Общие сведения о страничных BLOB-объектах Azure
Служба хранилища Azure предлагает три типа хранилища BLOB-объектов: блочные, добавочные и страничные BLOB-объекты. Блочные BLOB-объекты состоят из блоков и идеально подходят для хранения текстовых или двоичных файлов, а также для эффективной передачи больших файлов. Добавочные большие двоичные объекты также состоят из блоков, но они оптимизированы для операций добавления и поэтому полезны для сценариев ведения журнала. Страничные BLOB-объекты состоят из 512-байтовых страниц, общий размер которых не превышает 8 ТБ, и создаются для частых произвольных операций чтения и записи. Страничные BLOB-объекты являются основой дисков IaaS Azure. В этой статье рассматриваются возможности и преимущества страничных BLOB-объектов.
Страничные BLOB-объекты — это коллекция 512-байтовых страниц, которые предоставляют возможность чтения и записи произвольных диапазонов байтов. Таким образом, страничные BLOB-объекты идеально подходят для хранения структур данных на основе индексов и разреженных структур данных, таких как диски ОС и диски данных для виртуальных машин и баз данных. Например, в базе данных SQL Azure страничные BLOB-объекты используются в качестве базового постоянного хранилища для баз данных. Более того, страничные BLOB-объекты также часто используются для файлов с обновлениями на основе диапазонов.
Основные возможности страничных BLOB-объектов Azure: интерфейс REST, устойчивость базового хранилища и возможности эффективной миграции в Azure. Подробнее эти возможности рассматриваются в следующем разделе. Кроме того, страничные BLOB-объекты Azure сейчас поддерживаются в хранилищах двух типов: класса Premium и Standard. Хранилище класса Premium разработано специально для рабочих нагрузок, требующих постоянной высокой производительности и минимальных задержек, благодаря чему страничные BLOB-объекты класса Premium идеально подходят для сценариев с высокими требованиями к производительности хранилища. Хранилище класса Standard более выгодно использовать для рабочих нагрузок без особых требований к задержкам.
Ограничения
Страничные BLOB-объекты могут использовать только горячий уровень доступа, но не холодный или архивный. Дополнительные сведения об уровнях доступа см. в статье Горячий, холодный и архивный уровни доступа к данным BLOB-объектов.
Примеры вариантов использования
Рассмотрим несколько вариантов использования страничных BLOB-объектов, начиная с дисков IaaS Azure. Страничные BLOB-объекты Azure — это основа платформы виртуальных дисков IaaS Azure. Диски ОС и диски данных Azure реализуются как виртуальные диски, где данные надежно хранятся на платформе службы хранилища Azure, а затем доставляются на виртуальные машины для достижения максимальной производительности. Диски Azure хранятся в формате VHD Hyper-V и в виде страничного BLOB-объекта в службе хранилища Azure. Помимо использования виртуальных дисков для виртуальных машин IaaS Azure, страничные BLOB-объекты также поддерживают сценарии PaaS и DBaaS, например службу базы данных SQL Azure, в которой сейчас эти объекты используются для хранения данных SQL, обеспечивая выполнение произвольных операций чтения и записи для базы данных. Еще один пример: при использовании службы PaaS для общего доступа к мультимедиа для приложений совместного редактирования видео страничные BLOB-объекты обеспечивают быстрый доступ к произвольным расположениям в мультимедиа. Они также предоставляют возможность нескольким пользователям быстро и эффективно редактировать и объединять одно и то же мультимедиа.
Корпорация Майкрософт в своих основных службах, таких как Azure Site Recovery и Azure Backup, а также многие сторонние разработчики реализовали ведущие в отрасли инновационные возможности с помощью интерфейса REST страничного BLOB-объекта. Ниже приведены уникальные сценарии, реализованные в Azure.
- Управление добавочными моментальными снимками, направляемыми приложением. С помощью моментальных снимков страничного BLOB-объекта и интерфейсов REST API приложения могут сохранять контрольные точки приложения без дорогостоящего дублирования данных. Служба хранилища Azure поддерживает локальные моментальные снимки для страничных BLOB-объектов, для которых не требуется копирование всего BLOB-объекта. Общедоступные API-интерфейсы этих моментальных снимков также обеспечивают доступ к разностным данным между моментальными снимками и их копирование.
- Динамическая миграция приложения и данных из локального расположения в облако. Скопируйте локальные данные и запишите их в страничный BLOB-объект Azure через REST API, не прерывая работу виртуальной машины в локальной среде. После этого вы можете быстро выполнить отработку отказа на виртуальную машину Azure с использованием этих данных. Таким образом можно перенести виртуальные машины и виртуальные диски из локального расположения в облако с минимальным простоем, так как перенос данных происходит в фоновом режиме, а вы продолжаете использовать виртуальную машину. Простой при отработке отказа составит всего несколько минут.
- Общий доступ на основе SAS, который позволяет выполнять сценарии, такие как несколько читателей и один писатель с поддержкой управления параллелизмом.
Неуправляемые диски удаляются из эксплуатации. Дополнительные сведения см. в статье Перенос неуправляемых дисков Azure до 30 сентября 2025 г.
Цены
Два типа хранилища, предоставляемые для страничных BLOB-объектов, имеют разные модели ценообразования. Страничные BLOB-объекты уровня Premium оплачиваются так же, как управляемые диски, но страничные BLOB-объекты уровня Standard тарифицируются пропорционально используемому размеру и за каждую транзакцию. Дополнительные сведения см. на странице цен на страничные BLOB-объекты Azure.
Возможности страничных BLOB-объектов
REST API
Чтобы приступить к разработке с использованием страничных BLOB-объектов, см. статью Краткое руководство по передаче, скачиванию и составлению списка больших двоичных объектов с помощью .NET. Например, рассмотрим получение доступа к страничным BLOB-объектам с помощью клиентской библиотеки хранилища для .NET.
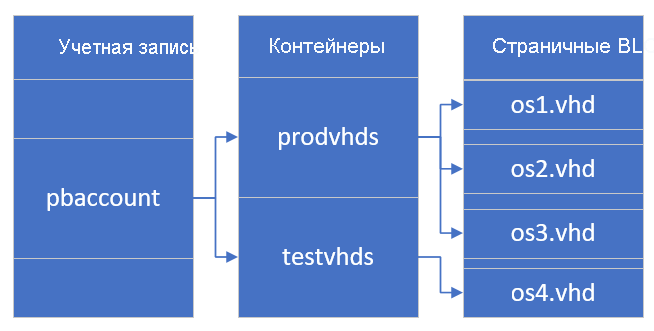
На следующей схеме изображены общие связи между учетной записью, контейнерами и страничными BLOB-объектами.
Создание пустого страничного BLOB-объекта указанного размера
Сначала получите ссылку на контейнер. Чтобы создать страничный BLOB-объект, вызовите метод GetPageBlobClient, а затем метод PageBlobClient.Create. Передайте в него максимальный размер создаваемого большого двоичного объекта. Этот размер должен быть кратен 512 байтам.
long OneGigabyteAsBytes = 1024 * 1024 * 1024; BlobServiceClient blobServiceClient = new BlobServiceClient(connectionString); var blobContainerClient = blobServiceClient.GetBlobContainerClient(Constants.containerName); var pageBlobClient = blobContainerClient.GetPageBlobClient("0s4.vhd"); pageBlobClient.Create(16 * OneGigabyteAsBytes); Изменение размера страничного BLOB-объекта
Чтобы изменить размер страничного BLOB-объекта после его создания, используйте метод Resize. Запрошенный размер должен быть кратен 512 байтам.
pageBlobClient.Resize(32 * OneGigabyteAsBytes); Запись страниц в страничный BLOB-объект
Чтобы сохранить страницы, используйте метод PageBlobClient.UploadPages.
pageBlobClient.UploadPages(dataStream, startingOffset); Это позволит записать последовательный набор страниц размером до 4 МБ. Записываемое смещение должно начинаться на границе 512 байт (startingOffset % 512 == 0), а заканчиваться на границе 512 — 1.
Как только запрос на запись последовательного набора страниц успешно выполняется в службе BLOB-объектов и реплицируется для обеспечения устойчивости, запись фиксируется и клиенту отправляется уведомление о том, что запись завершена успешно.
На схеме ниже показано 2 отдельных операции записи:

- Операция записи, начинающаяся со смещения 0 длиной 1024 байт
- Операция записи, начинающаяся со смещения 4096 длиной 1024 байт
Чтение страниц из страничного BLOB-объекта
Чтобы считать страницы, используйте метод PageBlobClient.Download, который получает диапазон байтов из страничного BLOB-объекта.
var pageBlob = pageBlobClient.Download(new HttpRange(bufferOffset, rangeSize)); Это даст возможность загрузить весь большой двоичный объект или диапазон байтов, начиная со смещения в большом двоичном объекте. При чтении смещение не должно начинаться с величины, кратной 512. При чтении байтов со страницы NUL служба возвращает нулевые байты.
На следующем рисунке показана операция чтения со смещением 256 и размером диапазона 4352. Возвращенные данные выделены оранжевым цветом. Для страниц NUL возвращаются нули.
Если большой двоичный объект является фрагментарным, возможно, потребуется загружать только значимые области страницы. Это позволит не оплачивать передачу нулевых байтов и сократить задержку при загрузке.
Чтобы определить, для каких страниц присутствуют данные, используйте метод PageBlobClient.GetPageRanges. Вы можете перечислить возвращаемые диапазоны и загрузить данные в каждом диапазоне.
IEnumerable pageRanges = pageBlobClient.GetPageRanges().Value.PageRanges; foreach (var range in pageRanges)
Сдача страничного BLOB-объекта в аренду
Операция сдачи большого двоичного объекта в аренду устанавливает блокировку на большом двоичном объекте для операций записи и удаления, а также управляет ею. Эта операция полезна, если к страничному BLOB-объекту осуществляется доступ из нескольких клиентов. При ее применении запись в большой двоичный объект в текущий момент может осуществляться только одним клиентом. К примеру, в дисках Azure этот механизм сдачи в аренду используется, чтобы управление диском осуществлялось только с одной виртуальной машины. Длительность блокировки может составлять 15–60 секунд либо быть бесконечной. Дополнительные сведения см. в этой документации.
Помимо разнообразных интерфейсов REST API, страничные BLOB-объекты обеспечивают общий доступ, устойчивость и повышенную безопасность. Далее мы рассмотрим эти преимущества подробнее.
Одновременный доступ
REST API страничного BLOB-объекта и его механизм сдачи в аренду позволяет приложениям получать доступ к страничному BLOB-объекту из нескольких клиентов. Например, предположим, что нужно создать распределенную облачную службу, которая использует объекты хранилища совместно с несколькими пользователями. Это может быть веб-приложение, обслуживающее большую коллекцию изображений для нескольких пользователей. Один из вариантов для реализации — использование виртуальной машины с подключенными дисками. К недостаткам этого относится (а) ограничение подключения диска только к одной виртуальной машине, что уменьшает масштабируемость, гибкость и повышает риски. Если возникла проблема с виртуальной машиной или службой, запущенной на виртуальной машине, по истечении срока действия аренды или ее разрыва образ будет недоступен. Кроме того, требуются дополнительные затраты на виртуальную машину IaaS.
Альтернативным вариантом является использование страничных BLOB-объектов напрямую через интерфейсы REST API службы хранилища Azure. Этот вариант не требует использования дорогостоящих виртуальных машин IaaS, предоставляет гибкие возможности прямого доступа из нескольких клиентов, упрощает классическую модель развертывания (так как не нужно подключать и отключать диски) и исключает риски возникновения проблем на виртуальной машине. И обеспечивается тот же уровень производительности для произвольных операций чтения и записи, что и на диске.
Высокая доступность и устойчивость
Хранилище уровня «Стандартный» и «Премиум» — это надежное хранилище, в котором данные страничных BLOB-объектов всегда реплицируются для обеспечения устойчивости и высокой доступности. Azure постоянно обеспечивает устойчивость корпоративных уровней для дисков IaaS и страничных BLOB-объектов с ведущим в отрасли нулевым процентом ежегодных сбоев.
Дополнительные сведения об избыточности службы хранилища Azure для учетных записей хранения уровня «Стандартный» и «Премиум» см. в статье Избыточность службы хранилища Azure и в следующих двух разделах:
- Поддерживаемые службы хранилища Azure
- Поддерживаемые типы учетных записей хранения
Простая миграция в Azure
Для клиентов и разработчиков, заинтересованных в реализации своего собственного пользовательского решения резервного копирования, Azure также предлагает добавочные моментальные снимки, которые содержат только разностные данные. Эта возможность позволяет избежать затрат на начальную полную копию, что значительно снижает расходы на резервное копирование. Помимо возможности эффективно считывать и копировать разностные данные есть другая эффективная возможность, которая помогает внедрить еще больше инноваций от разработчиков, обеспечивая лучшие в своем классе резервное копирование и аварийное восстановление. Вы можете настроить свое собственное решение резервного копирования или аварийного восстановления для виртуальных машин в Azure, используя моментальные снимки больших двоичных объектов, интерфейс API Get Page Ranges и интерфейс API Incremental Copy Blob, с помощью которого можно легко копировать добавочные данные для аварийного восстановления.
Кроме того, во многих предприятиях важные рабочие нагрузки уже запущены в центрах обработки данных в локальной среде. При переносе рабочей нагрузки в облако одной из основных проблем является время простоя, необходимое для копирования данных, и риск возникновения других непредвиденных проблем после переключения. Во многих случаях простой может быть препятствием для миграции в облако. Используя REST API страничных BLOB-объектов, Azure устраняет эту проблему, обеспечивая перенос в облако с минимальными нарушениями работы важных рабочих нагрузок.
Примеры создания моментального снимка и восстановления страничного BLOB-объекта из моментального снимка см. в статье о настройке процесса резервного копирования с помощью добавочных моментальных снимков.
Руководство. Использование хранилища BLOB-объектов Azure с SQL Server
В этом руководстве показано, как использовать хранилище BLOB-объектов Azure для файлов данных и резервных копий в SQL Server 2016 и более поздних версиях.
Поддержка интеграции SQL Server для хранилища BLOB-объектов Azure началась в качестве усовершенствования с пакетом обновления 1 (SP1) с пакетом обновления 1 (SP2) SQL Server 2014 и SQL Server 2016. Обзор возможностей и преимуществ использования этих функций см. в статье Файлы данных SQL Server в Microsoft Azure.
В этом руководстве в нескольких разделах показано, как работать с файлами данных SQL Server в Хранилище BLOB-объектов Azure. В каждом разделе рассматривается определенная задача, и их следует выполнять по порядку. Сначала вы узнаете, как создать контейнер в Хранилище BLOB-объектов с помощью хранимой политики доступа и подписанного URL-адреса. Затем вы узнаете, как создать учетные данные SQL Server, чтобы интегрировать SQL Server с Хранилищем BLOB-объектов Azure. Далее вы выполните резервное копирование базы данных в Хранилище BLOB-объектов и восстановите ее в виртуальной машине Azure. Затем вы будете использовать резервную копию журнала транзакций моментального снимка файлов SQL Server для восстановления до точки во времени и в новую базу данных. Наконец, в учебнике будет продемонстрировано использование хранимых процедур и функций системы метаданных, что позволит вам понять, как работать с резервными копиями моментальных снимков файлов.
Предварительные условия
Для работы с этим руководством необходимо ознакомиться с понятиями резервного копирования и восстановления SQL Server и синтаксисом T-SQL.
Чтобы использовать это руководство, вам потребуется учетная запись хранения Azure, СРЕДА SQL Server Management Studio (SSMS), доступ к экземпляру локальной среды SQL Server, доступ к виртуальной машине Azure под управлением экземпляра SQL Server 2016 или более поздней версии и AdventureWorks2022 базы данных. Кроме того, учетная запись, используемая для выдачи команд резервного копирования и восстановления, должна находиться в роли базы данных db_backupoperator с разрешениями изменение любых учетных данных.
- Получите бесплатную учетную запись Azure.
- Создайте учетную запись хранения Azure.
- Установите выпуск SQL Server 2017 Developer Edition.
- Подготовка виртуальной машины Azure под управлением SQL Server
- Установите SQL Server Management Studio.
- Скачайте примеры баз данных AdventureWorks.
- Назначьте учетной записи пользователя роль db_backupoperator и предоставьте разрешения на изменение любых учетных данных.
SQL Server не поддерживает Azure Data Lake Storage, убедитесь, что иерархическое пространство имен не включено в учетной записи хранения, используемой для этого руководства.
1. Создание хранимой политики доступа и хранилища с общим доступом
В этом разделе описан сценарий Azure PowerShell для создания подписанного URL-адреса в контейнере хранилища BLOB-объектов Azure с помощью хранимой политики доступа.
Этот скрипт написан с помощью Azure PowerShell 5.0.10586.
Подписанный URL-адрес — это универсальный код ресурса (URI), который предоставляет ограниченные права доступа к контейнерам, большим двоичным объектам, очередям и таблицам. Хранимая политика доступа предоставляет дополнительный уровень контроля над сервером, включая отзыв, истечение срока действия и продление доступа. При использовании этого расширения необходимо создать политику в контейнере как минимум с правами на чтение, запись и перечисление.
Хранимую политику доступа и подписанный URL-адрес можно создать с помощью Azure PowerShell, пакета SDK службы хранилища Azure, REST API Azure или служебной программы стороннего разработчика. В этом учебнике демонстрируется применение скрипта Azure PowerShell для выполнения данной задачи. В скрипте используется модель развертывания диспетчера ресурсов и создаются следующие ресурсы:
- Группа ресурсов
- Учетная запись хранения
- Контейнер хранилища BLOB-объектов Azure
- Политика SAS
Выполнение скрипта начинается с объявления ряда переменных для указания имен перечисленных выше ресурсов и имен следующих обязательных входных значений:
- имя префикса, используемое для именования других объектов ресурсов;
- Имя подписки
- расположение центра обработки данных.
В результате выполнения скрипта создается соответствующая инструкция CREATE CREDENTIAL, которая будет использоваться в разделе 2. Создание учетных данных SQL Server с помощью подписанного URL-адреса. Эта инструкция копируется в буфер обмена и выводится в консоль.
Чтобы создать политику в контейнере и создать подписанный URL-адрес (SAS), выполните следующие действия.
- Откройте интегрированную среду сценариев Window PowerShell или Windows PowerShell (см. требования к версии выше).
- Измените, а затем выполните приведенный ниже скрипт:
# Define global variables for the script $prefixName = '' # used as the prefix for the name for various objects $subscriptionID = '' # the ID of subscription name you will use $locationName = '' # the data center region you will use $storageAccountName= $prefixName + 'storage' # the storage account name you will create or use $containerName= $prefixName + 'container' # the storage container name to which you will attach the SAS policy with its SAS token $policyName = $prefixName + 'policy' # the name of the SAS policy # Set a variable for the name of the resource group you will create or use $resourceGroupName=$prefixName + 'rg' # Add an authenticated Azure account for use in the session Connect-AzAccount # Set the tenant, subscription and environment for use in the rest of Set-AzContext -SubscriptionId $subscriptionID # Create a new resource group - comment out this line to use an existing resource group New-AzResourceGroup -Name $resourceGroupName -Location $locationName # Create a new Azure Resource Manager storage account - comment out this line to use an existing Azure Resource Manager storage account New-AzStorageAccount -Name $storageAccountName -ResourceGroupName $resourceGroupName -Type Standard_RAGRS -Location $locationName # Get the access keys for the Azure Resource Manager storage account $accountKeys = Get-AzStorageAccountKey -ResourceGroupName $resourceGroupName -Name $storageAccountName # Create a new storage account context using an Azure Resource Manager storage account $storageContext = New-AzStorageContext -StorageAccountName $storageAccountName -StorageAccountKey $accountKeys[0].Value # Creates a new container in Blob Storage $container = New-AzStorageContainer -Context $storageContext -Name $containerName # Sets up a Stored Access Policy and a Shared Access Signature for the new container $policy = New-AzStorageContainerStoredAccessPolicy -Container $containerName -Policy $policyName -Context $storageContext -StartTime $(Get-Date).ToUniversalTime().AddMinutes(-5) -ExpiryTime $(Get-Date).ToUniversalTime().AddYears(10) -Permission rwld # Gets the Shared Access Signature for the policy $sas = New-AzStorageContainerSASToken -name $containerName -Policy $policyName -Context $storageContext Write-Host 'Shared Access Signature= '$($sas.Substring(1))'' # Sets the variables for the new container you just created $container = Get-AzStorageContainer -Context $storageContext -Name $containerName $cbc = $container.CloudBlobContainer # Outputs the Transact SQL to the clipboard and to the screen to create the credential using the Shared Access Signature Write-Host 'Credential T-SQL' $tSql = "CREATE CREDENTIAL [] WITH IDENTITY='Shared Access Signature', SECRET=''" -f $cbc.Uri,$sas.Substring(1) $tSql | clip Write-Host $tSql # Once you're done with the tutorial, remove the resource group to clean up the resources. # Remove-AzResourceGroup -Name $resourceGroupName 2. Создание учетных данных SQL Server с помощью подписанного URL-адреса
В этом разделе вы создадите учетные данные для хранения сведений о безопасности, которые будут использоваться SQL Server для записи и чтения из контейнера хранилища BLOB-объектов Azure, созданного на предыдущем шаге.
Учетные данные SQL Server — это объект, который используется для хранения сведений, необходимых для проверки подлинности при подключении к ресурсу вне SQL Server. Учетные данные хранят URI-путь контейнера хранилища BLOB-объектов Azure и подписанный URL-адрес для этого контейнера.
Чтобы создать учетные данные SQL Server, выполните указанные ниже действия.
- Запустите среду SSMS.
- Откройте новое окно запроса и подключитесь к экземпляру SQL Server ядра СУБД в локальной среде.
- В новое окно запроса вставьте инструкцию CREATE CREDENTIAL с подписанным URL-адресом из раздела 1, а затем выполните этот скрипт. Код скрипта будет выглядеть следующим образом.
/* Example: USE master CREATE CREDENTIAL [https://msfttutorial.blob.core.windows.net/containername] WITH IDENTITY='SHARED ACCESS SIGNATURE' , SECRET = 'sharedaccesssignature' GO */ USE master CREATE CREDENTIAL [https://.blob.core.windows.net/] -- this name must match the container path, start with https and must not contain a forward slash at the end WITH IDENTITY='SHARED ACCESS SIGNATURE' -- this is a mandatory string and should not be changed , SECRET = 'sharedaccesssignature' -- this is the shared access signature key that you obtained in section 1. GO SELECT * from sys.credentials 3. Резервное копирование базы данных по URL-адресу
В этом разделе описано, как создать AdventureWorks2022 резервную копию базы данных в экземпляре SQL Server, в контейнер, созданный в разделе 1.
Если вы хотите создать резервную копию базы данных SQL Server 2012 (11.x) с пакетом обновления 1 (SP1) или базы данных SQL Server 2014 (12.x) в этом контейнере, можно использовать устаревший синтаксис, описанный здесь , для резервного копирования по URL-адресу с помощью синтаксиса WITH CREDENTIAL .
Чтобы создать резервную копию базы данных в хранилище BLOB-объектов, выполните следующие действия.
- Запустите среду SSMS.
- Откройте новое окно запроса и подключитесь к экземпляру SQL Server в виртуальной машине Azure.
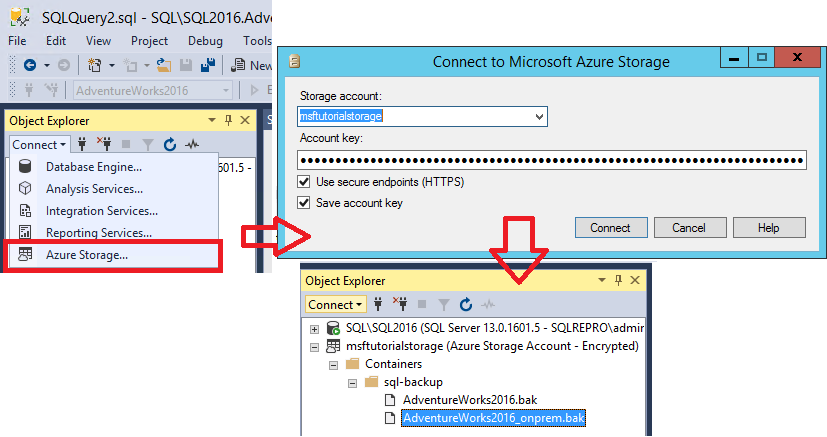
- Скопируйте и вставьте приведенный ниже скрипт Transact-SQL в окне запроса. Измените в URL-адресе имя учетной записи хранения и контейнер, которые вы указали ранее в разделе 1, а затем выполните этот скрипт.
-- To permit log backups, before the full database backup, modify the database to use the full recovery model. USE master; ALTER DATABASE AdventureWorks2022 SET RECOVERY FULL; -- Back up the full AdventureWorks2022 database to the container that you created in section 1 BACKUP DATABASE AdventureWorks2022 TO URL = 'https://.blob.core.windows.net//AdventureWorks2022_onprem.bak' - Разверните контейнеры, разверните контейнер, созданный в разделе 1, и убедитесь, что резервная копия из шага 3 выше отображается в этом контейнере.
4. Восстановление базы данных на виртуальной машине по URL-адресу
В этом разделе вы восстановите AdventureWorks2022 базу данных в экземпляре SQL Server на виртуальной машине Azure.
В целях упрощения в этом учебнике для файлов данных и журналов применяется тот же контейнер, который использовался для резервной копии базы данных. В рабочей среде обычно используется несколько контейнеров, а также несколько файлов данных. Вы также можете рассмотреть возможность чередовать резервную копию по нескольким blob-объектам, чтобы повысить производительность резервного копирования при резервном копировании большой базы данных.
Чтобы восстановить AdventureWorks2022 базу данных из хранилища BLOB-объектов Azure в экземпляр SQL Server на виртуальной машине Azure, выполните следующие действия.
- Запустите среду SSMS.
- Откройте новое окно запроса и подключитесь к экземпляру SQL Server ядра СУБД на виртуальной машине Azure.
- Скопируйте и вставьте приведенный ниже скрипт Transact-SQL в окне запроса. Измените в URL-адресе имя учетной записи хранения и контейнер, которые вы указали ранее в разделе 1, а затем выполните этот скрипт.
-- Restore AdventureWorks2022 from URL to SQL Server instance using Azure Blob Storage for database files RESTORE DATABASE AdventureWorks2022 FROM URL = 'https://.blob.core.windows.net//AdventureWorks2022_onprem.bak' WITH MOVE 'AdventureWorks2022_data' to 'https://.blob.core.windows.net//AdventureWorks2022_Data.mdf' ,MOVE 'AdventureWorks2022_log' to 'https://.blob.core.windows.net//AdventureWorks2022_Log.ldf' --, REPLACE - Щелкните правой кнопкой мыши AdventureWorks2022 и выберите «Свойства«.
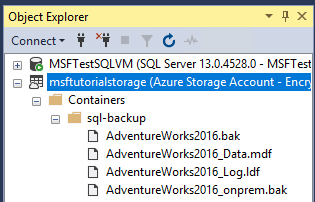
- Выберите файлы и убедитесь, что пути для двух файлов базы данных являются URL-адресами, указывающими на большие двоичные объекты в контейнере хранилища BLOB-объектов Azure (нажмите кнопку «Отмена » при завершении).
] database on the Azure VM.](https://learn.microsoft.com/ru-ru/sql/relational-databases/media/tutorial-use-azure-blob-storage-service-with-sql-server-2016/adventureworks-on-azure-vm.png?view=sql-server-ver16)
- Разверните контейнеры, разверните контейнер, созданный в разделе 1, и убедитесь, что AdventureWorks2022_Data.mdf в этом контейнере отображается и AdventureWorks2022_Log.ldf из шага 3 выше, а также файл резервной копии из раздела 3 (при необходимости обновите узел).
5. Резервное копирование базы данных с помощью резервного копирования моментальных снимков файлов
В этом разделе описано, как создать AdventureWorks2022 резервную копию базы данных в виртуальной машине Azure с помощью резервного копирования моментальных снимков файлов для выполнения почти мгновенной резервной копии с помощью моментальных снимков Azure. Дополнительные сведения о резервных копиях моментальных снимков файлов см. в разделе Резервные копии моментальных снимков файлов для файлов базы данных в Azure.
Чтобы создать резервную копию базы данных с помощью резервного AdventureWorks2022 копирования моментальных снимков файлов, выполните следующие действия.
- Запустите среду SSMS.
- Откройте новое окно запроса и подключитесь к экземпляру SQL Server ядра СУБД на виртуальной машине Azure.
- Скопируйте и вставьте приведенный ниже скрипт Transact-SQL в окно запроса, а затем выполните его (не закрывайте окно запроса — этот скрипт необходимо будет выполнить еще раз на шаге 5). Эта системная хранимая процедура позволяет просмотреть существующие резервные копии моментальных снимков файлов для каждого файла, входящего в состав указанной базы данных. Обратите внимание на то, что для данной базы данных резервных копий моментальных снимков файлов нет.
-- Verify that no file snapshot backups exist SELECT * FROM sys.fn_db_backup_file_snapshots ('AdventureWorks2022'); -- Backup the AdventureWorks2022 database with FILE_SNAPSHOT BACKUP DATABASE AdventureWorks2022 TO URL = 'https://.blob.core.windows.net//AdventureWorks2022_Azure.bak' WITH FILE_SNAPSHOT; -- Verify that two file-snapshot backups exist SELECT * FROM sys.fn_db_backup_file_snapshots ('AdventureWorks2022'); 
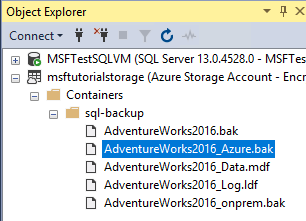
6. Создание действия и журнала резервного копирования с помощью резервного копирования моментальных снимков файлов
В этом разделе описано, как создать действия в AdventureWorks2022 базе данных и периодически создавать резервные копии журналов транзакций с помощью резервных копий моментальных снимков файлов. Дополнительные сведения об использовании резервных копий моментальных снимков файлов см. в разделе Резервные копии моментальных снимков файлов для файлов базы данных в Azure.
Чтобы создать действия в AdventureWorks2022 базе данных и периодически создавать резервные копии журналов транзакций с помощью резервных копий моментальных снимков файлов, выполните следующие действия.
- Запустите среду SSMS.
- Откройте два новых окна запросов и подключите каждый экземпляр SQL Server ядра СУБД в виртуальной машине Azure.
- Скопируйте и вставьте приведенный ниже скрипт Transact-SQL в одно из окон запросов, а затем выполните этот скрипт. Обратите внимание, что в Production.Location таблице есть 14 строк, прежде чем добавлять новые строки на шаге 4.
-- Verify row count at start SELECT COUNT (*) from AdventureWorks2022.Production.Location; -- Insert 30,000 new rows into the Production.Location table in the AdventureWorks2022 database in batches of 75 DECLARE @count INT=1, @inner INT; WHILE @count < 400 BEGIN BEGIN TRAN; SET @inner =1; WHILE @inner --take 7 transaction log backups with FILE_SNAPSHOT, one per minute, and include the row count and the execution time in the backup file name DECLARE @count INT=1, @device NVARCHAR(120), @numrows INT; WHILE @count .blob.core.windows.net//tutorial-' + CONVERT (varchar(10),@numrows) + '-' + FORMAT(GETDATE(), 'yyyyMMddHHmmss') + '.bak'; BACKUP LOG AdventureWorks2022 TO URL = @device WITH FILE_SNAPSHOT; SELECT * from sys.fn_db_backup_file_snapshots ('AdventureWorks2022'); WAITFOR DELAY '00:1:00'; SET @count = @count + 1; END; 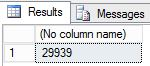
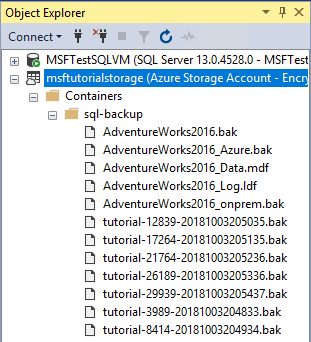
7. Восстановление базы данных на момент времени
В этом разделе вы восстановите AdventureWorks2022 базу данных до точки во времени между двумя резервными копиями журнала транзакций.
Чтобы выполнить восстановление на определенный момент времени из традиционных резервных копий, потребуется полная резервная копия базы данных, возможно, разностная резервная копия и все файлы журналов транзакций вплоть до того момента, на который необходимо выполнить восстановление, и сразу после него. При использовании резервных копий моментальных снимков файлов требуются только два ближайших файла резервных копий журнала с обеих сторон от целевой точки восстановления. Требуются только два резервных набора моментальных снимков файлов, так как каждая операция резервного копирования журнала создает моментальный снимок каждого файла базы данных (то есть файла данных и файла журнала).
Чтобы восстановить базу данных на определенный момент времени из резервных наборов моментальных снимков файлов, выполните указанные ниже действия.
- Запустите среду SSMS.
- Откройте новое окно запроса и подключитесь к экземпляру SQL Server ядра СУБД на виртуальной машине Azure.
- Скопируйте и вставьте приведенный ниже скрипт Transact-SQL в окно запроса, а затем выполните его. Убедитесь, что Production.Location таблица содержит 29 939 строк, прежде чем восстановить ее до точки во времени, когда на шаге 4 меньше строк.
-- Verify row count at start SELECT COUNT (*) from AdventureWorks2022.Production.Location
Скопируйте и вставьте приведенный ниже скрипт Transact-SQL в окне запроса. Выберите два смежных файла резервных копий журнала и укажите вместо их имен дату и время, требуемые для этого скрипта. В URL-адресе измените имя учетной записи хранения и контейнер, которые вы указали в разделе 1, укажите имена файлов для первой и второй резервных копий, укажите время STOPAT в формате "June 26, 2018 01:48 PM" (26 июня, 2018 13:48), а затем выполните этот скрипт. Выполнение скрипта займет несколько минут.
-- restore and recover to a point in time between the times of two transaction log backups, and then verify the row count ALTER DATABASE AdventureWorks2022 SET SINGLE_USER WITH ROLLBACK IMMEDIATE; RESTORE DATABASE AdventureWorks2022 FROM URL = 'https://.blob.core.windows.net//.bak' WITH NORECOVERY,REPLACE; RESTORE LOG AdventureWorks2022 FROM URL = 'https://.blob.core.windows.net//.bak' WITH RECOVERY, STOPAT = 'June 26, 2018 01:48 PM'; ALTER DATABASE AdventureWorks2022 set multi_user; -- get new count SELECT COUNT (*) FROM AdventureWorks2022.Production.Location ; 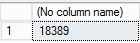
8. Восстановление новой базы данных из резервной копии журнала
В этом разделе вы восстановите AdventureWorks2022 базу данных в качестве новой базы данных из резервной копии журнала транзакций моментального снимка файлов.
В этом сценарии вы восстановите базу данных в экземпляре SQL Server на другой виртуальной машине, предназначенной для бизнес-анализа и создания отчетов. Восстановление в другом экземпляре, размещенном в другой виртуальной машине, позволяет перенести нагрузку на выделенную виртуальную машину, специально предназначенную для этой цели, и снизить требования к ресурсам, предъявляемые к системе обработки транзакций.
Восстановление из резервной копии журнала транзакций, созданной посредством резервного копирования моментальных снимков файлов, выполняется очень быстро — существенно быстрее, чем при использовании традиционных потоковых резервных копий. В случае с традиционными потоковыми резервными копиями вам потребовалось бы использовать полную резервную копию базы данных, а также, возможно, разностную резервную копию и все или часть резервных копий журнала транзакций (либо новую полную резервную копию базы данных). При использовании же резервных копий журнала на основе моментальных снимков файлов требуется только самая последняя резервная копия журнала (либо любая другая резервная копия журнала, либо две смежные резервные копии журнала для восстановления на определенный момент времени). Если точнее, требуется только один резервный набор моментальных снимков файлов, так как каждая операция резервного копирования журнала с помощью моментальных снимков файлов создает моментальный снимок каждого файла базы данных (то есть файла данных и файла журнала).
Чтобы выполнить восстановление в новую базу данных из резервной копии журнала транзакций, созданной посредством резервного копирования моментальных снимков файлов, выполните указанные ниже действия.
- Запустите среду SSMS.
- Откройте новое окно запроса и подключитесь к экземпляру ЯДРА СУБД SQL Server в виртуальной машине Azure.
Заметка Если это не та виртуальная машина Azure, которую вы использовали в предыдущих разделах, выполните инструкции из раздела 2. Создание учетных данных SQL Server с помощью подписанного URL-адреса. Если вы хотите восстановить данные в другой контейнер, выполните для нового контейнера действия из раздела 1. Создание хранимой политики доступа и хранилища с общим доступом.
-- restore as a new database from a transaction log backup file RESTORE DATABASE AdventureWorks2022_EOM FROM URL = 'https://.blob.core.windows.net//' WITH MOVE 'AdventureWorks2022_data' to 'https://.blob.core.windows.net//AdventureWorks2022_EOM_Data.mdf' , MOVE 'AdventureWorks2022_log' to 'https://.blob.core.windows.net//AdventureWorks2022_EOM_Log.ldf' , RECOVERY --, REPLACE 
9. Управление резервными наборами данных и резервными копиями моментальных снимков файлов
В этом разделе описано, как удалить резервный набор с помощью хранимой процедуры sp_delete_backup (Transact-SQL ). Эта процедура удаляет файл резервной копии и моментальный снимок файла для каждого файла базы данных, связанного с резервным набором данных.
Если вы пытаетесь удалить резервный набор, просто удалив файл резервной копии из контейнера хранилища BLOB-объектов Azure, то будет удален только сам файл резервной копии. Связанные моментальные снимки файлов останутся. Если вы найдете себя в этом сценарии, используйте системную функцию sys.fn_db_backup_file_snapshots (Transact-SQL), чтобы определить URL-адрес моментальных снимков потерянных файлов и использовать хранимую процедуру sp_delete_backup_file_snapshot (Transact-SQL), чтобы удалить каждый потерянный моментальный снимок файла. Дополнительные сведения см. в разделе Резервные копии моментальных снимков файлов для файлов базы данных в Azure.
Чтобы удалить резервный набор моментальных снимков файлов, выполните указанные ниже действия.
- Запустите среду SSMS.
- Откройте новое окно запроса и подключитесь к экземпляру ядра СУБД SQL Server в виртуальной машине Azure (или к любому экземпляру SQL Server с разрешениями на чтение и запись в этом контейнере).
- Скопируйте и вставьте приведенный ниже скрипт Transact-SQL в окне запроса. Выберите резервную копию журнала, которую нужно удалить вместе со связанными моментальными снимками файлов. В URL-адресе измените имя учетной записи хранения и контейнер, которые вы указали в разделе 1, укажите имя файла резервной копии журнала, а затем выполните этот скрипт.
sys.sp_delete_backup 'https://.blob.core.windows.net//tutorial-21764-20181003205236.bak'; 
-- verify that two file snapshots have been removed SELECT * from sys.fn_db_backup_file_snapshots ('AdventureWorks2022'); 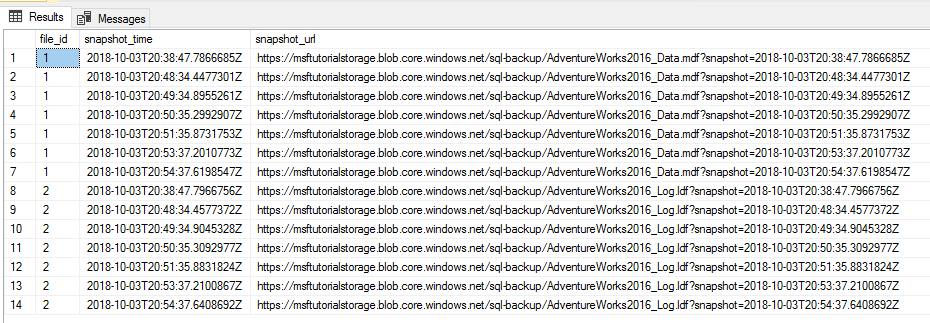
10. Удаление ресурсов
Когда вы закончите работу с этим руководством, не забудьте в целях экономии ресурсов удалить группу ресурсов, созданную в этом руководстве.
Чтобы удалить группу ресурсов, выполните следующий код PowerShell:
# Define global variables for the script $prefixName = '' # should be the same as the beginning of the tutorial # Set a variable for the name of the resource group you will create or use $resourceGroupName=$prefixName + 'rg' # Adds an authenticated Azure account for use in the session Connect-AzAccount # Set the tenant, subscription and environment for use in the rest of Set-AzContext -SubscriptionId $subscriptionID # Remove the resource group Remove-AzResourceGroup -Name $resourceGroupName Далее
- Файлы данных SQL Server в Microsoft Azure
- Резервные копии моментальных снимков файлов базы данных в Azure
- Резервное копирование SQL Server в указанное расположение.
- Использование подписанных URL-адресов (SAS)
- Create Container
- Set Container ACL
- Get Container ACL
- Учетные данные (ядро СУБД)
- CREATE CREDENTIAL (Transact-SQL)
- sys.credentials (Transact-SQL)
- sp_delete_backup (Transact-SQL)
- sys.fn_db_backup_file_snapshots (Transact-SQL)
- sp_delete_backup_file_snapshot (Transact-SQL)
- Резервные копии моментальных снимков файлов базы данных в Azure
ТИПЫ БОЛЬШИХ ДАННЫХ: BLOB и CLOB
До OpenEdge 10 работа с данными ограничивалась максимальным объемом 32K. В OpenEdge 10 были введены новые типы данных, которые позволили работать с объемами данных превышающие данное ограничение.
BLOB (Binary Large Object) - тип данных предназначен для хранение больших бинарных данных, таких как картинки, аудио - видео записи и т.д.
CLOB (Character Large Object) - тип данных предназначен для хранения больших текстовых данных заданной кодировки.
Третьим типом данных для работы с большими объемами данных, появившемся с OpenEdge 10 является тип LONGCHAR, но о нем мы уже говорили.
Стоит отметить, что в отличие от типа данных LONGCHAR, типы данных BLOB и CLOB могут быть определены только для полей таблиц и не могут быть определены для переменных.
РАБОТА С ТИПАМИ БОЛЬШИХ ДАННЫХ
COPY-LOB осуществляет копирование больших типов данных. При этом невозможно напрямую осуществлять копирование данных между типами BLOB и CLOB. Для этого необходимо скопировать данные из CLOB или BLOB источников в MEMPTR или LONGCHAR с преобразованием данных, а впоследствии уже осуществить копирование из MEMPTR или LONGCHAR в CLOB или BLOB .
COPY-LOB [FROM]source-lob | FILE source-filename>
[STARTING AT n] [FOR length]
TO target-lob> [OVERLAY AT n [TRIM]] |
FILE target-filename [APPEND]>
[NO-COVERT | CONVERT <[SOURCE CODEPAGE codepage]
[TARGET CODEPAGE codepage]>]
[NO-ERROR].
FROM - определяет источник данных для копирования:
[OBJECT] source-lob - определяет источник данных для копирования в качестве которого может выступать переменные MEMPTR или LONGCHAR типа, либо поля таблиц типов BLOB и CLOB.
FILE source-filename - определяет имя файла, содержимое которого необходимо скопировать.
STARTING AT n - определяет целочисленное значение позиции, с которой начинается чтение данных из источника. Если позиция не определена, то по умолчанию она принимается равное 1. Для байтовых типов данных таких как BLOB или MEMPTR стартовая позиция определяет позицию байта, а для текстовых типов, таких как CLOB или LONGCHAR - позицию символа с которого начинается чтение данных.
FOR length - определяет целочисленное значение байт для байтовых источников данных, или количество символов для текстовых типов, которое необходимо скопировать. По умолчанию, читаются все данные до конца.
ТО - определяет приемник копируемых данных:
[OBJECT] target-lob - определяет приемник копируемых данных, в качестве которого могут выступать переменные MEMPTR или LONGCHAR типа, либо поля таблиц типов BLOB и CLOB.
OVERLAY AT n [TRIM] - определяет целочисленное значение позиции, с которой начинается вставка копируемых данных в источник. Если позиция не определена, то по умолчанию она принимается равное 1. Для байтовых типов данных, таких как BLOB или MEMPTR, стартовая позиция определяет позицию байта, а для текстовых типов, таких как CLOB или LONGCHAR - позицию символа с которого начинается вставка данных.
FILE target-filename [APPEND] - определяет имя файла, в который осуществляется копирование данных.
NO-CONVERT - не осуществлять конвертацию копируемых данных.
CONVERT <[SOURCE CODEPAGE codepage] [TARGET CODEPAGE codepage]> - осуществляет конвертацию копируемых данных.
Представленный ниже код загрузит содержимое файла test.xml в переменную iXML.
DEF VAR iXML AS LONGCHAR NO-UNDO.
COPY-LOB FROM FILE "./test.xml" TO iXML NO-CONVERT.
Как хранить изображения в MySQL с помощью BLOB

BLOB (или Binary Large Object, большой двоичный объект) – это тип данных MySQL, который позволяет хранить двоичные данные: изображения, мультимедиа и файлы PDF.
Хранить изображения (такие как фотографии и подписи) в базе данных MySQL вместе с другой информацией удобно в том случае, если вы разрабатываете приложения с сильной привязкой к БД (например, портал поиска работы, база данных студентов или финансовое приложение), и в этой БД изображения должны быть синхронизированы с другими данными.
И тогда на помощь приходит тип данных BLOB. Этот подход устраняет необходимость в создании отдельной файловой системы для хранения изображений, а также централизует базу данных, делая ее более портативной и надежной, поскольку данные изолированы от файловой системы. А еще это упрощает создание резервных копий, поскольку вы можете создать один дамп MySQL, содержащий все ваши данные.
Извлечение данных обрабатывается быстрее, а при создании новых записей вы можете быть уверены, что правила проверки данных и ссылочная целостность четко соблюдены (особенно при использовании транзакций MySQL).
В этом мануале мы расскажем о том, как использовать тип данных BLOB для хранения изображений с помощью PHP.
Требования
- Сервер Ubuntu 18.04, предварительно настроенный согласно этим инструкциям.
- Стек LAMP, установленный на вашем сервере. С установкой вам поможет этот мануал (раздел о виртуальных хостах можно пропустить, здесь мы не будем их использовать).
1: Создание базы данных
Давайте начнем с создания тестовой базы данных для этого проекта. Подключитесь к серверу по SSH, а затем выполните следующую команду, чтобы войти на сервер MySQL как пользователь root:
sudo mysql -u root -p
Введите root-пароль базы данных MySQL и нажмите Enter, чтобы продолжить.
После этого выполните следующую команду, чтобы создать базу данных. В этом руководстве мы назовем ее test_company:
CREATE DATABASE test_company;
После создания БД вы увидите следующее:
Query OK, 1 row affected (0.01 sec)
Теперь нам нужно создать на сервере MySQL учетную запись test_user; не забудьте заменить PASSWORD сложным паролем:
CREATE USER 'test_user'@'localhost' IDENTIFIED BY 'PASSWORD';
Вы получите следующий результат:
Query OK, 0 rows affected (0.01 sec)
Чтобы предоставить пользователю test_user полные права доступа к базе данных test_company, запустите команду:
GRANT ALL PRIVILEGES ON test_company.* TO 'test_user'@'localhost';
Вы должны получить следующий результат:
Query OK, 0 rows affected (0.01 sec)
В завершение нужно сбросить таблицы привилегий, чтобы MySQL перезагрузил права:
На экране должно появиться:
Query OK, 0 rows affected (0.01 sec)
Теперь, когда база данных test_company и пользователь test_user готовы, мы можем перейти к созданию таблицы. Предположим, нам нужна таблица products для хранения списка товаров. Позже мы попробуем вставить и извлечь данные из этой таблицы, чтобы понять, как работает BLOB в MySQL.
Выйдите из оболочки MySQL:
Затем снова войдите в систему, на этот раз – как пользователь test_user:
mysql -u test_user -p
При появлении запроса введите пароль test_user и нажмите Enter, чтобы продолжить. Затем откройте базу данных test_company, набрав команду:
Перейдя в базу данных test_company, MySQL отобразит такой результат:
Затем создайте таблицу products:
CREATE TABLE `products` (product_id BIGINT PRIMARY KEY AUTO_INCREMENT, product_name VARCHAR(50), price DOUBLE, product_image BLOB) ENGINE = InnoDB;
Эта команда создаст таблицу по имени products. В таблице будет четыре столбца:
- product_id: в этом столбце используется тип данных BIGINT, он позволяет вместить большой список продуктов, содержащий 2⁶³-1 элементов. Мы пометили столбец как PRIMARY KEY, чтобы присвоить товарам уникальные идентификаторы. Чтобы MySQL мог обрабатывать создание новых идентификаторов, мы использовали ключевое слово AUTO_INCREMENT.
- product_name: этот столбец содержит названия товаров. Здесь мы использовали тип данных VARCHAR, так как это поле обычно обрабатывает буквенно-цифровые значения длиной до 50 символов; ограничение в 50 символов – это всего лишь гипотетическое значение, используемое для целей этого руководства.
- price: этот столбец содержит розничные цены наших товаров. Поскольку цена на некоторые товары может выражаться числом с плавающей точкой (например, 23.69, 45.36, 102.99), мы указали здесь тип данных DOUBLE.
- product_image: в этом столбце мы указали тип данных BLOB, поскольку он предназначен для хранения двоичных данных – изображений товаров.
Для поддержки широкого спектра функций, включая транзакции MySQL, мы использовали механизм InnoDB. Выполнив вышеприведенную команду для создания таблицы, вы увидите следующий результат:
Query OK, 0 rows affected (0.03 sec)
Выйдите из сервера MySQL:
Вы получите сообщение:
Таблица products готова. Вы можете использовать ее для хранения некоторых записей, включая изображения продуктов. Скоро мы заполним ее данными.
2: Создание PHP-скрипта для заполнения базы данных
На этом этапе мы создадим сценарий PHP, который будет подключаться к базе данных MySQL, созданной в первом разделе руководства. Сценарий подготовит три записи о товарах и вставит их в таблицу products.
Чтобы создать PHP-скрипт, откройте новый файл в текстовом редакторе:
sudo nano /var/www/html/config.php
Затем вставьте в него следующую информацию (замените PASSWORD паролем test_user, который вы создали в разделе 1):
$pdo = new PDO("mysql:host=" . DB_HOST . "; dbname https://i.imgur.com/VEIKbp0.png")
'product_name' => 'MANAGED KUBERNETES',
'product_name' => 'MySQL DATABASES',
$sql = "INSERT INTO products(product_name, price, product_image) VALUES (:product_name, :price, :product_image)";
foreach ($products as $product)
echo "Records inserted successfully";
Сохраните и закройте файл.
Этот файл нужен для определения переменных базы данных и подключения к ней. Файл также инициирует объект PDO и сохраняет его в переменной $pdo. Мы ссылаемся на файл config.php вверху.
Затем мы создали массив данных о товарах, которые нужно вставить в БД. Помимо product_name и price, которые заданы в виде строк и числовых значений соответственно, сценарий использует встроенную функцию PHP file_get_contents для чтения изображений из внешнего источника и передачи их в виде строк в столбец product_image.
После этого мы подготовили оператор SQL и использовали оператор PHP foreach для вставки каждого продукта в базу данных.
Запустите /var/www/html/insert_products.php в окне браузера, используя следующий URL-адрес (не забудьте заменить your-server-IP внешним IP-адресом сервера):
На экране вы увидите сообщение об успешном выполнении файла – следовательно, записи были вставлены в базу данных.
Records inserted successfully
Итак, мы успешно вставили три записи, содержащие изображения товаров, в таблицу. На следующем этапе мы напишем сценарий PHP для извлечения этих записей и отображения их в браузере.
3: Извлечение и визуализация данных из БД MySQL
Имея в базе данных информацию и изображения товаров, вы можете написать второй сценарий PHP, который будет запрашивать и отображать данные в таблице HTML в браузере.
Чтобы создать файл, введите:
sudo nano /var/www/html/display_products.php
Затем вставьте в файл следующее:
$sql = "SELECT * FROM products";