Big O — Java: Массивы
Когда заходит речь про алгоритмы, нельзя не упомянуть понятие «сложность алгоритма» (обозначается как Big O). Оно дает понимание того, насколько эффективен алгоритм.
Как вы помните, алгоритмов сортировок существует много . Все они выполняют одну и ту же задачу, но при этом отличаются друг от друга. В информатике алгоритмы сравниваются друг с другом по их алгоритмической сложности. Эта сложность оценивается как количество выполняемых операций алгоритмом для достижения своей цели. Например разные способы сортировки требуют очень разного количества «проходов» по массиву перед тем как массив будет полностью отсортирован. Понятно, что конкретное количество операций зависит от входных данных, например, если массив уже отсортирован, то количество операций будет минимальным (но они все равно будут, потому что алгоритм должен убедиться в том, что массив отсортирован).
Big O как раз придумана для описания алгоритмической сложности. Она призвана показать, как сильно увеличится количество операций при увеличении размера данных.
Вот некоторые примеры того, как записывается сложность: O(1), O(n), O(nlog(n)).
O(1) описывает константную (постоянную) сложность. Такой сложностью обладает операция доступа к элементу массива по индексу. Сложность (в алгоритмическом смысле) доступа к элементу не зависит от размеров массива и является величиной постоянной. А вот функция, которая печатает на экран все элементы переданного массива, используя обычный перебор, имеет сложность O(n) (линейная сложность). То есть количество выполняемых операций, в худшем случае, будет равно количеству элементов массива. Именно это количество символизирует символ n в скобках.
Что такое худший случай? В зависимости от того в каком состоянии находятся начальный массив, количество операций будет разным даже при условии, что массив одного и того же размера. Чтобы проще понять, возьмем в качестве аналогии Кубик Рубика. Количество операций (действий) которые нужно проделать для сборки Кубика Рубика зависит от того, в каком положении находятся его грани перед сборкой. В некоторых случаях действий понадобится мало, в других много. И вот та ситуация, в которой таких действий понадобится больше всего и называется худшим случаем. Алгоритмическая сложность всегда оценивается по худшему случаю для выбранного алгоритма.
Еще один пример — вложенные циклы. Вспомните как работает поиск пересечений в неотсортированных массивах. Для каждого элемента из одного массива проверяется каждый элемент другого массива (либо через цикл, либо с помощью метода includes() , чья сложность O(n), ведь в худшем случае он просматривает весь массив). Если принять, что размеры обоих массивов одинаковы и равны n, то получается, что поиск пересечений имеет квадратичную сложность или O(n^2) (n в квадрате).
Существуют как очень эффективные, так и абсолютно неэффективные алгоритмы. Скорость работы подобных алгоритмов падает с катастрофической скоростью даже при небольшом количестве элементов. Нередко более быстрые алгоритмы быстрее не потому, что они лучше, а потому что они потребляют больше памяти или имеют возможность запускаться параллельно (и если это происходит, то работают крайне эффективно). Как и все в инженерной деятельности, эффективность — компромисс. Выигрывая в одном месте, мы проиграем где-то в другом.
Big O, во многом, теоретическая оценка, на практике все может быть по-другому. Реальное время выполнения зависит от множества факторов среди которых: архитектура процессора, операционная система, язык программирования, доступ к памяти (последовательный или произвольный) и многое другое.
Вопрос эффективности кода довольно опасен. В силу того, что многие начинают учить программирование именно с алгоритмов (особенно в университете), им начинает казаться, что эффективность — это главное. Код должен быть быстрым.
Такое отношение к коду гораздо чаще приводит к проблемам, чем делает его лучше. Важно понимать, что эффективность — враг понимаемости. Такой код всегда сложнее, больше подвержен ошибкам, труднее модифицируется, дольше пишется. А главное, настоящая эффективность редко когда нужна сразу или вообще не нужна. Обычно тормозит не код, а, например, запросы к базе данных или сеть. Но даже если код выполняется медленно, то вполне вероятно, что именно тот участок, который вы пытаетесь оптимизировать, вызывается за все время жизни программы всего лишь один раз и ни на что не влияет, потому что работает с небольшим объемом памяти, а где-то в это время есть другой кусок, который вызывается тысячи раз, и приводит к реальному замедлению.
Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
Оценка сложности алгоритмов, или Что такое О(log n)
Если вы всё ещё не понимаете, что такое вычислительная сложность алгоритмов, и ждете простое и понятное объяснение, — эта статья для вас.
Наверняка вы не раз сталкивались с обозначениями вроде O(log n) или слышали фразы типа «логарифмическая вычислительная сложность» в адрес каких-либо алгоритмов. И если вы хотите стать хорошим программистом, но так и не понимаете, что это значит, — данная статья для вас.
Оценка сложности
Сложность алгоритмов обычно оценивают по времени выполнения или по используемой памяти. В обоих случаях сложность зависит от размеров входных данных: массив из 100 элементов будет обработан быстрее, чем аналогичный из 1000. При этом точное время мало кого интересует: оно зависит от процессора, типа данных, языка программирования и множества других параметров. Важна лишь асимптотическая сложность, т. е. сложность при стремлении размера входных данных к бесконечности.
Допустим, некоторому алгоритму нужно выполнить 4n3 + 7n условных операций, чтобы обработать n элементов входных данных. При увеличении n на итоговое время работы будет значительно больше влиять возведение n в куб, чем умножение его на 4 или же прибавление 7n . Тогда говорят, что временная сложность этого алгоритма равна О(n3) , т. е. зависит от размера входных данных кубически.
Использование заглавной буквы О (или так называемая О-нотация) пришло из математики, где её применяют для сравнения асимптотического поведения функций. Формально O(f(n)) означает, что время работы алгоритма (или объём занимаемой памяти) растёт в зависимости от объёма входных данных не быстрее, чем некоторая константа, умноженная на f(n) .
Примеры
O(n) — линейная сложность
Такой сложностью обладает, например, алгоритм поиска наибольшего элемента в не отсортированном массиве. Нам придётся пройтись по всем n элементам массива, чтобы понять, какой из них максимальный.
O(log n) — логарифмическая сложность
Простейший пример — бинарный поиск. Если массив отсортирован, мы можем проверить, есть ли в нём какое-то конкретное значение, методом деления пополам. Проверим средний элемент, если он больше искомого, то отбросим вторую половину массива — там его точно нет. Если же меньше, то наоборот — отбросим начальную половину. И так будем продолжать делить пополам, в итоге проверим log n элементов.
O(n2) — квадратичная сложность
Такую сложность имеет, например, алгоритм сортировки вставками. В канонической реализации он представляет из себя два вложенных цикла: один, чтобы проходить по всему массиву, а второй, чтобы находить место очередному элементу в уже отсортированной части. Таким образом, количество операций будет зависеть от размера массива как n * n , т. е. n2 .
Бывают и другие оценки по сложности, но все они основаны на том же принципе.
Также случается, что время работы алгоритма вообще не зависит от размера входных данных. Тогда сложность обозначают как O(1) . Например, для определения значения третьего элемента массива не нужно ни запоминать элементы, ни проходить по ним сколько-то раз. Всегда нужно просто дождаться в потоке входных данных третий элемент и это будет результатом, на вычисление которого для любого количества данных нужно одно и то же время.
Аналогично проводят оценку и по памяти, когда это важно. Однако алгоритмы могут использовать значительно больше памяти при увеличении размера входных данных, чем другие, но зато работать быстрее. И наоборот. Это помогает выбирать оптимальные пути решения задач исходя из текущих условий и требований.
Наглядно
Время выполнения алгоритма с определённой сложностью в зависимости от размера входных данных при скорости 106 операций в секунду:
Если хочется подробнее и сложнее, заглядывайте в нашу статью из серии «Алгоритмы и структуры данных для начинающих».
Какая временная сложность поиска в обычном массиве
Ilia lenskii Уровень 32
24 сентября 2022
Умный комментарий > “Линейная” означает, что при увеличении объема данных время на их передачу вырастет примерно пропорционально. Это курс алгебры 7 класс > Логарифмическая сложность Это курс алгебры 9 класс Сейчас пошли такие учебники, где-то с 2012, где есть доп. задания + уроки на информатике. Если уж деткам такое преподают, то взрослый человек должен понять. Далее. Для тех кто страдает от алгоритмов и структур данных на собеседования. Если в описании требований к соискателю (вакансия) не написано, что-то похожее на — алгоритмы и структуры данных, но вас начинают спрашивать или предлагать порешать задачки, то стоит про это сказать интервьюеру. Мол, спрашиваете не по теме вакансии. Это покажет вашу адекватность, и покажет неадекватность интервьюер. В любом случае, в этом дерьме надо хотя бы поверхностно разбираться.
Сергей Смарт Уровень 51
13 сентября 2022
«Для решения твоей простой задачи хлеб и масло можно просто купить.» А для того что б купить нужны деньги, что б получить деньги нужно найти работу, а что б найти работу нужно отучиться хотя бы базовым знаниям, не такой уж и простой алгоритм��
Знай сложности алгоритмов
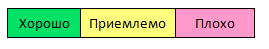
Эта статья рассказывает о времени выполнения и о расходе памяти большинства алгоритмов используемых в информатике. В прошлом, когда я готовился к прохождению собеседования я потратил много времени исследуя интернет для поиска информации о лучшем, среднем и худшем случае работы алгоритмов поиска и сортировки, чтобы заданный вопрос на собеседовании не поставил меня в тупик. За последние несколько лет я проходил интервью в нескольких стартапах из Силиконовой долины, а также в некоторых крупных компаниях таких как Yahoo, eBay, LinkedIn и Google и каждый раз, когда я готовился к интервью, я подумал: «Почему никто не создал хорошую шпаргалку по асимптотической сложности алгоритмов? ». Чтобы сохранить ваше время я создал такую шпаргалку. Наслаждайтесь!
Поиск
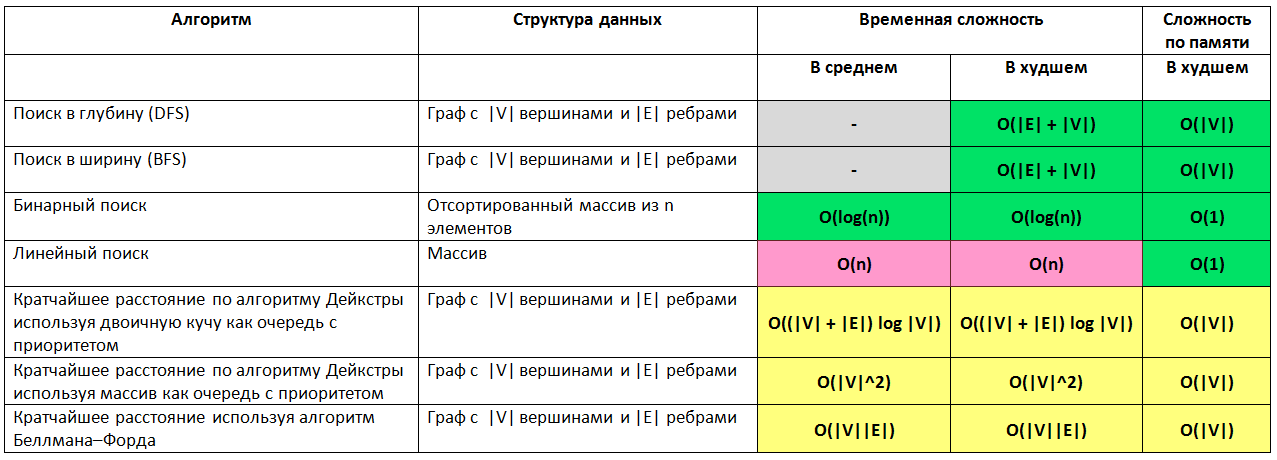
Сортировка

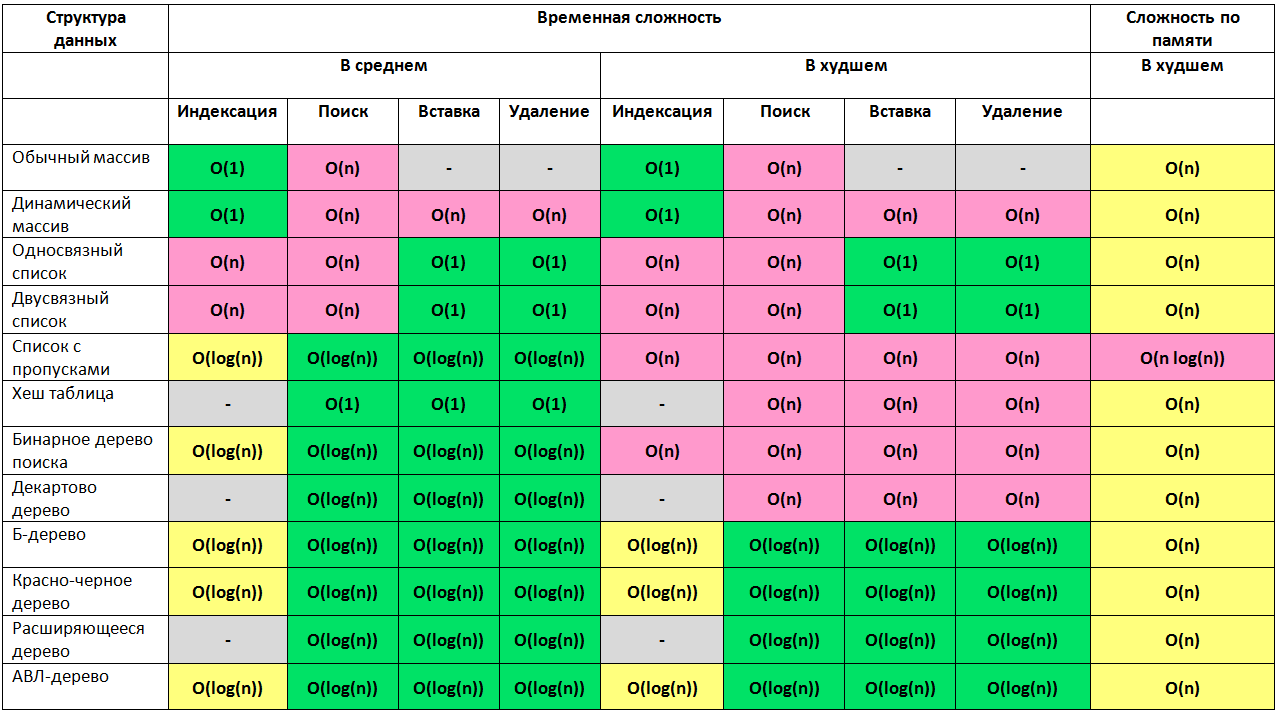
Структуры данных
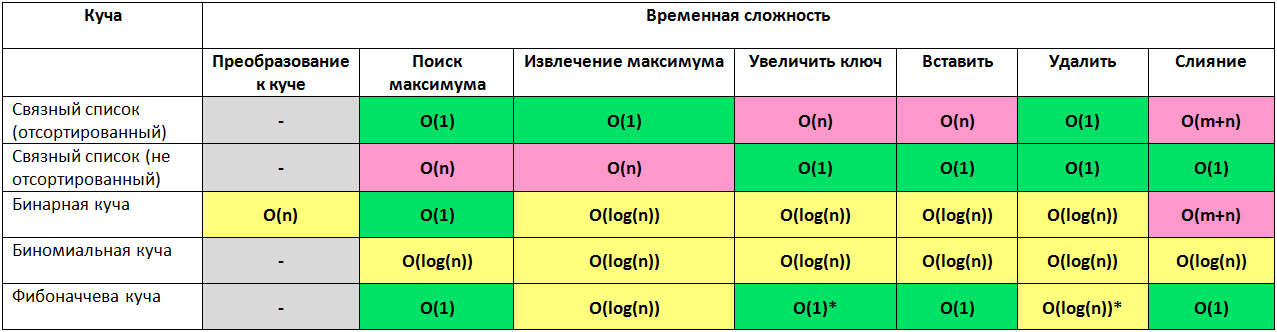
Кучи
Представление графов
Пусть дан граф с |V| вершинами и |E| ребрами, тогда

Нотация асимптотического роста
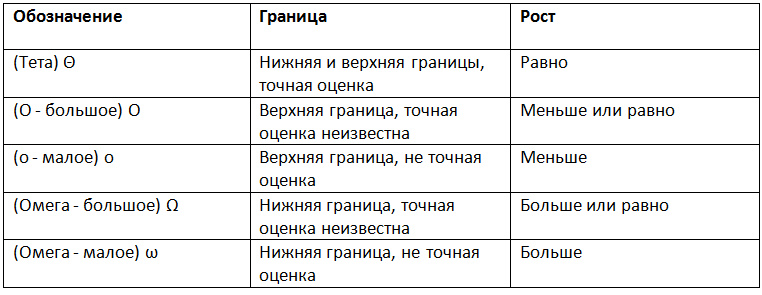

- (О — большое) — верхняя граница, в то время как (Омега — большое) — нижняя граница. Тета требует как (О — большое), так и (Омега — большое), поэтому она является точной оценкой (она должна быть ограничена как сверху, так и снизу). К примеру, алгоритм требующий Ω (n logn) требует не менее n logn времени, но верхняя граница не известна. Алгоритм требующий Θ (n logn) предпочтительнее потому, что он требует не менее n logn (Ω (n logn)) и не более чем n logn (O(n logn)).
- f(x)=Θ(g(n)) означает, что f растет так же как и g когда n стремится к бесконечности. Другими словами, скорость роста f(x) асимптотически пропорциональна скорости роста g(n).
- f(x)=O(g(n)). Здесь темпы роста не быстрее, чем g (n). O большое является наиболее полезной, поскольку представляет наихудший случай.
Короче говоря, если алгоритм имеет сложность __ тогда его эффективность __
График роста O — большое

- алгоритмы
- асимптотический анализ алгоритмов