Что происходит внутри HashMap.put()?
Мы уже рассматривали хэш-таблицы в целом, теперь рассмотрим в деталях, как новые ключ и значение складываются в HashMap.
1. Вычисляется хэш ключа. Если ключ null , хэш считается равным 0 . Чтобы достичь лучшего распределения, результат вызова hashCode() «перемешивается»: его старшие биты XOR-ятся на младшие.
2. Значения внутри хэш-таблицы хранятся в специальных структурах данных – нодах, в массиве. Из хэша высчитывается номер бакета – индекс для значения в этом массиве. Полученный хэш обрезается по текущей длине массива. Длина – всегда степень двойки, так что для скорости используется битовая операция & .
3. В бакете ищется нода. В ячейке массива лежит не просто одна нода, а связка всех нод, которые туда попали. Исполнение проходит по этой связке (цепочке или дереву), и ищет ноду с таким же ключом. Ключ сравнивается с имеющимися сначала на == , затем на equals .
4. Если нода найдена – её значение просто заменяется новым. Работа метода на этом завершается.
5. Если ноды с таким же ключом в бакете пока нет – добавляемая пара ключ-значение запаковывается в новый объект типа Node, и прикрепляется к структуре существующих нод бакета. Ноды составляют структуру за счет того, что в ноде хранится ссылка на следующий элемент (для дерева – следующие элементы). Кроме самой пары и ссылок, чтобы потом не считать заново, записывается и хэш ключа.
6. В случае, когда структурой была цепочка а не дерево, и длина цепочки превысила 7 элементов – происходит процедура treeification – превращение списка в самобалансирующееся дерево. В случае коллизии это ускоряет доступ к элементам на чтение с O(n) до O(log(n)). У comparable-ключей для балансировки используется их естественный порядок. Другие ключи балансируются по порядку имен их классов и значениям identityHashCode-ов. Для маленьких хэш-таблиц (< 64 бакетов) «одеревенение» заменяется увеличением (см. п.8).
7. Если новая нода попала в пустую ячейку, заняла новый бакет – увеличивается счетчик структурных модификаций. Изменение этого счетчика сообщит всем итераторам контейнера, что при следующем обращении они должны выбросить ConcurrentModificationException .
8. Когда количество занятых бакетов массива превысило пороговое (capacity * load factor), внутренний массив увеличивается вдвое, а для всего содержимого выполняется рехэш – все имеющиеся ноды перераспределяются по бакетам по тем же правилам, но уже с учетом нового размера.
HashMap
При работе с массивами я сравнивал их с коробочками. Слово HashMap содержит слово map — карта. Только это не пытайтесь найти сходство с картами в географическом атласе, с гуглокартами, с Яндекс.Картами или, на худой конец, с игральными картами. Это карточка в картотеке. Вы заполняете карточки какими-то данными и кладёте их в ящик. Если вы содержите гостиницу для котов, то скорее всего вы занесёте в карточку имя кота, возраст и т.п.
Класс HashMap использует хеш-таблицу для хранения карточки, обеспечивая быстрое время выполнения запросов get() и put() при больших наборах. Класс реализует интерфейс Map (хранение данных в виде пар ключ/значение). Ключи и значения могут быть любых типов, в том числе и null. При этом все ключи обязательно должны быть уникальны, а значения могут повторяться. Данная реализация не гарантирует порядка элементов.
Общий вид HashMap:
// K - это Key (ключ), V - Value (значение) class HashMap
Объявить можно следующим образом:
Map hashMap = new HashMap(); // или так Map hashMap = new HashMap();
По умолчанию при использовании пустого конструктора создается картотека ёмкостью из 16 ячеек. При необходимости ёмкость увеличивается, вам не надо об этом задумываться.

Вы можете указать свои ёмкость и коэффициент загрузки, используя конструкторы HashMap(capacity) и HashMap(capacity, loadFactor). Максимальная ёмкость, которую вы сможете установить, равна половине максимального значения int (1073741824).
Добавление элементов происходит при помощи метода put(K key, V value). Вам надо указать ключ и его значение.
hashMap.put("0", "Васька");
hashMap.size();
Проверяем ключ и значение на наличие:
hashMap.containsKey("0"); hashMap.containsValue("Васька");
Выбираем все ключи:
for (String key : hashMap.keySet())
Выбираем все значения:
for (int value : hashMap.values())
Выбираем все ключи и значения одновременно:
for (Map.Entry entry : hashMap.entrySet())
Пример первый
// Создадим хеш-карточку Map hashMap = new HashMap<>(); // Помещаем данные на карточку hashMap.put("Васька", 5); hashMap.put("Мурзик", 8); hashMap.put("Рыжик", 12); hashMap.put("Барсик", 5); // Получаем набор элементов Set set = hashMap.entrySet(); // Отобразим набор for (Map.Entry me : set) < System.out.print(me.getKey() + ": "); System.out.println(me.getValue()); >// Добавляем значение int value = hashMap.get("Рыжик"); hashMap.put("Рыжик", value + 3); System.out.println("У Рыжика стало " + hashMap.get("Рыжик"));
Если вы посмотрите на результат, то увидите, что данные находятся не в том порядке, в котором вы заносили. Второй важный момент — если в карточке уже существует какой-то ключ, то если вы помещаете в него новое значение, то ключ перезаписывается, а не заносится новый ключ.
В древних версиях Java приходилось добавлять новые значения следующим образом.
hashMap.put("Мурзик", new Integer(8)); // или hashMap.put("Мурзик", Integer.valueOf(8));
Потом Java поумнела и стала самостоятельно переводить число типа int в объект Integer. Но это не решило основной проблемы — использование объектов очень сильно сказывается на потреблении памяти. Поэтому в Android были предложены аналоги этого класса (см. ниже). Ключом в Map может быть любой объект, у которого корректно реализованы методы hashCode() и equals().
Пример второй
Так как ключи являются уникальными, мы можем написать следующую программу — сгенерируем набор случайных чисел сто раз и посчитаем количество повторов. Map легко решит эту задачу — в качестве ключа используется сгенерированное число, а в качестве значения — количество повторов.
Random random = new Random(36); Map hashMap = new HashMap<>(); for (int i = 0; i < 100; i++)< // Создадим число от 0 до 10 int number = random.nextInt(10); Integer frequency = hashMap.get(number); hashMap.put(number, frequency == null ? 1 : frequency + 1); >System.out.println(hashMap);
Метод get() возвращает null, если ключ отсутствует, т.е число было сгенерировано впервые или в противном случае метод возвращает для данного ключа ассоциированное значение, которое увеличивается на единицу.
Пример третий
Пример для закрепления материала. Поработаем с объектами классов. Нужно самостоятельно создать класс Pet и его наследников Cat, Dog, Parrot.
Создадим отображение из домашних животных, где в качестве ключа выступает строка, а в качестве значения класс Pet.
Map hashMap = new HashMap<>(); hashMap.put("Кот", new Cat("Мурзик")); hashMap.put("Собака", new Dog("Бобик")); hashMap.put("Попугай", new Parrot("Кеша")); System.out.println(hashMap); Pet cat = hashMap.get("Кот"); System.out.println(cat); System.out.println(hashMap.containsKey("Кот")); System.out.println(hashMap.containsValue(cat));
Многомерные отображения
Контейнеры Map могут расширяться до нескольких измерений, достаточно создать контейнер Map, значениями которого являются контейнеры Map (значениями которых могут быть другие контейнеры). Предположим, вы хотите хранить информацию о владельцах домашних животных, у каждого из которых может быть несколько любимцев. Для этого нам нужно создать контейнер Map>.
Map> personMap = new HashMap<>(); personMap.put(new Person("Иван"), Arrays.asList(new Cat("Барсик"), new Cat("Мурзик"))); personMap.put(new Person("Маша"), Arrays.asList(new Cat("Васька"), new Dog("Бобик"))); personMap.put(new Person("Ирина"), Arrays.asList(new Cat("Рыжик"), new Dog("Шарик"), new Parrot("Гоша"))); System.out.println("personMap: " + personMap); System.out.println("personMap.keySet(): " + personMap.keySet()); for(Person person : personMap.keySet()) < System.out.println(person + " имеет"); for (Pet pet : personMap.get(person))< System.out.println(" " + pet); >>
Метод keySet() возвращает контейнер Set, содержащий все ключи из personMap, который используется в цикле для перебора элементов Map.
Sparse arrays — аналог в Android
Разработчик Android посчитали, что HashMap не слишком оптимизирован для мобильных устройств и предложили свой вариант в виде специальных массивов. Данные классы являются родными для Android, но не являются частью Java. Очень рекомендуют использовать именно Android-классы. Не все программисты знают об этих аналогах, а также классический код может встретиться в различных Java-библиотеках. Если вы увидите такой код, то заменить его на нужный. Ниже представлена таблица для замены.
| HashMap | Array class |
|---|---|
| HashMap | ArrayMap |
| HashMap | SparseArray |
| HashMap | SparseBooleanArray |
| HashMap | SparseIntArray |
| HashMap | SparseLongArray |
| HashMap | LongSparseArray |
Существует ещё класс HashTable, который очень похож в использовании как и HashMap.
Как работает HashMap?
Один из популярнейших вопросов, потому что содержит много нюансов. Лучше всего подготовиться к нему помогает чтение исходного кода HashMap . Реализация подробно рассмотрена во множестве статей, например на хабре.
Нюансы которые стоит повторить и запомнить:
�� Общий принцип: внутренний массив table , содержащий бакеты (корзины) – списки элементов с одинаковыми пересчитанными хэш-суммами;
�� Пересчет хэш-суммы для умещения int индексов в capacity ячейках table ;
�� rehash – удвоение размера table при достижении threshold ( capacity*loadFactor ) занятых бакетов;
�� Невозможность сжать однажды раздувшийся table ;
�� Два способа разрешения коллизий: используемый в HashMap метод цепочек и альтернатива – открытая адресация;
�� Варианты для многопоточного использования: пересинхронизированная Hashtable и умная ConcurrentHashMap ;
�� Оптимизация Java 8: превращение списка в бакете в дерево при достижении 8 элементов – при большом количестве коллизий скорость доступа растет с O(n) до O(log(n));
�� Явное использование бакета 0 для ключа null ;
�� Связь с HashSet – HashMap , в котором используются только ключи;
�� Нет гарантий порядка элементов;
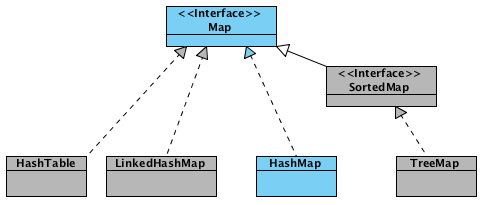
Обсуждая этот вопрос на интервью вы обязательно затронете особенности методов equals/hashCode. Возможно придется поговорить об альтернативных хранилищах ключ-значение – TreeMap, LinkedHashMap.
Структуры данных в картинках. HashMap
Продолжаю попытки визуализировать структуры данных в Java. В предыдущих сериях мы уже ознакомились с ArrayList и LinkedList, сегодня же рассмотрим HashMap.
HashMap — основан на хэш-таблицах, реализует интерфейс Map (что подразумевает хранение данных в виде пар ключ/значение). Ключи и значения могут быть любых типов, в том числе и null. Данная реализация не дает гарантий относительно порядка элементов с течением времени. Разрешение коллизий осуществляется с помощью метода цепочек.
Создание объекта
Map hashmap = new HashMap();- table — Массив типа Entry[], который является хранилищем ссылок на списки (цепочки) значений;
- loadFactor — Коэффициент загрузки. Значение по умолчанию 0.75 является хорошим компромиссом между временем доступа и объемом хранимых данных;
- threshold — Предельное количество элементов, при достижении которого, размер хэш-таблицы увеличивается вдвое. Рассчитывается по формуле (capacity * loadFactor);
- size — Количество элементов HashMap-а;
// Инициализация хранилища в конструкторе // capacity - по умолчанию имеет значение 16 table = new Entry[capacity];

Вы можете указать свои емкость и коэффициент загрузки, используя конструкторы HashMap(capacity) и HashMap(capacity, loadFactor). Максимальная емкость, которую вы сможете установить, равна половине максимального значения int (1073741824).
Добавление элементов
hashmap.put("0", "zero");-
Сначала ключ проверяется на равенство null. Если это проверка вернула true, будет вызван метод putForNullKey(value) (вариант с добавлением null-ключа рассмотрим чуть позже).
static int hash(int h) < h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); >
Комментарий из исходников объясняет, каких результатов стоит ожидать — метод hash(key) гарантирует что полученные хэш-коды, будут иметь только ограниченное количество коллизий (примерно 8, при дефолтном значении коэффициента загрузки).
В моем случае, для ключа со значением »0» метод hashCode() вернул значение 48, в итоге:
h ^ (h >>> 20) ^ (h >>> 12) = 48 h ^ (h >>> 7) ^ (h >>> 4) = 51
static int indexFor(int h, int length)
При значении хэша 51 и размере таблице 16, мы получаем индекс в массиве:
h & (length - 1) = 3
if (e.hash == hash && (e.key == key || key.equals(e.key)))
void addEntry(int hash, K key, V value, int index) < Entrye = table[index]; table[index] = new Entry(hash, key, value, e); . >

Для того чтобы продемонстрировать, как заполняется HashMap, добавим еще несколько элементов.
hashmap.put("key", "one");-
Пропускается, ключ не равен null
h ^ (h >>> 20) ^ (h >>> 12) = 106054 h ^ (h >>> 7) ^ (h >>> 4) = 99486
h & (length - 1) = 14

hashmap.put(null, null);-
Все элементы цепочки, привязанные к table[0], поочередно просматриваются в поисках элемента с ключом null. Если такой элемент в цепочке существует, его значение перезаписывается.
addEntry(0, null, value, 0);
hashmap.put("idx", "two");-
Пропускается, ключ не равен null
h ^ (h >>> 20) ^ (h >>> 12) = 104100 h ^ (h >>> 7) ^ (h >>> 4) = 101603
h & (length - 1) = 3
// В table[3] уже хранится цепочка состоящая из элемента ["0", "zero"] Entry e = table[index]; // Новый элемент добавляется в начало цепочки table[index] = new Entry(hash, key, value, e);

Resize и Transfer
Когда массив table[] заполняется до предельного значения, его размер увеличивается вдвое и происходит перераспределение элементов. Как вы сами можете убедиться, ничего сложного в методах resize(capacity) и transfer(newTable) нет.
void resize(int newCapacity) < if (table.length == MAXIMUM_CAPACITY) < threshold = Integer.MAX_VALUE; return; >Entry[] newTable = new Entry[newCapacity]; transfer(newTable); table = newTable; threshold = (int)(newCapacity * loadFactor); >
Метод transfer() перебирает все элементы текущего хранилища, пересчитывает их индексы (с учетом нового размера) и перераспределяет элементы по новому массиву.
Если в исходный hashmap добавить, скажем, еще 15 элементов, то в результате размер будет увеличен и распределение элементов изменится.

Удаление элементов
У HashMap есть такая же «проблема» как и у ArrayList — при удалении элементов размер массива table[] не уменьшается. И если в ArrayList предусмотрен метод trimToSize(), то в HashMap таких методов нет (хотя, как сказал один мой коллега — «А может оно и не надо?«).
Небольшой тест, для демонстрации того что написано выше. Исходный объект занимает 496 байт. Добавим, например, 150 элементов.
Теперь удалим те же 150 элементов, и снова замерим.
Как видно, размер даже близко не вернулся к исходному. Если есть желание/потребность исправить ситуацию, можно, например, воспользоваться конструктором HashMap(Map).
hashmap = new HashMap(hashmap);
Итераторы
HashMap имеет встроенные итераторы, такие, что вы можете получить список всех ключей keySet(), всех значений values() или же все пары ключ/значение entrySet(). Ниже представлены некоторые варианты для перебора элементов:
Инструменты для замеров — memory-measurer и Guava (Google Core Libraries).