5 Запрос (Request).
Сообщение запроса от клиента к серверу содержит в первой строке: метод, который нужно применить к ресурсу, идентификатор ресурса и используемую версию протокола.
Request = Request-Line ; Раздел 5.1 *( general-header ; Раздел 4.5 | request-header ; Раздел 5.3 | entity-header ) ; Раздел 7.1 CRLF [ message-body ] ; Раздел 7.2
5.1 Строка запроса (Request-Line).
Строка запроса (Request-Line) начинается с лексемы метода, затем следует запрашиваемый URI (Request-URI), версия протокола и CRLF. Эти элементы разделяются SP. В строке запроса (Request-Line) не допустимы CR и LF, исключение составляет конечная последовательность CRLF.
Request-Line = Method SP Request-URI SP HTTP-Version CRLF
5.1.1 Метод (Method).
Лексема метода указывает метод, который нужно применить к ресурсу, идентифицированному запрашиваемым URI (Request-URI). Метод чувствителен к регистру.
Method = "OPTIONS" ; Раздел 9.2 | "GET" ; Раздел 9.3 | "HEAD" ; Раздел 9.4 | "POST" ; Раздел 9.5 | "PUT" ; Раздел 9.6 | "DELETE" ; Раздел 9.7 | "TRACE" ; Раздел 9.8 | extension-method extension-method = token
Список методов, применимых к ресурсу, может быть указан в поле заголовка Allow (раздел 14.7). Возврашаемый код состояния ответа всегда сообщает клиенту, допустим ли метод для ресурса в настоящее время, так как набор допустимых методов может изменяться динамически. Серверам СЛЕДУЕТ возвратить код состояния 405 (Метод не дозволен, Method Not Allowed), если метод известен серверу, но не применим для запрошенного ресурса, и 501 (Не реализовано, Not Implemented), если метод не распознан или не реализован сервером. Список методов, известных серверу, может быть указан в поле заголовка ответа Public (раздел 14.35).
Методы GET и HEAD ДОЛЖНЫ поддерживаться всеми универсальными (general-purpose) серверами. Остальные методы опциональны; однако, если вышеупомянутые методы реализованы, то они ДОЛЖНЫ иметь семантику, описанную в разделе 9.
5.1.2 Запрашиваемый URI (Request-URI).
Запрашиваемый URI (Request-URI) — это Единообразный Идентификатор Ресурса (URL, раздел 3.2), который идентифицирует ресурс запроса.
Request-URI = "*" | absoluteURI | abs_path
Три опции для запрашиваемого URI (Request-URI) зависят от характера запроса. Звездочка «*» означает, что запрос обращается не к специфическому ресурсу, а к серверу непосредственно, и допускается только в том случае, когда используемый метод не обязательно обращается к ресурсу. В качестве примера:
OPTIONS * HTTP/1.1
absoluteURI необходим, когда запрос производится через прокси-сервер. Прокси-сервер перенаправляет запрос на сервер или обслуживает его, пользуясь кэшем, и возвращает ответ. Обратите внимание, что прокси-сервер МОЖЕТ переслать запрос другому прокси-серверу или непосредственно серверу, определенному absoluteURI. Чтобы избежать зацикливания запроса прокси-сервер ДОЛЖЕН быть способен распознавать все имена сервера, включая любые псевдонимы, локальные разновидности, и числовые IP адреса. Request-Line может быть, например, таким:
GET http://www.w3.org/pub/WWW/TheProject.html HTTP/1.1
Чтобы обеспечить переход к absoluteURI во всех запросах в будущих версиях HTTP, все HTTP/1.1 серверы ДОЛЖНЫ принимать absoluteURI в запросах, хотя HTTP/1.1 клиенты будут генерировать их только в запросах к прокси-серверам.
Наиболее общая форма Request-URI — та, которая используется для идентификации ресурса на первоначальном сервере или шлюзе. В этом случае абсолютный путь URI (смотрите раздел 3.2.1, abs_path) ДОЛЖЕН быть передан как Request-URI, а сетевое расположение URI (net_loc) ДОЛЖНО быть передано в поле заголовка Host. Для последнего примера клиент, желающий получить ресурс непосредственно с первоначального сервера должен создать TCP соединение на 80 порт хоста «www.w3.org» и послать строки:
GET /pub/WWW/TheProject.html HTTP/1.1 Host: www.w3.org
и далее остаток запроса. Обратите внимание, что абсолютный путь не может быть пустым; если оригинальный URI пуст, то он ДОЛЖЕН запрашиваться как «/» (корневой каталог сервера).
Если прокси-сервер получает запрос без пути в Request-URI, и метод запроса допускает форму запроса «*», то последний прокси-сервер в цепочке запросов ДОЛЖЕН передать запрос, в котором Request-URI равен «*». Например запрос
OPTIONS http://www.ics.uci.edu:8001 HTTP/1.1
был бы передан прокси-сервером в виде
OPTIONS * HTTP/1.1 Host: www.ics.uci.edu:8001
после соединения с портом 8001 хоста «www.ics.uci.edu».
Request-URI передается в формате, определенном в разделе 3.2.1. Первоначальный сервер ДОЛЖЕН декодировать Request-URI, чтобы правильно интерпретировать запрос. Серверам СЛЕДУЕТ отвечать на недопустимые Request-URI соответствующим кодом состояния.
В запросах, которые передаются далее, прокси-сервера никогда НЕ ДОЛЖНЫ перезаписывать часть «abs_path» запрашиваемого URI (Request-URI), за исключением случая, отмеченного выше, когда пустой abs_path заменяется на «*», независимо от внутренней реализации прокси-сервера.
Обратите внимание: правило «ничто не перезаписывать» предохраняет прокси-сервера от изменения значения запроса, в котором первоначальный сервер неправильно использует не зарезервированные символы URL для своих целей. Реализаторам следует знать, что некоторые до-HTTP/1.1 прокси-сервера, как известно, перезаписывали Request-URI.
5.2 Ресурс, идентифицируемый запросом.
Первоначальные HTTP/1.1 сервера ДОЛЖНЫ учитывать, что точный ресурс, идентифицированный интернет-запросом определяется исследованием как Request-URI, так и поля заголовка Host.
Первоначальный сервер, который не позволяет ресурсам отличаться по запрошенному хосту (host), МОЖЕТ игнорировать значение поля заголовка Host. (Но смотрите раздел 19.5.1 для других требований по поддержке Host в HTTP/1.1).
Первоначальный сервер, который различает ресурсы, основанные на запрошенном хосте (иногда называемые виртуальными хостами или vanity hostnames) ДОЛЖЕН использовать следующие правила для определения запрошенного в HTTP/1.1 запросе ресурса:
- Если Request-URI — это absoluteURI, то хост — это часть Request-URI. Любое значение поля заголовка Host в запросе ДОЛЖНО игнорироваться.
- Если Request-URI — не absoluteURI, а запрос содержит поле заголовка Host, то хост определяется значением поля заголовка Host.
- Если хоста, определенного правилами 1 или 2 не существует на сервере, код состояния ответа ДОЛЖЕН быть 400 (Испорченный Запрос, Bad Request).
Получатели HTTP/1.0 запроса, в котором недостает поля заголовка Host, МОГУТ пытаться использовать эвристику (например, исследовать путь в URI на предмет уникальности на каком-либо из хостов) чтобы определить какой точно ресурс запрашивается.
5.3 Поля заголовка запроса.
Поля заголовка запроса позволяют клиенту передавать серверу дополнительную информацию о запросе и о самом клиенте. Эти поля действуют как модификаторы запроса с семантикой, эквивалентной параметрам вызова методов в языках программирования.
request-header = Accept ; Раздел 14.1 | Accept-Charset ; Раздел 14.2 | Accept-Encoding ; Раздел 14.3 | Accept-Language ; Раздел 14.4 | Authorization ; Раздел 14.8 | From ; Раздел 14.22 | Host ; Раздел 14.23 | If-Modified-Since ; Раздел 14.24 | If-Match ; Раздел 14.25 | If-None-Match ; Раздел 14.26 | If-Range ; Раздел 14.27 | If-Unmodified-Since ; Раздел 14.28 | Max-Forwards ; Раздел 14.31 | Proxy-Authorization ; Раздел 14.34 | Range ; Раздел 14.36 | Referer ; Раздел 14.37 | User-Agent ; Раздел 14.42
Имена полей заголовка запроса (Request-header) могут быть надежно расширены только в сочетании с изменением версии протокола. Однако, новые или экспериментальные поля заголовка могут получить семантику полей заголовка запроса (Request-header), если все стороны соединения распознают их как поля заголовка запроса (Request-header). Нераспознанные поля заголовка обрабатываются как поля заголовка объекта (entity-header).
Что такое URL-адрес?
Данная статья описывает Единый локатор ресурсов или Uniform Resource Locators (URLs), объясняет, что это такое, и описывает его структуру.
| Предварительно: | Вам нужно узнать как работает интернет, что такое Веб сервер (en-US) and что лежит в основе веб ссылок. |
|---|---|
| Цель: | Вы узнаете, что такое URL и как они работают в вебе. |
Введение
Наряду с понятиями гипертекста и протокола HTTP, понятие URL является одной из основных концепций Всемирной паутины. Это механизм, используемый браузерами для получения любого опубликованного во Всемирной сети ресурса.
URL обозначает Uniform Resource Locator. URL это лишь адрес, который выдан уникальному ресурсу в интернете. В теории, каждый корректный URL ведёт на уникальный ресурс. Такими ресурсами могут быть HTML-страница, CSS-файл, изображение и т.д. На практике, существуют некоторые исключения, когда, например, URL ведёт на ресурс, который больше не существует или который был перемещён. Поскольку ресурс, доступный по URL, а также сам URL обрабатываются веб-сервером, его владелец должен внимательно следить за размещаемыми ресурсами и связанными с ними URL.
Активное обучение
Подробная информация
Основы: анатомия URL
Вот несколько примеров URL:
https://developer.mozilla.org https://developer.mozilla.org/ru/docs/Learn/ https://developer.mozilla.org/ru/search?q=URL
Каждый из этих URLs могут быть напечатаны в адресной строке браузера, чтобы заставить его загрузить связанную страницу (ресурс).
URL состоит из различных частей, некоторые из которых являются обязательными, а некоторые — факультативными. Рассмотрим наиболее важные части на примере:
http://www.example.com:80/path/to/myfile.html?key1=value1&key2=value2#SomewhereInTheDocument

http:// это протокол. Он отображает, какой протокол браузер должен использовать. Обычно это HTTP-протокол или его безопасная версия — HTTPS. Интернет требует эти 2 протокола, но браузеры часто могут использовать и другие протоколы, например mailto: (чтобы открыть почтовый клиент) или ftp: для запуска передачи файлов, так что не стоит удивляться, если вы вдруг увидите другие протоколы.

www.example.com это доменное имя. Оно означает, какой веб-сервер должен быть запрошен. В качестве альтернативы может быть использован и IP-адрес, но это делается редко, поскольку запоминать IP сложнее, и это не популярно в интернете.

:80 это порт. Он отображает технический параметр, используемый для доступа к ресурсам на веб-сервере. Обычно подразумевается, что веб-сервер использует стандартные порты HTTP-протокола (80 для HTTP и 443 для HTTPS) для доступа к своим ресурсам. В любом случае, порт — это факультативная составная часть URL.

/path/to/myfile.html это адрес ресурса на веб-сервере. В прошлом, адрес отображал местоположение реального файла в реальной директории на веб-сервере. В наши дни это чаще всего абстракция, позволяющая обрабатывать адреса и отображать тот или иной контент из баз данных.
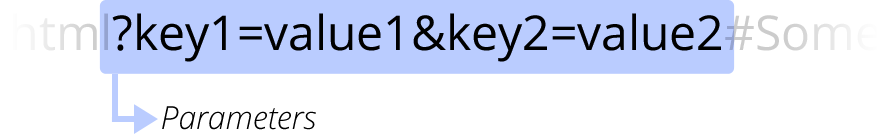
?key1=value1&key2=value2 это дополнительные параметры, которые браузер сообщает веб-серверу. Эти параметры — список пар ключ/значение, которые разделены символом & . Веб-сервер может использовать эти параметры для исполнения дополнительных команд перед тем как отдать ресурс. Каждый веб-сервер имеет свои собственные правила обработки этих параметров и узнать их можно, только спросив владельца сервера.

#SomewhereInTheDocument это якорь на другую часть того же самого ресурса. Якорь представляет собой вид «закладки» внутри ресурса, которая переадресовывает браузер на «заложенную» часть ресурса. В HTML-документе, например, браузер может переместиться в точку, где установлен якорь; в видео- или аудио-документе браузер может перейти к времени, на которое ссылается якорь. Важно отметить, что часть URL после #, которая также известна как идентификатор фрагмента, никогда не посылается на сервер вместе с запросом.
Примечание: Есть и другие составные части и правила, касающиеся URL, но обычно они не используются ни пользователями, ни разработчика. Поэтому не стоит о них беспокоиться, вам не обязательно их знать, чтобы формировать работоспособные URL.
Вам стоит представлять URL как обычный почтовый адрес: протокол обозначает почтовый транспорт, который вы собираетесь использовать,доменное имя — это город, порт — это почтовый индекс; адрес — это номер дома;параметры представляют собой дополнительную информацию, как, например, номер квартиры; и, наконец, якорь представляет собой конкретного получателя, которому вы адресуете своё письмо.
Как использовать URL
Каждый URL может быть напечатан напрямую в адресной строке браузера, чтобы сразу получить запрошенный ресурс. Но это только вершина айсберга!
- создания ссылок на другие документы с помощью тега ;
- связывания документа с его дополнительными файлами, например с помощью тегов или ;
- отображения медиа-элементов, например изображений (с помощью тега ), видео (с помощью тега ), звуков и музыки (с помощью тега ) и так далее;
- отображения других HTML-документов внутри текущего с помощью тега (en-US).
Примечание: При указании URL-адресов для загрузки ресурсов как части страницы (например, при использовании , , , , и т.д.), следует использовать только URL-адреса HTTP и HTTPS. Использование FTP, например, не особенно безопасно и больше не поддерживается многими браузерами.
Другие технологии, такие как CSS или JavaScript, также активно используют URL, так что это реально основа веба.
Абсолютные и относительные URL
Все, что мы изучали выше — это абсолютные URL. Но так же существуют и относительные URL. Изучим их.
Обязательные части URL во многом зависят от контекста, в котором используется URL. В адресной строке браузера URL не имеет никакого контекста, так что приходится вводить полный (или абсолютный) URL, такие как мы рассматривали выше. Обычно вам не требуется вводить протокол (браузер подставляет HTTP по умолчанию) и порт (который нужен только в том случае, если сервер использует нестандартный порт), но остальные части URL всё равно необходимы.
Когда URL используется в документе, например в HTML-странице, ситуация отличается. Потому что браузер уже знает URL текущего документа и он может использовать эти сведения для дополнения недостающих частей любого адреса, указанного в документе. Простейший пример относительного URL — указание только адресной части URL. А если адрес в URL начинается с символа «/ «, браузер запросит ресурс от корня сервера, без отсылки к контексту текущего документа.
Разберём это на примерах.
Примеры абсолютных URL
https://developer.mozilla.org/ru/docs/Learn
//developer.mozilla.org/ru/docs/Learn
В этом случае браузер использует тот же протокол, что использовался для загрузки текущего документа.
/ru/docs/Learn
Это наиболее частый пример использования абсолютного URL в HTML-документе. Браузер использует тот же протокол и то же доменное имя, как у текущего документа. Примечание: не возможно скрыть домен, не скрывая при этом протокол, только вместе.
Примеры относительных URL
Для лучшего понимания следующих примеров, давайте договоримся, что мы обращаемся к URL из документа, который опубликован по адресу: https://developer.mozilla.org/ru/docs/Learn
Skills/Infrastructure/Understanding_URLs
Поскольку URL не начинается с / , браузер сделает попытку найти документ в поддиректории относительно текущего документа. В данном примере будет запрошен этот URL: https://developer.mozilla.org/ru/docs/Learn/Skills/Infrastructure/Understanding_URLs
../CSS/display
В этом случае, мы используем команду ../ — унаследованную из файловой системы UNIX — чтобы сказать браузеру, что он должен подняться на 1 директорию вверх. Соответственно, здесь мы хотим открыть URL: https://developer.mozilla.org/ru/docs/Learn/../CSS/display , который может быть упрощён до вида: https://developer.mozilla.org/ru/docs/CSS/display
Семантические URL
Помимо своего технического значения, URL представляют собой человеко-читаемые записи о местоположении документов на веб-ресурсе. Они могут быть запомнены и любой может ввести их в адресную строку своего браузера. Веб создавался для людей и распространённой практикой является принцип записи URL, который называется семантические URL. Семантические URL используют в своём составе слова, значение которых может быть понято любым человеком, даже тем, кто не разбирается в технических нюансах.
Семантика, разумеется, плохо распознаётся компьютерами. Вы наверняка видели URL, которые выглядят как куча случайных символов. Но у семантических URL есть много преимуществ:
- Ими легче управлять.
- Они дают понять пользователю, что находится по данному URL даже без перехода на страницу.
- Поисковые системы могут использовать семантику для улучшения классификации страниц.
Следующие шаги
Found a content problem with this page?
- Edit the page on GitHub.
- Report the content issue.
- View the source on GitHub.
This page was last modified on 3 авг. 2023 г. by MDN contributors.
Request
Интерфейс Request из Fetch API является запросом ресурсов или данных.
Создать новый объект Request можно, используя конструктор Request() (en-US), однако чаще всего встречается способ возврата объекта Request , как результат операции API. Например такой как service worker FetchEvent.request (en-US).
Конструктор
Создаёт новый Request объект.
Параметры
Request.cache (en-US) Только для чтения
Содержит кешированное состояние запроса (напр., default , reload , no-cache ).
Содержит контекст запроса (напр., audio , image , iframe , и т.д..)
Содержит данные идентификации запроса (напр., «omit» , «same-origin» , «include» ). Значение по умолчанию: «same-origin» .
Возвращает строку из RequestDestination (en-US) enum, описывая назначение запроса. Это строка, указывающая тип запрошенных данных.
Содержит назначенный Headers (en-US) объект запроса (заголовки).
Содержит «subresource integrity (en-US) » значение запроса (напр., sha256-BpfBw7ivV8q2jLiT13fxDYAe2tJllusRSZ273h2nFSE= ).
Содержит метод запроса ( GET , POST , и т.д.)
Request.mode Только для чтения
Содержит режим запроса (напр., cors , no-cors , same-origin , navigate .)
Содержит режим перенаправления. Может быть одним из следующих: follow , error , или manual .
Содержит значение «referrer» («ссылающийся») запроса (например., client ).
Содержит политику «ссылающегося» данного запроса (e.g., no-referrer ).
Содержит URL запроса.
Request имплементирует Body , таким образом наследуя следующие параметры:
Простой getter используемый для раскрытия ReadableStream (en-US) «тела» (body) содержимого.
Хранит Boolean (en-US), декларирующее использовалось ли «тело» ранее в ответе.
Методы
Создаёт копию текущего Request объекта.
Request имплементирует Body , таким образом наследуя следующие параметры:
Возвращает промис, который выполняется, возвращая ArrayBuffer репрезентацию тела запроса.
Возвращает promise который разрешается с помощью FormData представления тела запроса.
Returns a promise that resolves with a JSON representation of the request body.
Returns a promise that resolves with an USVString (en-US) (text) representation of the request body.
Примечание: The Body functions can be run only once; subsequent calls will resolve with empty strings/ArrayBuffers.
Examples
In the following snippet, we create a new request using the Request() constructor (for an image file in the same directory as the script), then return some property values of the request:
const request = new Request("https://www.mozilla.org/favicon.ico"); const URL = request.url; const method = request.method; const credentials = request.credentials;
You could then fetch this request by passing the Request object in as a parameter to a fetch() call, for example:
fetch(request) .then((response) => response.blob()) .then((blob) => image.src = URL.createObjectURL(blob); >);
In the following snippet, we create a new request using the Request() constructor with some initial data and body content for an api request which need a body payload:
const request = new Request("https://example.com", method: "POST", body: '', >); const URL = request.url; const method = request.method; const credentials = request.credentials; const bodyUsed = request.bodyUsed;
Примечание: Типом тела может быть только Blob , BufferSource , FormData , URLSearchParams , USVString (en-US) или ReadableStream (en-US) поэтому, для добавления объекта JSON в полезную нагрузку вам необходимо структурировать этот объект.
Вы можете получить этот запрос API, передав объект Request в качестве параметра для вызова fetch() , например, и получить ответ:
fetch(request) .then((response) => if (response.status === 200) return response.json(); > else throw new Error("Что-то пошло не так на API сервере."); > >) .then((response) => console.debug(response); // . >) .catch((error) => console.error(error); >);
Specifications
| Specification |
|---|
| Fetch Standard # request-class |
Совместимость с браузерами
BCD tables only load in the browser
Читай также
Found a content problem with this page?
- Edit the page on GitHub.
- Report the content issue.
- View the source on GitHub.
This page was last modified on 6 янв. 2024 г. by MDN contributors.
Your blueprint for a better internet.
Requests
requests — это библиотека, с помощью которой можно делать запросы в интернет. Само слово “requests” переводится как запросы. Вот как сделать запрос на сайт google.com:
import requests url = 'https://google.com' response = requests.get(url) response.raise_for_status() Функция requests.get() делает запрос к сайту google.com, а в переменной response теперь ответ от сайта. Ответ — это не строка и не число. Это сложный объект, в котором есть много всего. Подробнее об этом можно посмотреть в слайдах.
Строчка response.raise_for_status() нужна для того, чтобы проверить, понял вас сервер или нет. Если сервер вернёт 404 «Ресурс не найден», то в response не будет странички сайта google.com, а будет только “Ошибка 404”. Если не вызвать raise_for_status , программа подумает, что всё в порядке, что вы так и хотели: отправить запрос на страницу, которой нет. Обязательно вызывайте .raise_for_status() после каждого запроса в интернет, иначе вы рискуете потратить кучу времени на поиск ошибки, которую замалчивает библиотека requests .
Всегда вызывайте .raise_for_status()
Вот как получить текст ответа от сервера:
print(response.text) В ответ вы получите огромный HTML-документ одной строкой. Начинаться будет так:
Именно это получает ваш браузер, когда вы заходите на сайт google.com, и из этого он уже отрисовывает красивую страничку.
Но стоит понимать, что requests может скачивать не только HTML-документы, а буквально всё, что есть в интернете.
Вот как скачать картинку:
import requests url = "https://dvmn.org/filer/canonical/1542890876/16/" response = requests.get(url) response.raise_for_status() filename = 'dvmn.svg' with open(filename, 'wb') as file: file.write(response.content) То же самое: делаем запрос по ссылке, получаем ответ, потом сохраняем его в файл. Единственное отличие в том, что вместо response.text для картинок используется response.content , потому что картинка — это не текст.
.text — для текста, .content — для картинки
Узнать больше
- Руководство по работе с requests
- Работа с файлами в Python
- Больше о кодах состояния HTTP
Попробуйте бесплатные уроки по Python
Получите крутое код-ревью от практикующих программистов с разбором ошибок и рекомендациями, на что обратить внимание — бесплатно.
Переходите на страницу учебных модулей «Девмана» и выбирайте тему.