Защитите свой сайт от веб-скраппинга
Веб-скрапинг ( от английского scrapping – соскабливание, он же парсинг сайтов ) — это процесс извлечения данных, доступных в интернете с помощью автоматизированных запросов, созданных специализированным программным обеспечением. Поисковый робот просматривает информацию с целью индексирования или ранжирования сайта, в то время как при скрапинге данные копируются в другое место.

В рамках процесса скраппинга веб-страниц злоумышленник пытается извлечь данные с ресурса: парсинг email адресов с сайта или даже целых. Идеальным способом извлечения этих данных является отправка периодических HTTP-запросов на сервер, которые отправляют веб-страницу в программу. Затем злоумышленник анализирует полученный HTML-код и извлекает требуемые данные. Этот процесс повторяется для сотен или тысяч веб-страниц, содержащих требуемые данные.
Обновлено: 2023-01-23 18:49:27 КК Константин Кондрусин автор материала
С технической точки зрения процесс парсинга данных с сайта не может быть незаконным, поскольку злоумышленник просто извлекает информацию, доступную ему через браузер.
Поэтому, как вебмастер, вы должны быть оснащены так, чтобы не допустить кражу данных. Неконтролируемое копирование с помощью огромного количества запросов может привести к тому, что сервер и размещенные на нем ресурсы перестанут отвечать.
Парсинг страниц сайта может привести к потере конкурентного преимущества и дохода. В худшем случае копирование может привести к дублированию контента в другом месте, что повлечет за собой потерю доверия к первоначальному источнику. С технической точки зрения, копирование может привести к избыточной нагрузке на сервер, замедлению его работу и повышению расходов.
Рассмотрим несколько способов, с помощью которых можно противостоять потенциальным злоумышленникам. Но вы должны знать, что все, что видно на экране, может быть скопировано, и абсолютной защиты не существует.
Как запретить парсинг сайта с юридической точки зрения
Самый простой способ противостоять парсинга — запретить это юридически. Например, условия использования сайта Medium содержат следующую строку:
Обход роботом служб разрешен, если это сделано в соответствии с директивами нашего файла robots.txt, но скрапинг запрещен.
Можно даже подать в суд на потенциальных скраперов, если вы запретили это в условиях. Например, как LinkedIn.
Предотвращение атак влекущих за собой отказ в обслуживании (DoS)
Скраппиннг может нарушить работу вашего сервера. Поэтому необходимо избегать возникновения подобных ситуаций.
Можно идентифицировать IP-адреса злоумышленников и блокировать их запросы путем фильтрации через ваш брандмауэр. Хотя поставщики облачных услуг предоставляют доступ к инструментам, которые блокируют потенциальные атаки. Например, если вы пользуетесь Amazon Web Services , AWS Shield поможет защитить сервер от возможных атак.
Использование токенов подделки межсайтовых запросов (CSRF)
Используя токены CSRF в вашем приложении, вы предотвратите выполнение произвольных запросов на гостевые URL-адреса . Маркер CSRF может присутствовать как переменная сеанса или как скрытое поле формы.
Чтобы обойти маркер CSRF , нужно загрузить и проанализировать разметку, а также выполнить поиск нужного маркера. Этот процесс требует навыков программирования и использования профессиональных инструментов.
Использование .htaccess для предотвращения копирования
.htaccess — это файл конфигурации веб-сервера Apache , и его можно настроить так, чтобы предотвратить доступ скраперов к вашим данным. Первый шаг — определить парсеры, что может быть выполнено через Google Webmasters или Feedburner . После того как вы их идентифицируете, можно использовать большое количество методов защиты.
По умолчанию файл .htaccess не включен в Apache . Также мы предоставим аналоги для Nginx и IIS в рамках приводимых примеров. Подробную информацию о преобразовании правил перезаписи можно найти в документации Nginx .
Предотвращение парсинга картинок с сайта
Когда ваш контент подвергается парсингу для другого сайта , встроенные ссылки на изображения и другие файлы копируются непосредственно на сайт злоумышленника. Из-за этого он напрямую ссылается на ваш сайт. Подобный процесс отображения ресурса, размещенного на вашем сервере на другом веб-сайте, называется хотлинкинг ( hotlinking ).
Когда вы запрещаете хотлинкинг, изображение, отображаемое на другом сайте, не обслуживается вашим сервером. Таким образом, скопированный контент не сможет использовать ресурсы, размещенные на вашем сервере.
В Nginx хотлинкинг может быть предотвращен с помощью директивы location в соответствующем файле конфигурации ( nginx.conf ). В IIS необходимо установить URL Rewrite и отредактировать файл конфигурации web.config .
Черный или белый список конкретных IP-адресов
Если вы определили IP-адреса , которые используются для скраппинга, можете просто заблокировать их через файл .htaccess . Также можно выборочно разрешать запросы от конкретных IP-адресов , которые находятся в белом списке.
В Nginx можно использовать ngx_http_access_module , чтобы выборочно разрешать или отклонять запросы с IP-адреса. Аналогично, в IIS можно ограничить доступ к IP-адресам , добавив роль в Диспетчере серверов .
Запросы для регулирования нагрузки
В качестве альтернативы можно ограничить количество запросов с одного IP-адреса . Но это может быть неэффективно, если злоумышленник имеет доступ к нескольким IP-адресам . В случае аномальных запросов с IP-адреса можно использовать капчу.
Также можно заблокировать доступ к известным IP-адресам облачных хостингов и сервисов парсинга сайтов , чтобы убедиться, что злоумышленник не сможет использовать их для скраппинга.
Создайте «приманки»
« Приманка » — это ссылка на поддельный контент, невидимый для обычного пользователя, но присутствующий в HTML , который появляется, когда программа анализирует сайт. Перенаправляя скраперов на такие приманки, можно обнаружить их и заставить напрасно тратить ресурсы на страницы, которые не содержат данных.
Часто изменять структуру DOM
Большинство скраперов анализируют HTML-код , который извлекается с сервера. Чтобы им было труднее получить доступ к интересующим их данным, можно часто изменять структуру HTML . В результате для парсинга таких сложных сайтов злоумышленнику нужно будет снова и снова оценивать структуру вашего сайта, чтобы извлечь интересующие данные.
Предоставление API
Можно выборочно разрешать извлечение данных с сайта при условии принятия определенных правил. Один из способов реализовать это — создать API-интерфейсы на основе подписки для мониторинга и предоставления доступа к данным. Через интерфейсы API также можно контролировать и ограничивать их использование.
Донести на злоумышленника поисковым системам и интернет-провайдерам
Если все остальное не приносит положительного результата, можно сообщить поисковой системе о скраперах, чтобы они исключили из своей выдачи скопированный контент. А также интернет-провайдерам скраперов, чтобы убедиться, что они блокируют их запросы.
Так как же бороться с парсингом сайта
Любая защита от парсинга сайта может быть преодолена кем-то. Но ключевая идея заключается в том, чтобы оставаться осторожным и следить за трафиком.
Как защитить сайт от парсинга
В настоящее время сайты — один из главных компонентов успешного бизнеса. Они используются для рекламы, предоставления информации о продуктах и услугах, онлайн-продажи товаров. Однако с развитием технологий появляются и новые угрозы: например, парсинг и скрапинг, в процессе которых роботы копируют информацию с чужих веб-ресурсов. При парсинге извлекаются данные из открытых источников, однако затем они могут использоваться и для добросовестных целей (индексации), и для злонамеренных: таких, как кража контента. В связи с этим защита от парсинга является важной задачей для любого веб-мастера. О том, какие существуют методы защиты сайта от парсинга текстов и изображений, рассказываем в статье.
Что такое парсинг простыми словами
Под парсингом понимается сбор информации с веб-сайта посредством специальных программ (парсеров). Парсер читает код страницы и извлекает данные, соответствующие заданным в его настройках параметрам: например, текст, изображения, ссылки или любой другой контент, вплоть до структуры ресурса и элементов дизайна. Целью парсинга является автоматизация копирования и обработки больших объемов неструктурированных сведений. Программы не только собирают данные, но могут также систематизировать их по таблицам, создавая удобную базу, или сразу наполнять ими веб-страницы других ресурсов.
Информация, собранная в процессе парсинга, часто используется для анализа конкурентов, исследования рынка, проверки цен на продукцию. Однако чаще с сайтов парсят контент, который впоследствии выдают за свой. Это приводит к нарушению прав на интеллектуальную собственность, серьезным финансовым потерям (например, когда чужой магазин с вашими уникальными товарными описаниями переманивает клиентов) и ухудшению поисковой оптимизации. Защита от парсинга сайта — важный шаг для обеспечения безопасности вашего веб-ресурса и его эффективного продвижения в интернете.

Полностью защитить себя от копирования невозможно, поскольку все радикальные меры, которые стопроцентно будут действовать на ботов, также затронут и пользователей, и краулеры поисковиков, а без них любой сайт будет лишен смысла. Ниже мы рассмотрим несколько способов защиты, которые позволят вам уберечь текстовый и графический контент от примитивных инструментов парсинга.
Как защитить сайт от кражи текстов
Как мы уже сказали, полностью защититься от парсинга текстов нельзя, но стоит предпринять хотя бы минимальные меры по обеспечению их безопасности. Зачем это нужно? Текстовые материалы составляют основу поискового продвижения: по ним системы поиска определяют релевантность страниц, их пользу для посетителей. С помощью текстов люди понимают, что за ресурс перед ними, какие товары и услуги предлагает компания, насколько она компетентна в тех или иных вопросах. Как видите, речь идет не только о статьях, но и об описаниях в каталогах, информации в разделе «О нас», отзывах клиентов и т. п. Все это легко парсится с сайта, поскольку размещено в открытую. Если ваши уникальные тексты украдут и добавят на другой веб-ресурс, велика вероятность, что при его индексировании ваш сайт просядет в позициях из-за дублированного контента.
Устранять подобные проблемы гораздо дольше и сложнее, чем заранее озаботиться защитой от копирования. Мы опишем четыре технических решения, которые помогут обезопасить тексты хотя бы на базовом уровне.
Запрет на выделение текста
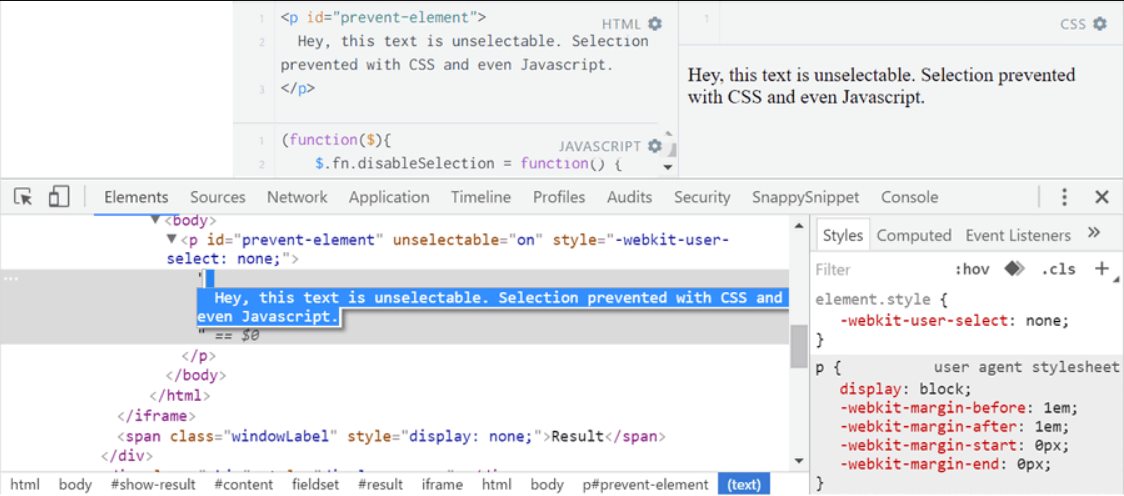
Чтобы скопировать определенный фрагмент текста со страницы, его нужно выделить — запретите это действие, и тогда неопытные копипастеры не смогут спарсить данные вручную. Установить запрет можно с помощью стилей CSS. Например, можно добавить в код страницы следующие строки:
body <
-webkit-user-select: none;
-moz-user-select: none;
-ms-user-select: none; user-select: none;
>Вы можете внедрить подобный CSS-код самостоятельно или обратиться к специалистам, ответственным за работу вашего сайта. Этот способ очень прост в реализации, но обладает малой эффективностью, поскольку автоматические программы-парсеры сканируют HTML-код веб-страниц, а не их «пользовательскую» версию. Если данные извлекаются напрямую из кода, запрет выделения работать не будет. Еще один минус в том, что об этом знают и люди, систематически ворующие контент. Они также могут легко залезть в код и скопировать текст оттуда.
В общем, как защита от парсинга это сомнительное решение, но в некоторых случаях действительно поможет отвадить плагиаторов. Главное, понимать, что запрет будет распространяться и на обычных пользователей. Внедряйте этот способ, только если он не скажется на лояльности вашей аудитории.
Запрет на копирование в буфер обмена
Другой способ защиты от кражи текстов — это выключить функцию добавления в буфер обмена. Так называется временное хранилище, куда помещается информация при командах «Вырезать» и «Копировать». Если вы запретите использование этого буфера, ручное копирование текстовых материалов с веб-страницы будет невозможно. То есть человек сможет выделить слова, дать нужную команду, но самого действия не произойдет: буфер обмена останется чист, и извлекать оттуда будет нечего.
Для установки такого запрета потребуется использовать JavaScript. Внедрите в код страницы следующий скрипт:
document.addEventListener('copy', function(e) <
e.preventDefault();
>);Если вы не разбираетесь в языке JS, лучше доверить работу разработчикам/администраторам вашего сайта. Лишние скрипты могут нарушить исполнение основного кода, поэтому рисковать понапрасну не стоит. Тем более, что в качестве противодействия парсингу этот метод не эффективнее, чем предыдущий. От ручного копирования неумелыми руками поможет, но программного парсинга избежать не получится.
Добавление ссылки при копировании текста
Данный метод не защитит контент от кражи, но поможет усложнить жизнь копипастерам и, возможно, даже улучшить SEO вашего сайта. Его суть заключается в том, что вы не запрещаете выделять и копировать слова, но привязываете к скопированному фрагменту ссылку, ведущую на вашу страницу. То есть в буфер обмена помещается дополнительный текст с указанием оригинального источника, и когда человек вставляет его куда-либо, туда же автоматически вставляется ссылка — обычно посреди или после выделенного текста.
Реализуется такая защита через JavaScript-код. Например, можно использовать такую конструкцию:
document.addEventListener('copy', function(e) <
var selectedText = window.getSelection().toString();
var textWithLink = selectedText + ' (Источник: example.com)';
e.clipboardData.setData('text/plain', textWithLink);
e.preventDefault();
>);Где «(Источник: example.com)» — это текст и ссылка, которые вы хотите добавить в буфер обмена копирующего. В результате плагиатору придется либо вычищать каждый скопированный текст, либо оставлять ссылки и тем самым увеличивать ссылочную массу вашего ресурса, либо найти для копипаста другую жертву. Это также действенно против парсинга примитивными ботами, которые заполняют украденным контентом другие площадки, где качество информации никто не проверяет.
Использование скрипта автозамены символов
Еще один способ защиты от ручного парсинга текстов состоит в подключении специального JS-скрипта, который автоматически меняет символы в скопированном тексте, чтобы на выходе получалась нечитабельная бессмыслица. Здесь потребуются чуть более глубокие знания в программировании, поэтому рекомендуем использовать прием только при их наличии. Вот пример кода, который можно применить для автозамены знаков:
function replaceCharacters(event) <
event.preventDefault();
var selection = window.getSelection().toString();
var replacedText = selection.replace(/a/g, '@').replace(/e/g, '3').replace(/i/g, '1').replace(/o/g, '0');
event.clipboardData.setData('text/plain', replacedText);
>
document.addEventListener('copy', replaceCharacters);Такой скрипт будет заменять букву «а» на «@», «е» — на тройку, «i» — на единицу, и «о» — на ноль. Копипастеру придется повозиться, чтобы все исправить, поэтому он с большей вероятностью обратиться к другому источнику и оставит ваш сайт. А если парсить будет бот, который отправляет данные на автозаполняемые ресурсы, уникальность вашего контента также останется в безопасности.
Как защитить сайт от копирования изображений
Графический контент также представляет большой интерес для парсеров и любителей плагиата. К сожалению, «картинки в интернете» очень часто не воспринимаются людьми, как объекты авторского права, их постоянно копируют и распространяют по разным площадкам, не упоминая источники. Многие даже не понимают, что тем самым нарушают закон. Однако гоняться за каждым таким копипастером и грозить судом всем подряд неэффективно и слишком затратно. Лучше сразу обеспечить защиту от парсинга изображений: сделать их копирование проблематичным или принудительно добавлять информацию об авторстве. Это поможет защитить иллюстрации, фотографии товаров и другую оригинальную графику, присутствующую на вашем сайте.
Водяные знаки
Одним из наиболее распространенных и эффективных методов защиты изображений являются водяные знаки или вотермарки. Это текст или логотип, который накладывается поверх фотографии с целью защитить ее авторство. Обычно вотермарки делают полупрозрачными, чтобы они не сильно отвлекали пользователя от самого контента, но при этом были заметны и легко распознавались. В идеале такой знак нужно размещать на видном месте, но без нарушения основной композиции и так, чтобы его нельзя было обрезать или закрасить.
В данном случае, каким бы образом изображение не было спарсено (вручную или автоматически), убрать упоминание автора будет сложно. То есть от самого парсинга вы контент не убережете, но украсть у вас авторство уже не получится: при необходимости вы сможете легко доказать, что изображение было скопировано, и ваш сайт является первоисточником.
Добавление вотермарок — несложный процесс, но нужно уметь пользоваться фоторедакторами вроде Photoshop. Если проект работает на CMS, то можно установить специальные плагины, которые будут автоматически создавать водяные знаки на всех ваших картинках.
Отключение функции сохранения картинок
Этот метод уже технический и защищает от парсинга в том смысле, что делает копирование и скачивание картинок привычными способами невозможным. Достичь такого результата можно с помощью скриптa JavaScript, который запрещает вызов контекстного меню:
document.addEventListener('contextmenu', function(e) <
e.preventDefault();
>);Благодаря этому коду, когда человек будет кликать правой кнопкой мыши по странице или изображению, он не сможет вызвать меню с командами. Это исключит и обычное действие «Скопировать» (именно через ПКМ, но не сочетание клавиш), и «Сохранить изображение как…». Отключение контекстного меню — вполне рабочая защита от плагиаторов, хотя закрыть сайт от парсеров это не поможет. А если человек умеет выключать исполнение скриптов в браузере, то и ручной скрапинг будет возможен. Вопрос только в том, захочет ли потенциальный воришка возиться с вашим сайтом или предпочтет менее защищенный ресурс.

Фиксирование авторства через метаданные
Фотографии, сделанные при помощи современного цифрового оборудования, обладают дополнительной информацией, которая «вшивается» в них в момент съемки. Например, снимки в вашем смартфоне могут рассказать о том, когда, где, на какую камеру, с каким разрешением и настройками объектива они были сняты. То же самое и с любыми другими цифровыми изображениями. Такие метаданные могут помочь вам с защитой от кражи авторства: добавьте в них информацию об авторе с помощью компьютерной программы, и она будет копироваться так же, как и остальные данные, вместе с картинкой. Это не спасет от парсинга, но по крайней мере позволит доказать, что именно ваш сайт был первоисточником. Полезная возможность при разбирательствах с копипастерами и хороший аргумент для жалобы на плагиат в поисковые системы.
Дополнительные методы защиты
Кроме вышеперечисленных, существуют и другие способы, которые используются для защиты сайта от парсинга и кражи контента. К примеру, вы можете:
- Внедрить капчу, т. е. проверять, является ли посетитель человеком или роботом. Для этого можно подключить специальный сервис (например, reCAPTCHA) или написать тест самостоятельно (понадобятся навыки программирования). Делайте проверку всех пользователей или только тех, что ведут себя подозрительно: нажимают в одну и ту же точку на кнопке, посылают слишком много запросов или чересчур быстро для человека и пр.
- Блокировать доступ к сайту для определенных IP-адресов. Это хорошее противодействие парсерам, но нужно быть уверенным, что с конкретного адреса приходят лишь боты. Иначе есть риск заблокировать реального посетителя.
- Брендировать контент, делать его более персонализированным, чаще упоминать название компании или сайта. Это позволит сделать информацию не подлежащей копированию.
- Попросить людей не копировать данные, напомнить об авторском праве и предупредить о возможных последствиях плагиата.
- Подключить сторонние антипарсинговые сервисы или заказать соответствующую услугу у своего хостинг-провайдера, если он предоставляет такую возможность.
Заключение
Защищать сайт от парсинга необходимо, чтобы усложнить кражу интеллектуальной собственности и сохранить ценность и уникальность контента. В статье мы рассмотрели стандартные методы, которые помогут уберечь графические и текстовые материалы от недобросовестного копирования.
Как защититься от парсинга и не угробить SEO
Как обезопасить сайт от кражи текстов, что делать, если контент всё-таки украли, и как вернуть просевшие позиции. Объясняет ARTISAN TEAM.
Поделиться
Поделиться

Контент крадут у всех. Это закон интернета. Тот, кто думает иначе и уверен в неприкосновенности содержимого своего сайта — текстов, оригинальных картинок, кода и прочего, — либо ошибается, либо сайт ещё молодой и пока (!) не интересует копипастеров. Данные всегда парсили и будут парсить. Защититься от этого на 100% невозможно. Лучшее противодействие воровству контента — осведомлённость. Вы должны знать, во-первых, что и как парсят. Во-вторых, своевременно замечать, когда украденные данные начинают вредить сайту, прежде всего — когда проседают позиции в поиске. В-третьих, важно научиться играть на опережение и защищать свои данные. И, наконец, когда ваш контент украден, нужно уметь грамотно решать эту проблему. При всех сложностях противодействовать копипастерам — вполне реально. Теперь обо всём этом по порядку.
Что такое парсинг
Парсинг или скрапинг — это сбор данных с чужих сайтов. Не вдаваясь в технические нюансы, суть этого процесса можно описать так: специальные боты посещают страницы целевого ресурса, выгружают HTML-код, разбирают его на отдельные составляющие, вычленяют нужные данные и сохраняют в своей базе. Зачастую боты обходят сайты на регулярной основе, отслеживая изменение цен, расширение товарного ассортимента или публикацию нового контента, который можно украсть. Поисковые роботы Google и Яндекса — это тоже своего рода парсеры. Принцип их работы аналогичен: периодически совершают обход сайта, собирают информацию и индексируют новые документы. Этим объясняется главная сложность противодействия парсингу: защищаясь от ботов-шпионов, легко заблокировать содержимое сайта для краулеров Google и Яндекса. А это — прощай, SEO и трафик из поиска, за счёт которого живут все нормальные сайты. Со стороны сервера запросы пользователей и роботов выглядят одинаково. Из этого вытекает, что если живые люди могут получить доступ к сайту, то его содержимое доступно и ботам. Соответственно, большинство автоматизированных средств против парсинга в той или иной мере работает и против пользователей. На практике это выливается в то, что антипарсинговые решения существенно ухудшают опыт пользования сайтом и просаживают поведенческие факторы, что не лучшим образом сказывается на SEO.
Не ботами едиными
Говоря о парсинге и краже данных, не следует забывать, что, помимо использования скриптов, контент не менее успешно копипастят руками. Как правило, это касается копирования текстов и фото. Формально копипаст не подпадает под определение парсинга, но последствия для SEO от такого заимствования аналогичны.
Что парсят чаще всего
Текстовый контент
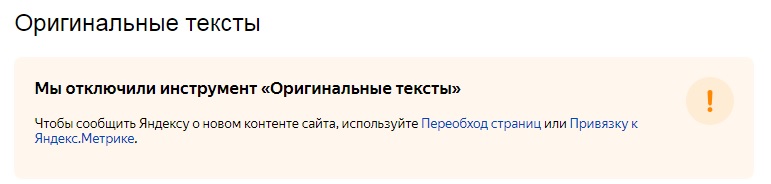
Это то, что интересует большую часть злоумышленников — тексты были и остаются основой поискового продвижения. Формально, даже если вашу статью украли, Google и Яндекс умеют определять сайт-первоисточник и отдавать ему преимущество в ранжировании. Но так бывает далеко не всегда. Например, если трастовые ресурсы крадут контент у молодых сайтов, последние могут остаться в пролёте. Статьи иногда перехватывают и публикуют на сторонних ресурсах до того, как они попадают в индекс. Такой перехват зачастую реализуют при помощи специальных скриптов. При подобном сценарии сайт, который украл текст, и вовсе выглядит для поисковиков, как первоисточник. Доказать своё право на контент в этом случае — практически нереально. До недавнего времени ощущение безопасности веб-мастерам обеспечивал инструмент «Оригинальные тексты» в панели Яндекс.Вебмастера. Предполагалось, что если загружать в него статьи перед публикацией, в случае кражи поисковик будет на вашей стороне. Но с недавнего времени Яндекс отключил и этот инструмент, предложив использовать «Переобход страниц» или «Обход по счётчикам Метрики». Эффективность этих механизмов по-прежнему вызывает много вопросов.
Метатеги и заголовки
Грамотная оптимизация
Семантика
Когда страницы сайта оказываются в топе, конкурентов начинает интересовать, как именно они туда попали. Их задача: узнать, под какие ключи оптимизированы статьи, какова их плотность, характер вхождения — всё это также легко узнать. При помощи нужного софта это делается буквально в несколько кликов, причём одинаково просто спарсить как ключи для статьи, так и семантическое ядро всего сайта.
Цены и товары
Это отдельная ecommerce-уловка, с помощью которой магазины конкурируют друг с другом. Как правило, такой скрапинг осуществляют на постоянной основе, отслеживая обновления каталога и цен.
Дизайн или отдельные элементы кода
Спарсить могут весь сайт или его конкретные элементы, например, какую-то оригинальную функцию. Обычно поисковики жёстко пресекают такие финты, и у недоброжелателя нет шансов обойти вас в выдаче с клонированным ресурсом.
Кто и зачем парсит сайты
- Наполнение дорвеев.
- Генерация контента под глобальные PBN-сети. Что такое PBN — читайте здесь.
- Парсинг текстов для создания Web 2.0.
- Скрапинг контента для сайтов, на 100% продвигающихся за счёт генерации трафика. В топ такие ресурсы вывести сложно, но они могут вполне нормально ранжироваться и иметь позиции в выдаче. По крайней мере, такое часто встречается в русскоязычном поиске Google.
- Парсинг описаний для товаров. Может, для кого-то это станет откровением, но карточки с неуникальными описаниями очень хорошо ранжируются поисковиками. Вполне вероятен сценарий, что вас обойдут в выдаче, используя ваши же уникальные тексты для товаров.
Как видно, переживать за сохранность своих данных нужно всем: даже если вы продвигаетесь в нише без конкурентов (чего не бывает) или они белые и пушистые (тоже нонсенс). Примерно 2/3 всего парсинга в сети — это полностью автоматизированный процесс. То есть вас не будут искать и копипастить данные вручную — всё это сделает скрипт, как только ваши страницы попадут в топ или станут более или менее заметными.
В зоне риска прежде всего оказываются тексты — они представляют наибольший интерес для парсеров и на их защите следует сосредотачиваться в первую очередь.
Как защитить сайт от кражи текстов
Итак, кража статей — это данность. И если не сейчас, то в будущем с этим обязательно столкнётся каждый веб-мастер. Контент нужно защищать, причём не ждать, пока ваш ресурс станет популярным и с него начнут активно копипастить. Молодые сайты находятся в особенно уязвимой ситуации — когда у них заимствуют контент более трастовые площадки, поисковые системы могут приписать право первоисточника им.
Теперь — о способах защиты: эффективных и не очень.
Что работает, но слабо
Запрет на выделение текста
Вы можете создать отдельный CSS-стиль, запрещающий выделение текста. Речь идёт о небольшом микрокоде, с которым легко разобраться самому или поручить эту задачу программисту.
Такое решение нельзя назвать полноценной защитой, поскольку текст можно извлечь из HTML-кода. Это лишь немного усложнит жизнь копипастеру, и то не всегда. Не забываем, что руками копируют очень редко, а этот способ не создаёт никаких преград для парсинга. Даже если кто-то не слишком опытный захочет забрать ваш текст, он погуглит, как это сделать через код (спойлер: совсем несложно).
Запрет на копирование в буфер обмена
Механизм этой защиты несколько иной. На сайт добавляют небольшой скрипт, который разрешает копирование текста, но не позволяет вставить его в буфер обмена. В остальном эффективность этой защиты такая же низкая, как и в первом случае. Она не защищает от парсинга и может обезопасить только от неумелых копипастеров, которым лень сходить в поисковик и узнать, как извлечь текст через код.
Подключение reCAPTCHA
Сервис reCAPTCHA и всевозможные аналоги дают крайне низкую эффективность при защите от парсинга и спама. В профессиональных кругах их упоминание успело стать моветоном. Решений по обходу капч очень много. Если не вдаваться в детали, работают они следующим образом: когда защита запрашивает проверку, капча автоматически перенаправляется на сторонний сервис, где её распознаёт реальный человек и отдаёт обратно на сервер.
Услуги по обходу капч стоят в прямом смысле копейки (можете сами посмотреть тарифы на 2Captcha или ruCAPTCHA). Поэтому те, кто пишет парсеры, даже не рассматривают капчи как какую-то проблему. А вот для реальных пользователей — это зло. Закрывая контент капчами, будьте готовы к возможным лагам с индексацией и гарантированной просадке поведенческих. Всё это нанесёт неизбежный удар по SEO.
Чтобы смягчить негативный эффект от капч, можно использовать скоринг и задействовать чёрные списки. Это несколько улучшит пользовательский опыт, но не решит главную проблему — при желании на вашем сайте спарсят всё, что нужно.

Использование DMCA protected
Речь идёт о платном сервисе мониторинга контента. Подключившись к вашему сайту, он периодически совершает обход и проверяет страницы на предмет появления копий. Если данные кто-то украл, на почту придёт уведомление. За дополнительную плату представители сайта готовы писать жалобы (abuse), чтобы Google удалил скопированный текст из выдачи. Вплоть до судебных разбирательств. Сайт, находящийся под защитой этого сервиса, получает сертификат и специальную плашку, которая в теории должна отпугивать копипастеров. У нас DMCA protected вспоминают нечасто, но на западе он пользуется довольно большой популярностью.
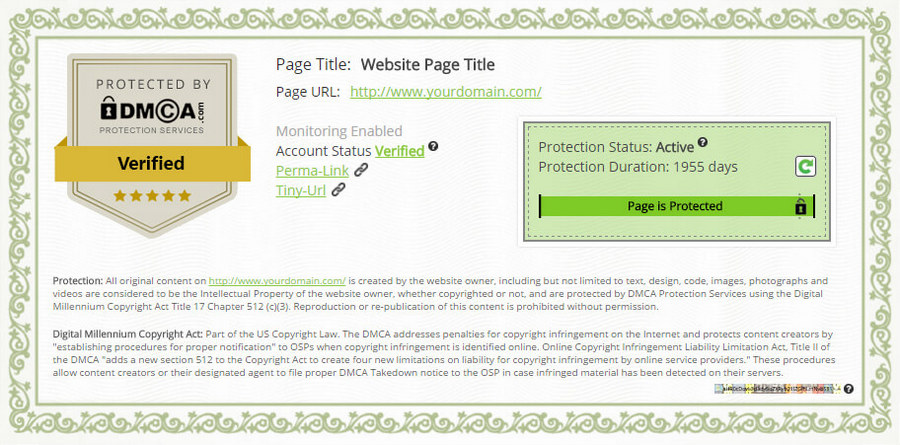
На практике эффективность такой защиты вызывает много вопросов. Начнём с того, что сервис DMCA protected — это не официальный представитель органов американской юстиции. Звучное название сайта dmca.com многих вводит в заблуждение, так как ассоциируется с законом DMCA, контролирующим авторское право в интернете. Но сервис официально никак не связан с органами американской юстиции. А думать, что плашка в футере будет отпугивать воров — наивно. Если более или менее опытный злоумышленник захочет по-тихому увести контент или другие данные, он просто удалит на сайте фрагмент защитного кода и возьмёт то, что нужно.
Что работает лучше
Блокировка ботов по IP
Это один из способов противодействия парсингу, когда данные крадут постоянно и, как правило, в большом объёме. Речь идёт уже не только о текстах, но и других сведениях, представляющих стратегический интерес для конкурентов. Блокировка IP-адресов ботов, которые скрапят ваши страницы — один из самых распространённых механизмов защиты. Но здесь важно понимать: если вам дорого трафик из поиска, вы вступаете на тонкий лёд. Угробить SEO в этом случае — проще простого.
Хорошо написанный парсер весьма убедительно имитирует активность живого пользователя. Благодаря рандомизации заголовков, постоянной смене прокси (поддельных IP-адресов) и другим техническим уловкам отличить бота-шпиона от реального пользователя очень трудно. Конечно, сервисы для защиты от парсинга тоже становятся более прокачанными, но их основной механизм остаётся неизменным — это блокировка вредоносных запросов по IP. Продолжается своего рода вечная игра в кошки-мышки между ботами и антипарсерами.
Защищаясь от парсинга, сайт может оказаться заблокированным для краулеров Google и Яндекса, которые являются такими же ботами, но со своими «белыми» задачами. К слову, обычно боты-шпионы представляются на сервере именно краулерами поисковиков. Последствия такого провала очевидны: сайт частично или полностью вылетит из индекса. Прощай, органический трафик. Об этом важно помнить, самостоятельно закрывая сайт от ботов, устанавливая скрипты от парсинга или заказывая самописную защиту.
Добавление ссылки при копировании текста
Этот весьма простой способ защиты может принести немало пользы. На сайт внедряют небольшой скрипт, который автоматом привязывает к скопированному тексту ссылку на источник. Обычно она располагается внизу. Как ни странно, но такие ссылки убирают не всегда: иногда сознательно, иногда по недосмотру.
Стандартный скрипт лучше допилить и сделать так, чтобы ссылка добавлялась внутри текста. В этом случае вероятность, что её не заметят, увеличивается в несколько раз. Это способ хорош как для защиты от ручного копирования, так и от скрапинга. Он хоть и не препятствует фактической краже, но позволяет узнать, кто скопипастил текст без прогонки статей через антиплагиатчик. Для этого достаточно посмотреть обратные ссылки на свой сайт.
Использование скрипта автозамены символов
Весьма эффективный способ противостоять краже текстов. Его суть состоит в интеграции специального java-скрипта, который при копировании заменяет часть кириллических символов на латиницу — текст становится нечитаемым. Чтобы пофиксить это на уровне кода, нужны специальные навыки, и далеко не каждый копипастер будет возиться. Этот лайфхак защищает главным образом от ручного копирования. Ботам же всё равно: обычно они парсят для автонаполняемых сайтов, где тексты никто не проверяет.
Брендирование контента
Это своего рода аналоговый способ защиты текстов. Его суть проста: статьи нужно делать более персонализированными, писать от лица бренда и чаще упоминать его название, причём делать это так, чтобы бегло подчистить текст было как можно сложнее. Такой контент отсеет часть копипастеров: конечно, наиболее переборчивых и тех, кто ворует вручную. Если вас парсят боты, им это не помещает. Но и здесь у вас будет преимущество: можно узнать о перепубликации контента при помощи Google Alerts, настроив оповещение на бренд.
Что делать при краже контента
Обращение к копипастеру напрямую
Первым делом свяжитесь с админами площадки и попросите удалить контент. Запугивание судами в рунете воспринимают несерьёзно. Поэтому просто напишите, что у вас есть очевидные доказательства принадлежности текста вам, и когда вы подадите жалобу в DMCA — она будет рассмотрена в вашу пользу. Часто это работает. Но лишь в тех случаях, когда вас обокрал худо-бедно белый или серый сайт. Если вас спарсили дорвеи, порносайты или другие треш-ресурсы из 100% чёрной ниши, надеяться, что отреагируют — не имеет особого смысла.
Уведомление в службу поддержки поисковиков
Второй шаг — написать в саппорт Яндекс.Вебмастера и Google Search Console. Это особенно актуально, если у вас спарсили весь сайт или копипастер обошёл вас в выдаче с вашим же контентом. Сразу скажем, что на быстрый и результативный отклик рассчитывать не приходится. Особенно тяжёлой на подъём является служба поддержки Google. Но связываться с саппортом в таких случаях нужно обязательно.
Жалоба в DMCA
На международном уровне наиболее действенный механизм правовой защиты контента — закон DMCA (Digital Millennium Copyright Act). Он работает в США и распространяется на все американские компании, в том числе поисковики Google, Bing, Ask. По понятным причинам всех в первую очередь интересует Google. Если вы докажете факт нарушения авторских прав, страницы копипастера удалят из выдачи. Подать жалобу на украденный контент могут в том числе нерезиденты США.
Как это работает на практике? Владелец сайта подаёт заявку о нарушении авторских прав. В отличие от техподдержки, Google реагирует довольно быстро: присылает ответ и обычно сразу скрывает из выдачи страницы с украденным контентом. Администраторам сайта, на который написана жалоба, высылается соответствующее уведомление.
Это идеальный сценарий. Но им обычно всё не заканчивается. За владельцем сайта, которого обвиняют в плагиате, остаётся право подать встречное уведомление. И этой возможностью, как правило, никто не пренебрегает. Тогда доступ к удалённым страницам восстанавливается и начинается долгая волокита. В теории она предполагает судебные тяжбы, но на практике чаще всего заканчивается ничем.
Жалоба в DMCA отлично работает, когда ваши материалы спарсили дорвейщики. Такие страницы Google обычно блокирует без колебаний. Больше шансов, если контент украл порносайт, автонаполняемый статейник или другой сомнительный ресурс. В остальных случаях вашу жалобу будут парировать встречным уведомлением, прекрасно понимая, что реальное судебное разбирательство, скорее всего, не грозит.
Жалоба хостерам
Это ещё один весьма действенный способ решить проблему, связанную с кражей данных. Конечно, за спорную статью вряд ли кто-то накажет копипастера, но если речь идёт о систематическом копировании контента, хостер, дорожащий своей репутацией, может забанить такой домен. Другое дело, что большинство откровенно мутных сайтов, типа дорвеев или автонаполняемых PBN-сетей, специально разворачивают на «абузоустойчивых» хостингах. Достучаться с жалобой до провайдера в этом случае — нереально.
Если речь идёт о крупном воровстве данных, можно проявить настойчивость и пойти ещё дальше, написав жалобу в ICANN. Это всемирная корпорация, которая координирует систему присвоения доменных имён. Формально она не управляет содержимым в сети, но через неё можно подать жалобу на домен, если сайт занимается противозаконной деятельностью или злоупотреблениями.
Добиться блокировки домена этим способом реально, если вам досаждают откровенно «чёрные» сайты, которые уже многократно приводились в пример. Но и в этом случае подача жалобы предполагает множество нюансов, разобраться с которыми не так-то просто. Как вариант, можно воспользоваться услугами специальных компаний-посредников, специализирующихся на написании жалоб в ICANN.
Тексты не удаляют, а позиции просели. Что делать?
Решение контентных споров может затянуться надолго и с большой долей вероятности закончиться ничем. Это не лучший сценарий для тех, кто из-за копипастеров потерял позиции в выдаче и несёт убытки. В таких случаях куда эффективнее — попробовать вернуть утраченные позиции.
- Актуализируйте статью: допишите 1–2 тысячи знаков, обновите дату публикации и отправьте документ на переиндексацию.
- Сделайте посев ссылками в соцсетях и поставьте 1–2 беклинка на сторонних (тематически близких) сайтах. Актуализируя статью, следите за тем, чтобы новый текст не размывал релевантности старой семантики.
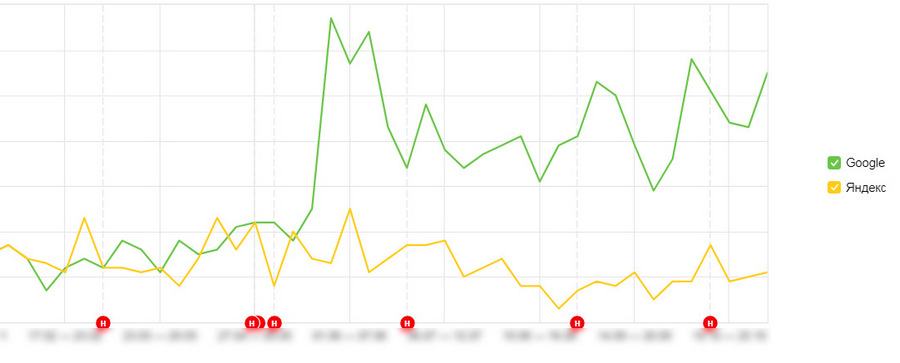
Это должно дать результат. Особенно хорошо такой финт работает в Google. Некоторые веб-мастеры даже стараются держать под рукой запасной контент, чтобы максимально быстро реагировать на просевшие позиции в подобных ситуациях. Это особенно актуально в конкурентных нишах, где кража контента является очень распространённой практикой. Естественно, всё это предполагает постоянный контроль позиций и автомониторинг страниц сайта на плагиат.
Источник фото на тизере: скриншот The Gentlemen, Miramax Films
Мнение редакции может не совпадать с мнением автора. Ваши статьи присылайте нам на 42@cossa.ru. А наши требования к ним — вот тут.
Парсим сайты с защитой от ботов
В этой статье мы разберемся, как работает типичная защита от роботов, рассмотрим подходы к автоматическому парсингу сайтов с такой защитой, и разработаем свое решение для её обхода. В конце статьи будет ссылка на гитхаб.
Речь не идет о каком-либо виде «взлома» или о создании повышенной нагрузки на сайт. Мы будем автоматизировать то, что и так можно сделать вручную. Если говорить конкретно о нас, то мы собираем характеристики товаров.

Думаю, иногда при серфинге вы встречали такие страницы-заглушки. Их цель — удостовериться, что посмотреть на страницу хочет кто-то относительно живой, и пропустить его, и в то же время заблокировать различного рода роботов и парсеров. По сути, перед нами капча, но автоматическая, не требующая взаимодействия с пользователем.
Как работает защита от автоматических запросов?
Вряд ли кто-то знает наверняка в деталях, кроме разработчиков конкретного решения. Но мы можем сделать некоторые обоснованные предположения. По крайней мере, можем понять, какие принципы для этого могут быть использованы.
Давайте попробуем классифицировать способы, которые используют сайты, чтобы отфильтровать автоматические запросы.
- Самописные решения.
- Готовые модули для веб-cервера. По запросу “nginx bots protection module” находится много разных решений, и платных, и бесплатных, и открытых.
- Сторонний сервис, специализирующийся на фильтрации автоматического трафика.
Для начала, давайте разберемся, что о нас известно серверу на той стороне, вне зависимости от того, каким из способов реализована проверка.
IP-адрес. По нему можно определить страну, город, провайдера. В большинстве случаев, по нему нельзя определить конкретное устройство или конкретного абонента, потому что абоненты находятся за NAT.
Заголовки HTTP. По ним можно определить браузер, используемый язык интерфейса, и некоторые другие параметры. В них же передаются Cookies, с их помощью которых можно сопоставить запросы из одного браузера. Так же с их помощью можно определить, выполняется ли на клиенте код на JavaScript.
Особенности реализации TCP, TLS и HTTP/2. Суть в том, что HTTP — это прикладной, самый последний уровень модели OSI, а на уровнях ниже используются протоколы, реализация которых в разных программах может иметь особенности.
Последнее утверждение получилось весьма неконкретным, поэтому давайте установим какой-нибудь анализатор трафика и посмотрим, что происходит на самом деле.
Я не являюсь сетевым инженером, поэтому могу допускать ошибки в рассуждениях о сетевых протоколах и трактовке полученных данных, но считаю тему важной и поэтому достойной попытки в ней разобраться.
Я установил Microsoft Network Monitor и посмотрел, как выглядят запросы из разных инструментов в виде кадров канального уровня. Примерно так:
Кадр из Microsoft Network Monitor
Frame: Number = 306, Captured Frame Length = 277, MediaType = WiFi - WiFi: [Unencrypted Data] .T. (I) - MetaData: Version: 2 (0x2) Length: 32 (0x20) - OpMode: Extensible Station Mode StationMode: (. 0) Not Station Mode APMode: (. 0.) Not AP Mode ExtensibleStationMode: (. 1..) Extensible Station Mode Unused: (.0000000000000000000000000000. ) MonitorMode: (0. ) Not Monitor Mode Flags: 4294967295 (0xFFFFFFFF) RemData: Outbound TimeStamp: 01/14/2023, 14:02:35.627425 UTC - FrameControl: Version 0,Data, Data, .T. (0x108) Version: (. 00) 0 Type: (. 10..) Data SubType: (. 0000. ) Data DS: (. 01. ) STA to DS via AP MoreFrag: (. 0. ) No Retry: (. 0. ) No PowerMgt: (. 0. ) Active Mode MoreData: (..0. ) No ProtectedFrame: (.0. ) No Order: (0. ) Unordered Duration: 32768 (0x8000) BSSID: 2C9D1E DC642C SA: E470B8 CF3A50 DA: 2C9D1E DC641F - SequenceControl: Sequence Number = 0 FragmentNumber: (. 0000) 0 SequenceNumber: (000000000000. ) 0 - LLC: Unnumbered(U) Frame, Command Frame, SSAP = SNAP(Sub-Network Access Protocol), DSAP = SNAP(Sub-Network Access Protocol) - DSAP: SNAP(Sub-Network Access Protocol), Individual DSAP Address: (1010101.) SNAP(Sub-Network Access Protocol) IG: (. 0) Individual Address - SSAP: SNAP(Sub-Network Access Protocol), Command Address: (1010101.) SNAP(Sub-Network Access Protocol) CR: (. 0) Command Frame - Unnumbered: UI - Unnumbered Information MMM: (000. ) 0 PF: (. 0. ) Poll Bit - No Response Solicited MM: (. 00..) Type: (. 11) Unnumbered(U) Frame - Snap: EtherType = Internet IP (IPv4), OrgCode = XEROX CORPORATION OrganizationCode: XEROX CORPORATION, 0(0x0000) EtherType: Internet IP (IPv4), 2048(0x0800) - Ipv4: Src = 192.168.100.24, Dest = 49.12.20.235, Next Protocol = TCP, Packet Total IP Length = 213 - Versions: IPv4, Internet Protocol; Header Length = 20 Version: (0100. ) IPv4, Internet Protocol HeaderLength: (. 0101) 20 bytes (0x5) - DifferentiatedServicesField: DSCP: 0, ECN: 0 DSCP: (000000..) Differentiated services codepoint 0 ECT: (. 0.) ECN-Capable Transport not set CE: (. 0) ECN-CE not set TotalLength: 213 (0xD5) Identification: 3626 (0xE2A) - FragmentFlags: 16384 (0x4000) Reserved: (0. ) DF: (.1. ) Do not fragment MF: (..0. ) This is the last fragment Offset: (. 0000000000000) 0 TimeToLive: 128 (0x80) NextProtocol: TCP, 6(0x6) Checksum: 33089 (0x8141) SourceAddress: 192.168.100.24 DestinationAddress: 49.12.20.235 - Tcp: Flags=. AP. SrcPort=51677, DstPort=HTTPS(443), PayloadLen=173, Seq=3595707432 - 3595707605, Ack=850844191, Win=512 (scale factor 0x8) = 131072 SrcPort: 51677 DstPort: HTTPS(443) SequenceNumber: 3595707432 (0xD6522428) AcknowledgementNumber: 850844191 (0x32B6DA1F) - DataOffset: 80 (0x50) DataOffset: (0101. ) 20 bytes Reserved: (. 000.) NS: (. 0) Nonce Sum not significant - Flags: . AP. CWR: (0. ) CWR not significant ECE: (.0. ) ECN-Echo not significant Urgent: (..0. ) Not Urgent Data Ack: (. 1. ) Acknowledgement field significant Push: (. 1. ) Push Function Reset: (. 0..) No Reset Syn: (. 0.) Not Synchronize sequence numbers Fin: (. 0) Not End of data Window: 512 (scale factor 0x8) = 131072 Checksum: 0xF528, Disregarded UrgentPointer: 0 (0x0) TCPPayload: SourcePort = 51677, DestinationPort = 443 TLSSSLData: Transport Layer Security (TLS) Payload Data - TLS: TLS Rec Layer-1 HandShake: Encrypted Handshake Message. - TlsRecordLayer: TLS Rec Layer-1 HandShake: ContentType: HandShake: - Version: TLS 1.2 Major: 3 (0x3) Minor: 3 (0x3) Length: 168 (0xA8) - SSLHandshake: SSL HandShake EncryptedHandshakeMessage: Binary Large Object (168 Bytes)
Канальный уровень нас не интересует, данные о нем до удаленного сервера не дойдут. Нас интересуют инкапсулированные в кадре канального уровня пакеты сетевого уровеня и уровни выше.
Первое интересное наблюдение: IP-пакет содержит параметр TTL. Начальное значение этого параметра для TCP протокола отличается в разных операционных системах. Мне удалось найти такие значения для современных версий: