атрибуты зависят от первичного ключа
Нормальная форма Бойса-Кода (BCNF)
Транзитивные и частичные функциональные зависимости для всех потенциальных ключей разбиваются на новые таблицы
Четвертая нормальная форма (4NF)
Удаляются многозначные зависимости
Пятая нормальная форма (5NF)
Удаляются JOIN-зависимости (зависимости соединения)
База данных считается нормализованной после достижения третьей нормальной формы. Дальнейшие этапы нормализации усложняю структуру БД и могут нарушить функционал системы.
Что такое Ключ?
Ключ БД (key) — это атрибут или группа признаков, которые однозначно описывают сущность в таблице. В нормализации используются следующие типы ключей:
- суперключ (Super Key) — набор признаков, которые уникально определяют каждую запись в таблице;
- потенциальный ключ (Candidate Key) — выбирается из набора суперключей с минимальным количеством полей;
- первичный ключ (Primary Key) — самый подходящий кандидат из набора потенциальных ключей; служит первичным ключом таблицы;
- внешний ключ (Foreign Key) — первичный ключ другой таблицы;
- составной ключ (Composite Key) — уникальный ключ, образованный двумя и более атрибутами, каждый из которых по отдельности не является ключом.
Поскольку таблицы разделяются на несколько более простых единиц, именно ключи определяют точку ссылки для объекта БД.
Например, в следующей структуре базы данных:

Примерами суперключей являются:
Все суперключи служат уникальным идентификатором каждой строки. К примеру, имя сотрудника и его возраст не считаются уникальными идентификаторами, поскольку несколько людей могут быть тезками и одногодками.
Потенциальные ключи выбираются из набора суперключей с минимальным количеством полей. В нашем примере это:
Оба параметра содержат минимальное количество полей, поэтому они хорошо подходят на роль потенциальных ключей. Самый логичный выбор для первичного ключа — поле employeeID, поскольку почта сотрудника может измениться. На такой первичный ключ легко ссылаться в другой таблице, для которой он будет считаться внешним ключом.
Функциональные зависимости базы данных
Функциональная зависимость БД отражает взаимосвязь между двумя атрибутами таблицы. Функциональные зависимости бывают следующих типов:
- тривиальная функциональная зависимость — зависимость между атрибутом и группой признаков; исходный элемент является частью группы;
- нетривиальная функциональная зависимость — зависимость между атрибутом и группой признаков; признак не является частью группы;
- транзитивная зависимость — функциональная зависимость между тремя атрибутами: второй атрибут зависит от первого, а третий — от второго. Благодаря транзитивности, третий атрибут зависит от первого;
- многозначная зависимость — зависимость, в которой несколько значений зависят от одного атрибута.
Функциональные зависимости — это важный этап в нормализации БД. В долгосрочной перспективе такие зависимости помогают оценить общее качество базы данных.
Примеры нормализации базы данных. Как нормализовать базу данных?
Общие этапы в нормализации базы данных подходят для всех таблиц. Конкретные методы разделения таблицы, а также вариант прохождения или не прохождения через третью нормальную форму (3NF) зависят от примеров использования.
Пример ненормализованной базы данных
В одном столбце ненормализованной таблицы содержится несколько значений. В худшем случае в ней присутствует избыточная информация.
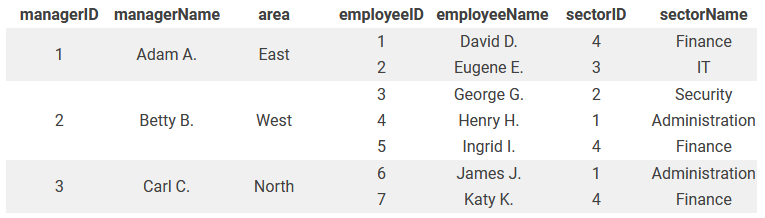
Добавление, обновление и удаление данных — все это сложные задачи. Выполнение любых изменений текущих данных сопряжено с высоким риском потери информации.
Шаг 1: Первая нормальная форма (1NF)
Для преобразования таблицы в первую нормальную форму значения полей должны быть атомарными. Все сложные сущности таблицы разделяются на новые строки или столбцы.
Чтобы не потерять информацию, для каждого сотрудника дублируются значения столбцов managerID, managerName и area.
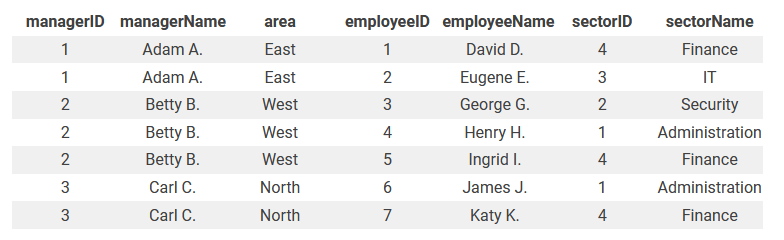
Доработанная таблица соответствует первой нормальной форме.
Шаг 2: Вторая нормальная форма (2NF)
Во второй нормальной форме каждая строка таблицы должна зависеть от первичного ключа.
Чтобы таблица соответствовала критериям этой формы, ее необходимо разделить на 2 части:
Manager (managerID, managerName, area)

Employee (employeeID, employeeName, managerID, sectorID, sectorName)
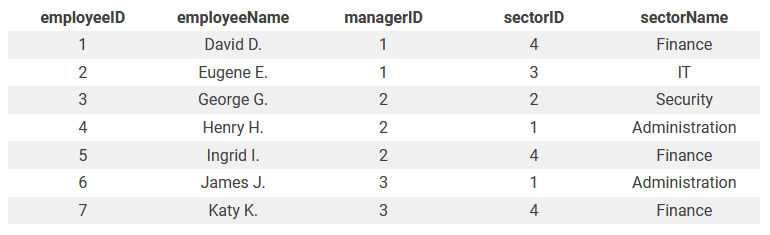
Итоговая таблица во второй нормальной форме представляет собой 2 таблицы без частичных зависимостей.
Шаг 3: третья нормальная форма (3NF)
Третья нормальная форма разделяет любые транзитивные функциональные зависимости. В нашем примере транзитивная зависимость есть у таблицы Employee; она разбивается на 2 новых таблицы:
Employee (employeeID, employeeName, managerID, sectorID)
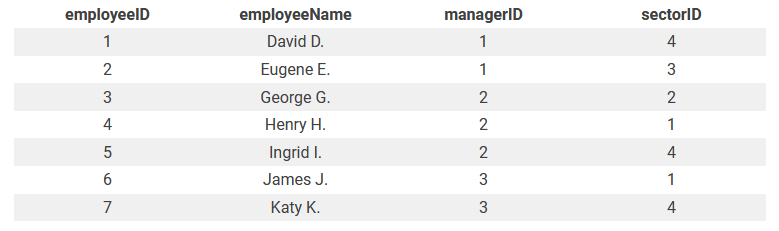
Sector (sectorID, sectorName)

Теперь таблица соответствует третьей нормальной форме с тремя взаимосвязями. Конечная структура выглядит так:

Теперь база данных считается нормализованной. Дальнейшая нормализация зависит от ваших конкретных целей.
Заключение
В статье рассказывалось, как с помощью нормализации БД можно сократить избыточность информации. В долгосрочной перспективе нормализация БД позволяет свести к минимуму потерю данных и улучшить их общую структуру.
Если же вы хотите повысить производительность доступа к данным, то воспользуйтесь денормализацией БД.
А если вы испытываете трудности с нормализацией базы данных, то рассмотрите возможность перехода на другой тип БД.
3. Нормализация отношений при проектировании БД
Цель раздела — ознакомление с процедурой нормализации, её разными уровнями, теоретическим и практическим аспектами, критериями определения уровня нормализации на практике в зависимости от требований конечных пользователей.
3.1. Процедура нормализации
С одной стороны, процесс проектирования структур БД является творческим, неоднозначным, с другой стороны, его узловые моменты могут быть формализованы [4 — 7, 10, 12]. В процессе разработки логическая модель данных постоянно тестируется и проверяется на соответствие требованиям пользователей. Корректность логической модели данных обеспечивает процедура нормализации.
Процедура нормализации БД заключается в устранении избыточности данных и выявлении функциональных зависимостей. Устранение избыточности данных гарантирует компактность набора данных за счет ухода от их ненужного дублирования и исключения возможности возникновения аномалии вставки, удаления и обновления кортежей после физической реализации БД. Функциональная зависимость связывает атрибуты в одном отношении с единственным значением в другом отношении. Функциональную зависимость для отношений А и B принято обозначать как A→B. Это понятие подводит «на один шаг» к родственной концепции объединения отношений связями типа один к одному (1:1) или один ко многим (1:М).
Правила нормализации или правила Кодда, как их теперь принято называть, очень просты и немногочисленны, но весьма строги. В случае применения к отношениям каждое правило описывает следующий уровень соответствия требованиям теории реляционных БД и различные уровни нормализации.
Существует следующие уровни нормализации: первая нормальная форма (1НФ), 2НФ, 3НФ, нормальная форма Бойса-Кодда (БКНФ), 4НФ, 5НФ. Однако, до сегодняшнего дня ни одна из реляционных СУБД не поддерживает все пять нормальных форм. Это является следствием жестких требований к производительности. Суть дела состоит в том, что в полностью нормализованой БД для выполнения запроса будет необходимо соеденить настолько много таблиц, что производительность такой системы не сможет удовлетворить пользователей. Поэтому на практике используют лишь первые три уровня нормализации — 1НФ, 2НФ, ЗНФ.
3.2. Первая нормальная форма
Отношение представлено в первой нормальной форме (1НФ) тогда и только тогда, когда все его атрибуты содержат только неделимые (атомарные) значения и в нем отсутствуют группы атрибутов с одинаковыми по смыслу значениями, которые повторяются в пределах одного кортежа.
Неделимость значения атрибута говорит о том, что его нельзя разделить на более мелкие части. Например, если в атрибуте «Фамилия Имя Отчество» содержится фамилия, имя и отчество читателя, требование неделимости не соблюдается (рис. 3.1, а). Здесь необходимо выделить в отдельные атрибуты имя и отчество. В результате получится три атрибута отношения «ЧИТАТЕЛИ»: «Фамилия», «Имя» и «Отчество» (рис. 3.1, б).
Рис. 3.1. Возможные спецификации ненормализованного отношения «ЧИТАТЕЛИ»
На более мелкие части можно также разделить атрибуты: «Место рождения» («Страна», «Административное образование», «Населенный пункт»), «Место выдачи паспорта» («Страна», «Административное образование», «Населенный пункт»), «Место основной работы» («Тип предприятия», «Название предприятия»), «Место жительства» («Страна», «Административное образование», «Населенный пункт», «Жилой массив / Проспект / Улица / Переулок», «Дом», «Корпус», «Квартира») (рис. 3.1, б).
Для контакта читатель может определить один, несколько или ни одного номера телефона. Таким образом в общем случае информация в атрибуте «Номер телефона» может быть розделена на несколько частей, каждая из которых является отдельным телефонным номером (рис. 3.1, а). На первый взгляд эту проблему можно решить так же, как и для фамилии, имени и отчества, выделив для наиболее распространенных типов телефонов отдельные атрибуты (рис. 3.1, б). Однако, в этом случае, мы столкнемся с повторяющейся группой атрибутов, содержащих одинаковые по смыслу значения в пределах одного кортежа, например: «Домашний телефон», «Рабочий телефон», «Мобильный телефон».
Чтобы отношение «ЧИТАТЕЛИ» (рис. 3.1, б) соответствовало 1НФ необходимо удалить из него группу атрибутов с номерами телефонов, которые повторяются в пределах одного кортежа, в другое отношение вместе с копией ключевого атрибута «№ читательского билета» (рис. 3.2). Причем, выделим для указания номера и типа телефона отдельные атрибуты. Это позволяет: во-первых, учитывать не только три указанных типа телефона, но и добавлять новые и во-вторых, указывать для каждого читателя только те типы телефонов, которые у него имеются, в-третьих, можно указать для любого читателя несколько однотипных телефонов или вообще не указывать ни одного телефонного номера.
Рис. 3.2. Приведение отношения «ЧИТАТЕЛИ» к 1НФ
3.3. Вторая нормальная форма
Отношение представлено во второй нормальной форме (2НФ) тогда и только тогда, когда оно представлено в первой нормальной форме, и каждый неключевой атрибут полностью определяется первичным ключом, то есть чтобы первичный ключ однозначно определял кортеж и не был избыточен (совпадал с суперключом). Те атрибуты, которые зависят только от части суперключа, должны быть выделены в составе отдельных таблиц.
Отношение «ЧИТАТЕЛИ» (рис. 3.2) не представлено во 2НФ. В нём каждый кортеж может быть однозначно идентифицирован следующими атрибутами: «№ читательского билета», «Серия паспорта» и «№ паспорта». Совокупность этих атрибутов является суперключом этого отношения. Он состоит из двух потенциальных ключей, которые по отдельности могут идентифицировать кортежи отношения. Из двух потенциальных ключей в качестве первичного ключа выбран тот, длина которого минимальна. Наличие обоих потенциальных ключей обусловлено требованиями пользователей.
Привести отношение «ЧИТАТЕЛИ» ко 2НФ можно, вынеся в отдельное отношение атрибуты 2 – 22, которые касаются паспортных данных, и копию первичного ключа «№ читательского билета» (рис. 3.3). Однако в результате мы получим отношение «ПАСПОРТНЫЕ ДАННЫЕ», которое имеет такой же суперключ, как и отношение «ЧИТАТЕЛИ», до приведения его ко 2НФ. В нашем случае дальнейшая нормализация отношения «ПАСПОРТНЫЕ ДАННЫЕ» невозможна.
Рис. 3.3. Отношения «ТЕЛЕФОНЫ» и «ЧИТАТЕЛИ», приведенные ко 2НФ
В отношении «ТЕЛЕФОНЫ» (рис. 3.3) на первый взгляд кажется, что если в описании логической модели добавить номер телефона читателя, включая код страны, оператора или населенного пункта, то потенциальным будет ключ, в составе которого всего один атрибут – «№ телефона». Однако, у двух разных читателей может быть один и тот же домашний или рабочий телефоны. Следовательно, однозначно идентифицировать кортежи можно по составному суперключу, в который входят атрибуты «№ читательского билета» та «№ телефона». Мы видим, что суперключ не является избыточным. Его состав совпадает с первичным ключом. Значит отношение «ТЕЛЕФОНЫ» представлено во второй нормальной форме.
3.4. Третья нормальная форма
В общем 1НФ и 2НФ рассматриваются как промежуточные этапы в процессе нормализации БД. Большая часть СУБД ориентирована на достижение следующей степени нормализации — третьей нормальной формы (ЗНФ). Это связано с тем, что представление отношений в 3НФ вполне отвечает почти всем практическим задачам. При разработке исключительно больших систем на сверхбыстродействующих компьютерах, когда необходимо обеспечить максимальное сокращение объемов данных, желательно провести дальнейшую нормализацию отношений.
Отношение представлено в третьей нормальной форме (3НФ) тогда и только тогда, когда оно есть во второй нормальной форме и в нём нет транзитивных зависимостей между неключевыми атрибутами, то есть значение любого атрибута отношения, не входящего в первичный ключ, не зависит от значения другого атрибута, не входящего в первичный ключ.
Это определение – всего лишь оригинальный способ выразить необходимость представления системы связанных отношений в таком виде, чтобы значения атрибутов каждого отношения непосредственно определялись либо суперключом, либо потенциальным ключом этого отношения.
Существует метод расчета минимального числа отношений, необходимых для представления БД в 3НФ. В том случае, если вы составили список всех функциональных зависимостей в Ваших данных, можно применить алгоритм Бернштейна, который описан в любом учебнике реляционной алгебры.
Рассмотрим пример из области учета товара на складе. Кажется логичным, чтобы в отношение с оперативной информацией о товаре на складе входили в числе прочих три следующих атрибута: «Количество товара», «Цена за единицу товара» и «Общая стоимость товара». Они не являются ключевыми. Для получения значения «Общей стоимости товара» необходимо перемножить значения, находящиеся в атрибутах: «Количество товара» и «Цена за единицу товара». Т.е. значение поля «Общей стоимости товара» зависит от значений двух атрибутов, не входящих в состав первичного ключа. Это противоречит определению 3НФ. Чтобы данное отношение соответствовало третьей нормальной форме из него необходимо убрать атрибут «Общая стоимость товара».
Отметим, что отношения «ТЕЛЕФОНЫ» и «ЧИТАТЕЛИ» (рис. 3.3) приведены к третьей нормальной форме. Это следует из того, что они представлены во второй нормальной форме и в них нет транзитивных зависимостей.
Ниже приводится вариант определения 3НФ, называемого нормальной формой Бойса-Кодда (Воусе-Codd) – БКНФ, где устанавливаются более строгие требования.
Отношение X представлено в нормальной форме Бойса-Кодда, если в каждой нетривиальной функциональной зависимости В→А В является суперключом.
3.5. Четвертая и пятая нормальные формы
Прежде чем закончить рассмотрение правил Кодда, Вам будет предложен краткий обзор двух последних форм отнощений реляционных БД. Они предназначены для устранения еще двух аномалий: многозначная зависимость и объединяющая зависимость.
В отношении X существует многозначная зависимость А→В тогда, когда в нем можно обнаружить ситуации, где пара кортежей содержит дублирующееся значение А и одновременно существуют другие пары кортежей, полученные путем перестановки значений В, присутствующих в первой паре.
Прежде всего, для существования многозначной зависимости требуется существование пар кортежей. А и В могут быть как отдельными атрибутами, так и объединением некоторого набора атрибутов. Тривиальная многозначная зависимость для А→В существует в тогда, и только тогда, когда В является подмножеством А или А объединяет B = XS (более крупное отношение содержит исходное отношение).
Существование многозначной зависимости порождает аномалию обновления. 4НФ устраняет нетривиальную многозначную зависимость в отношении посредством создания меньших отношений. Процесс нормализации представляет собой создание как можно большего числа все более мелких отношений в целях сокращения избыточности данных.
Отношение X представлено в четвертой нормольной форме (4НФ) тогда и только тогда, когда оно представлено в БКНФ и для любой многозначной зависимости А→В в этом отношении можно сказать, что эта зависимость либо является тривиальной, либо А является суперключом таблицы X.
Пятая нормальная форма (5НФ) достигается в том случае, когда отношение не может далее разбиваться на более мелкие отношения посредством операции проектирования.
Под операцией проектирования понимается декомпозиция данных (без их потерь), при которой отношение разбивается на части (каждая из которых является отношением) таким образом, чтобы оставалась возможность объединить эти части в исходное отношений.
3.6. Нормализация – за и против
Целью нормализации отношений БД является устранение избыточной информации. Как видно из приведенных выше примеров, нормализованые отношения БД содержат только один элемент избыточных данных – это атрибуты связи, присутствующие одновременно в родительском и дочернем отношениях. Поскольку избыточные данные в отношениях не хранятся, то экономится место на носителях информации. Однако в нормализованной БД есть и недостатки, прежде всего, практического характера.
Чем больше число субъектов (сущностей), охватываемых предметной областью, тем из большего числа отношений будет состоять нормализованная БД. Базы данных в составе больших систем, которые задействованы в жизнедеятельности крупных организаций и предприятий, могут содержать сотни связанных между собою отношений. Поскольку порог человеческого восприятия не позволяет одновременно охватить большое число объектов с учетом их взаимосвязей, то можно утверждать, что с увеличением числа нормализованных отношений целостное восприятие БД как системы взаимосвязанных данных уменьшается. Поэтому при разработке и эксплуатации крупных систем существуют ситуации, когда каждый сотрудник представляет себе процессы, протекающие только в части системы. Известны случаи эволюционного создания таких систем, когда принципы их функционирования впоследствии выходили за границы понимания.
Другим недостатком нормализованной БД является необходимость считывать из отношений связанные данные при выполнении сложных запросов, которые предоставляют информацию о взаимодействии сущностей технологического процесса между собой. При больших объемах данных это приводит к увеличению времени доступа к данным.
Третья нормальная форма и нормальная форма Бойса-Кодда являются теоретическими конструкциями, в то время как большинство разработчиков БД работают в реальном мире. Поэтому уместно сделать несколько замечаний о недостатках, присущих отношениям, представленным в 3НФ. Существуют варианты, когда имеет смысл разделить отношение на более мелкие, если часть представленных в нём данных непостоянна и часто обновляется (оперативная информация), а остальные данные пассивны и изменяются в редких случаях (справочная информация). Также есть смысл объединить отношения, когда необходимо обеспечить высокую скорость реакции на запрос. Можно даже пойти на дублирование данных в таблицах, если это позволит снизить затраты на обработку запросов, хотя формально не следовало бы этого делать.
Необходимо также отметить, что связь между отношениями целесообразно осуществлять по атрибутам, полностью освобожденным от семантической зависимости, которая порождается особенностями реализации реальных процессов, отражаемых в БД. Для этого используют специально выделенные инкрементные атрибуты однозначной идентификации кортежей внутри отношений. Такой прием позволяет уйти от необходимости переопределения связей между отношениями при изменении в реальной жизни правил учета различных субъектов деятельности организации.
Приведенные выше соображения не следует воспринимать, как призыв вовсе не нормализовать данные. Они лишь призваны показать, что при работе с данными большого объема приходится искать компромисс между требованиями нормализации (то есть «логичности» данных и экономии места на носителях информации) и необходимостью улучшения быстродействия. При этом необходимо обращать внимание на требования пользователей, чтобы избегать излишней детализации субъектов реальных процессов, происходящих на предприятии.
Если пользователю нет необходимости детализировать атрибуты «Место рождения», «Место выдачи паспорта», «Место основной работы» и «Место жительства», то поиск компромисса между требованиями нормализации и быстродействием для отношения «ЧИТАТЕЛИ» (рис. 3.1, а) приводит к тому, что, по сути, это отношение может не соответствовать даже 1НФ (рис. 3.4). Обратите внимание, что паспортные данные читателей также не вынесены в отдельную таблицу. Это позволяет сократить время выполнения запроса, который выдает все имеющиеся данные о читателях, за счет отсутствия необходимости соединения отношений «ПАСПОРТНЫЕ ДАННЫЕ» и «ЧИТАТЕЛИ».
Рис. 3.4. Результат нормализации отношения «ЧИТАТЕЛИ»
В отличие от паспортных данных сведения о телефонных номерах читателей вынесены в отдельное отношение (рис. 3.4). Это связано с тем, что у одного читателя может быть как несколько контактных телефонов, так и не быть их вовсе. Другими словами, связь 1:М между субъектами учета и деятельности организации в подавляющем большинстве случаев необходимо реализовать с помощью двух отношений. Связь 1:1 в большинстве случаев реализуется в одном отношении.
В пользу реализации связи 1:1 между субъектами учета более чем в одном отношении говорит наличие в требованиях пользователей необходимости получения обобщающей информации по значению какого-либо атрибута. Именно это оправдывает вынесение данных о типе телефона и должности читателя в отдельные таблицы (рис. 3.4). В этом случае название должности или типа телефона указывается один раз.
Если пользователи будут вносить название должности или тип телефона непосредственно в соответствующие атрибуты отношений «ЧИТАТЕЛИ» и «ТЕЛЕФОНЫ» (рис. 3.3), то разработчики не смогут гарантировать, что из БД информация по запросам будет извлекаться корректно. Это связано с тем, что название одной и той же должности оператор может внести с синтаксической ошибкой. В этом случае стандартные алгоритмы обработки запросов пользователей к БД будут интерпретировать одинаковые по сути значения атрибута как различные.
Запрос пользователей на получение обобщающей информации может быть сформулирован так: «вывести на экран рабочие номера телефонов читателей с указанием их фамилий, имен, отчеств, мест работы и должностей», или так: «вывести на экран контактные номера телефонов всех ассистентов с указанием их фамилий, имен и отчеств».
Ввод инкрементных атрибутов «Код» позволил полностью освободиться от необходимости изменения свойств ключевых атрибутов в связи изменениями правил учета читателей в библиотеки (рис. 3.4). Они позволили несколько компенсировать увеличение необходимого объема памяти для реализации БД за счет сокращения места для атрибута, связывающего отношения «ЧИТАТЕЛИ» и «ТЕЛЕФОНЫ» с отношениями «ДОЛЖНОСТИ» и «ТИП ТЕЛЕФОНА» соответственно. Эти отношения можно было бы связать по значениям атрибутов «Наименование должности» и «Наименование типа телефона» вместо атрибутов «Код должности» и «Код типа телефона». Экономия зависит от количества знаков этих наименований, которая заложена в требованиях пользователей. Результат нормализации отношения «ЧИТАТЕЛИ» (рис. 3.4) может быть и другим. Он зависит от требований пользователей, от опыта и взгляда разработчика на процедуру нормализации отношений, необходимых для решения поставленной задачи. В нашем примере мы получили из одного отношения «ЧИТАТЕЛИ» (рис. 3.1, а) четыре отношения: «ЧИТАТЕЛИ», «ТЕЛЕФОНЫ», «ТИПЫ ТЕЛЕФОНОВ» и «ДОЛЖНОСТИ» (рис. 3.4). Отношение «ЧИТАТЕЛИ» ненормализовано. Отношение «ТЕЛЕФОНЫ» в 3НФ. Отношения «ТИПЫ ТЕЛЕФОНОВ» и «ДОЛЖНОСТИ» представлены в 1НФ.
Конечнім результатом нормализации отношений БД «БИБЛИОТЕКА» является диаграмма связей между отношениями (приложение А). Для компактности в ней указываются лишь ключевые атрибуты отношений. Связь между логической и физической моделью удобно показывать после этапа физического проектирования БД.
3.7. КОНТРОЛЬНЫЕ ВОПРОСЫ
- Что обеспечивает и гарантирует процедура нормализации?
- Какие нормальные формы отношений БД Вам известны?
- Когда отношение представлено в первой нормальной форме?
- Когда отношение представлено во второй нормальной форме?
- Когда отношение представлено в третьей нормальной форме?
- Какие нормальные формы отношений используются на практике?
- Какие нормальные формы отношений редко используются на практике?
- В каких случаях в БД можно оставить отношение, которое не приведено к 1НФ?
- Как избавиться от симантической зависимости в связях между отношениями?
- Какие существуют способы реализации связей 1:1 и 1:М в БД?
Необходимость проведения процедуры нормализации на этапе логического моделирования реляционной БД является бесспорной. При реализации логической модели необходимо разделять теоретический и практический аспекты нормализации отношений реляционной БД. На практике процедура нормализации является компромиссом между устранением избыточности данных, функциональных зависимостей и скоростью выборки и обработки данных, которая удовлетворяет конечных пользователей.
Все права защищены.
Вся информация, размещенная на данном веб-сайте, предназначена только для персонального использования и не подлежит дальнейшему воспроизведению и/или распространению в какой-либо форме, иначе как с письменного разрешения Автора.