Начало работы с базами данных

Базы данных и веб-приложения могут принести большую пользу вашему бизнесу. Проектирование базы данных играет важнейшую роль в достижении ваших целей независимо от того, что вам нужно: управлять сведениями о сотрудниках, предоставлять еженедельные отчеты по данным или отслеживать заказы клиентов. Уделив время изучению всех нюансов проектирования баз данных, вы сможете создавать базы, которые будут не только отвечать вашим текущим требованиям, но и адаптироваться к изменениям.
Важно: Веб-приложения Access отличаются от классических баз данных. В этой статье не рассматривается проектирование веб-приложений.
Понятия и термины
Для начала рассмотрим основные термины и понятия. Чтобы спроектировать полезную базу данных, необходимо создать таблицы с данными по одному объекту. В таблицах можно собрать все данные по этому объекту и отобразить их полях, которые содержат наименьшую единицу данных.
Реляционные базы данных
База данных, в которой данные разделены на таблицы по типу электронных. Каждая таблица включает данные по одному объекту, например по клиентам (одна таблица) или товарам (другая таблица).
Записи и поля
Области хранения отдельных данных в таблице. В каждой строке (или записи) хранится уникальный элемент данных, например имя клиента. Столбцы (или поля) содержат сведения по каждой точке данных в виде наименьшей единицы: имя может находиться в одном столбце, а фамилия — в другом.
Первичный ключ
Значение, которое обеспечивает уникальность каждой записи. Допустим, есть два клиента с одинаковыми именами, например Юрий Богданов. Но у одного из них первичный ключ записей — 12, а у другого — 58.
Иерархические отношения
Общие связи между таблицами. Например, у одного клиента может быть несколько заказов. Родительские таблицы имеют первичные ключи. Детские таблицы имеют внешниеключи , которые являются значениями из первичного ключа, которые показывают, как записи детской таблицы связаны с родительской таблицей. Эти ключи связаны отношением.
Что понимать под хорошим проектированием базы данных?
В основе проектирования хорошей базы данных лежат два принципа:
- Избегайте повторяющихся сведений (избыточных данных). Они занимают много места на диске и повышают вероятность ошибок.
- Следите за правильностью и полнотой данных. Неполные или неправильные сведения отображаются в запросах и отчетах, что в конечном итоге может привести к принятию ошибочных решений.
Чтобы избежать этих проблем:
- Разделяйте информацию в базе данных по таблицам для отдельных объектов. Избегайте повторения информации в нескольких таблицах. (Например, имена клиентов должны находиться только в одной таблице.)
- Объединяйте таблицы с помощью ключей, а не путем дублирования данных.
- Используйте процессы, которые обеспечивают точность и целостность информации в базе данных.
- Проектируйте базу данных с учетом своих требований к обработке данных и созданию отчетов по ним.
Чтобы повысить пользу баз данных в долгосрочной перспективе, выполните следующие пять шагов по проектированию:
Шаг 1. Определение назначения базы данных
Прежде чем начать, сформулируйте цель базы данных.
Дополнительные сведения
Чтобы спроектировать специализированную базу данных, определите ее назначение и часто обращайтесь к этому определению. Если вам нужна небольшая база данных для домашнего бизнеса, можно дать простое определение, например: «Эта база данных содержит список сведений о клиентах для рассылки и создания отчетов». Для корпоративной базы данных можно дать определение из нескольких абзацев, в котором будет описано, когда и как люди с различными ролями используют базу данных и содержащуюся в ней информацию. Создайте специальное и подробное определение цели и периодически обращайтесь к нему в процессе проектирования.
Шаг 2. Поиск и упорядочение необходимых сведений
Соберите все типы данных, которые необходимо записывать, например названия товаров и номера заказов.
Дополнительные сведения
Начните с существующих сведений и методов отслеживания. Предположим, вы записываете заказы на покупку в книге учета или ведете записи о клиентах в бумажных формах. Используйте эти источники, чтобы создать список собираемых сведений (например, всех полей в формах). Если в настоящее время вы не собираете важные сведения, подумайте, какие дискретные данные вам необходимы. Каждый отдельный тип данных становится полем в вашей базе данных.
Не беспокойтесь, если ваш первый список несовершенен — вы сможете доработать его со временем. Однако всегда помните о людях, которые будут пользоваться этой информацией, и учитывайте их мнение.
Затем подумайте, что вы ждете от своей базы данных и какие отчеты или рассылки вы хотите создавать. Убедитесь, что вы собираете данные, которые отвечают этим целям. Например, если вам нужен отчет о продажах по регионам, вам необходимо собирать данные о продажах на региональном уровне. Попробуйте сделать набросок желаемого отчета, используя фактические данные. Затем составьте список данных, необходимых для создания отчета. Сделайте то же самое для рассылок или других выходных данных, которые нужно получить из базы данных.
Предположим, вы даете клиентам возможность подписаться на периодическую рассылку (или отказаться от нее) и хотите распечатать список подписавшихся пользователей. Вам нужно создать столбец «Отправка почты» в таблице «Клиенты» с допустимыми значениями «Да» и «Нет».
Для тех, кто хочет получать рассылку, вам нужно добавить электронный адрес, что также требует отдельного поля. Если вы хотите использовать соответствующее обращение к получателю (например, «Уважаемый» или «Уважаемая»), добавьте поле «Обращение». Если в письмах вы хотите обращаться к клиентам по имени, добавьте поле «Имя».
Совет: Не забывайте разбивать данные на наименьшие единицы, например имя и фамилию в таблице «Клиенты». Вообще, если вы хотите выполнять сортировку, поиск, вычисления или отчет на основе элемента данных (например, фамилии клиента), следует поместить этот элемент в отдельное поле.
Шаг 3. Разделение данных по таблицам
Разделите элементы данных на основные объекты, например товары, клиенты или заказы. Каждый объект выносится в таблицу.
Дополнительные сведения
После создания списка необходимых сведений определите основные объекты, необходимые для организации данных. Избегайте повторения данных между объектами. Например, предварительный список для базы данных по продажам товаров может выглядеть так:

К основным объектам относятся клиенты, поставщики, товары и заказы. Поэтому начните с соответствующих четырех таблиц: по клиентам, поставщикам и т. д. Возможно, ваша конечная цель состоит не в этом, но это будет хорошим началом.
Примечание: Лучшие базы данных содержат несколько таблиц. Избегайте искушения поместить все данные в одну таблицу. Это приведет к повторению информации, увеличению размера базы данных и повышению вероятности ошибок. Каждый элемент данных должен записываться только один раз. Если вы обнаружите повторяющиеся сведения, например адрес поставщика, измените структуру базы данных так, чтобы эта информация находилась в отдельной таблице.
Чтобы понять, почему чем больше таблиц, тем лучше, рассмотрим следующую таблицу:
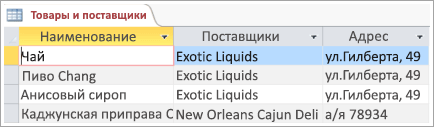
Каждая строка содержит сведения о товаре и его поставщике. Так как у вас может быть несколько продуктов от одного поставщика, имена и адреса поставщиков должны повторяться многократно. Это пустая трата места на диске. Вместо этого зафиксировать сведения о поставщике только один раз в отдельной таблице «Поставщики» и связать ее с таблицей «Товары».
Вторая проблема проектирования возникает тогда, когда нужно изменить сведения о поставщике. Предположим, вам нужно изменить адрес поставщика. А так как адрес указан во многих полях, можно случайно изменить его в одном поле и забыть изменить в других. Эту проблему можно решить, записав адрес поставщика только в одном поле.
Наконец, предположим, у вас есть только один товар, поставляемый компанией Coho Winery, и вы хотите удалить этот товар, но сохранить имя и адрес поставщика. Как удалить запись о товаре, не потеряв сведений о поставщике, с такой структурой базы данных? Это невозможно. Так как каждая запись содержит информацию о товаре вместе с данными о поставщике, их невозможно удалить по отдельности. Чтобы разделить эти сведения, необходимо сделать из одной таблицы две: одну — для сведений о товаре, другую —для сведений о поставщике. И только после этого удаление записи о товаре не будет приводить к удалению сведений о поставщике.
Шаг 4. Превращение элементов данных в столбцы
Определите, какие данные необходимо хранить в каждой таблице. Эти отдельные элементы данных становятся полями в таблице. Например, таблица «Сотрудники» может содержать такие поля, как «Фамилия», «Имя» и «Дата приема на работу».
Дополнительные сведения
После выбора объекта для таблицы базы данных столбцы в ней должны содержать сведения только об этом объекте. Например, таблица по товарам должна содержать сведения только о товарах, а не о поставщиках.
Чтобы определить, какие данные нужно отследить в таблице, используйте ранее созданный список. Например, таблица «Клиенты» может содержать такие поля: «Имя», «Фамилия», «Адрес», «Отправка почты», «Обращение» и «Электронный адрес.» Каждая запись (клиент) в таблице содержит один и тот же набор столбцов, поэтому по каждому клиенту можно хранить одинаковую информацию.
Создайте первый список, а затем просмотрите и уточните его. Не забудьте разбить данные на наименьшие возможные поля. Например, если исходный список имеет адрес в качестве поля, разобьйте его на Адрес, Город, Область и Почтовый индекс или, если ваши клиенты являются глобальными, на еще большее поле. Это, например, позволяет выполнять рассылки в правильном формате или отчет по заказам по штатам.
Доработав столбцы с данными во всех таблицах, вы готовы выбрать первичный ключ для каждой из них.
Шаг 5. Задание первичных ключей
Выберите первичный ключ для каждой таблицы. Первичный ключ, например код товара или код заказа, является уникальным идентификатором каждой записи. Если у вас нет явного уникального идентификатора, его можно создать с помощью Access.
Дополнительные сведения
Вам нужно однозначно определить каждую строку в каждой таблице. Вернемся к примеру с двумя клиентами с одинаковым именем. Так как у них одно и то же имя, им нужно дать уникальный идентификатор.
Поэтому каждая таблица должна содержать столбец (или набор столбцов), который однозначно определяет каждую строку. Это и есть первичный ключ. Он часто является уникальным числом, например кодом сотрудника или порядковым номером Используя первичные ключи, Access быстро связывает данные из нескольких таблиц и сводит их для вас воедино.
Иногда первичный ключ состоит из нескольких полей. Например, в таблице «Сведения о заказе», которая содержит позиции по заказам, первичный ключ может включать два столбца: «Код заказа» и «Код товара». Если в первичном ключе используется несколько столбцов, он также называется составным ключом.
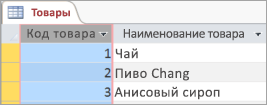
Если у вас уже есть уникальный идентификатор для данных в таблице, например номера товаров, однозначно определяющие каждый продукт в каталоге, используйте его, но только если эти значения соответствуют следующим правилам первичных ключей:
- Идентификатор для каждой записи всегда уникален. Повторяющиеся значения в первичном ключе не допускаются.
- Для каждого элемента всегда существует значение. Каждая запись в таблице должна иметь первичный ключ. Если вы создаете ключ с помощью нескольких столбцов, например «Группа позиций» и «Код позиции», всегда должны присутствовать оба значения.
- Первичный ключ представляет собой неизменное значение. Так как на ключи ссылаются другие таблицы, при любом изменении первичного ключа в одной таблице необходимо изменить его во всех других. Частые изменения повышают риск возникновения ошибок.
Если у вас нет явного идентификатора, то в качестве первичного ключа используйте произвольный уникальный номер. Например, вы можете присвоить каждому заказу уникальный номер, только чтобы идентифицировать его.
Совет: Чтобы создать уникальный номер в качестве первичного ключа, добавьте столбец, используя тип данных «Счетчик». Этот тип данных автоматически присваивает каждой записи уникальное числовое значение. Такой идентификатор не содержит фактических сведений о строке, которую он представляет. Он идеален в качестве первичного ключа, так как в отличие от ключей, содержащих фактические данные о строке (например, номер телефона или имя клиента), числа не изменяются.
Как работать с базами данных SQL в Python
В инструкции научим работать с SQL: писать запросы, получать информацию из таблиц, а также познакомим с пакетами и библиотеками Python.
Введение
Сейчас в любой сфере деятельности человека необходима работа с большим объемом данных. Данные — это поддающееся многократной интерпретации представление информации, приведенное к формализованному виду, который будет пригоден для передачи или обработки. Для удобства использования огромных объемов данных была придумана структура, называемая база данных (БД). База данных — одна из ключевых компонент любой информационной системы.
Для управления базами используются системы управления базами данных (СУБД).
SQL-запросы
Близкое взаимодействие с базами данных неразрывно связано с SQL (Structured Query Language). С помощью него можно не только создать таблицу и заполнить ее уникальной информацией, но и «вытащить» из базы практически любую информацию, используя специальные запросы.
Инициализация таблицы в SQL
В базах данных таблицы представляют собой совокупность данных, хранящихся в структурированном виде. Большие базы данных состоят из множества таблиц, взаимосвязанных специальными видами связи. Для начала создадим таблицу с помощью SQL:
CREATE TABLE Customers ( id INTEGER, name VARCHAR, surname VARCHAR, birthdate DATE, PRIMARY KEY (id) ); Рассмотрим подробнее этот обобщенный код. Команды, выделенные заглавными буквами, являются командами языка SQL. Разные виды БД поддерживают немного различающиеся команды, но большинство из них будет иметь CREATE TABLE.
Важно внимательно работать с типами столбцов, так как они могут отличаться. В нашем примере есть такие типы, как INTEGER для чисел, VARCHAR для строк и DATE для дат. Перед тем как использовать разные типы данных лучше ознакомиться с документацией, так как VARCHAR и DATE могут иметь свои особенности.
Созданная нами таблица будет состоять из четырех столбцов: уникальный идентификатор (будет являться основным ключом), имя, фамилия в строковом типе и дата рождения.
Также при добавлении новой таблицы мы можем задать столбец, в который необходимо будет записать значение. В противном случае при попытке оставить указанный столбец пустым, нам вернется ошибка. Здесь можно провести аналогию с формой регистрации на сайте, когда без указания номера телефона или электронной почты пользователь не сможет зарегистрироваться.
Введение данных в SQL
Сейчас наша таблица пустая. Поэтому сейчас научимся заполнять ее данными:
INSERT INTO Customers (id, name, surname, birthdate) VALUES (1, 'Ivan', 'Petrov', '2001-10-16'); Для добавления новых данных в SQL нужно применять команду INSERT INTO. Также нужно указать, куда будут добавлены данные. При передаче неверного типа данных мы получим ошибку.
Обновление данных в SQL
Может возникнуть ситуация, когда какую-то часть данных необходимо поменять. Конечно, проще изменить данные выборочно, а не переписывать всю базу целиком.
UPDATE Customers SET name='Semyon' WHERE >После команды UPDATE мы обязательно пишем имя таблицы, где требуется обновить данные. После мы применяем SET во всех необходимых местах для замены обновленного значения. Если мы хотим внести изменения в конкретную строку, то нужно сообщить, куда мы собираемся внести правки. Например, в данном случае применяя WHERE, мы выбираем строку с id, равным 1. В результате будет только одна строка, так как подразумевается, что id — это уникальный идентификатор.
Чтение данных в SQL
При чтении данных нужно воспользоваться SELECT:
SELECT name, surname FROM Customers; Так мы вернем все строки нашей таблицы, но в результате будут только две части информации: имя и фамилия. Если мы хотим получить все, что хранится в таблице, то можно воспользоваться запросом:
SELECT * FROM ; В этом случае звездочка означает, что мы намерены получить все имеющиеся в таблице столбцы.
Основные команды SQL
В SQL есть определенное количество команд, используя которые мы усложняем запросы. Комбинируя и правильно используя их, можно получить самые разные выборки данных в зависимости от потребностей. Давайте рассмотрим основные такие команды.
WHERE
Эту команду мы уже упоминали выше. С помощью нее мы указываем какое-то условие:
SELECT , , … FROM WHERE ; Условие может содержать сравнение текста или численных значений. Также допустимо использование классических логических операций: AND (и), OR (или) и NOT (отрицание).
GROUP BY
Оператор GROUP BY применяется для группировки выходных значений, в которых присутствуют агрегатные функции (например, COUNT, MAX, SUM, AVG и другие).
SELECT , , … FROM GROUP BY ; HAVING
По своей сути HAVING является аналогом WHERE. Это ключевое слово применяется вместе с GROUP BY. Это связано с тем, что команда WHERE не может использоваться с вышеперечисленными агрегатными функциями.
SELECT , , . FROM GROUP BY HAVING
ORDER BY
ORDER BY применяется в том случае, когда к результату запроса нужно применить сортировку. По умолчанию команда отсортирует выходной результат в порядке возрастания. Однако можно указать способ сортировки с помощью ASC (по возрастанию) и DESC (по убыванию).
SELECT , , … FROM ORDER BY , , … ASC|DESC; BETWEEN
BETWEEN применяется для выбора значений в определенном диапазоне. Этот оператор работает для чисел и строк, а также дат.
SELECT , , … FROM WHERE BETWEEN AND ; LIKE
Оператор LIKE тоже используется в WHERE, когда задача требует задать шаблон для поиска.
Существует два свободных оператора, с помощью которых мы можем создавать определенные паттерны:
- % (любое количество символов (в том числе ни одного символа));
- _ (ровно один символ).
SELECT , , … FROM WHERE LIKE ; JOIN
JOIN применяется для соединения двух (и более таблиц), основываясь на общих атрибутах.
SELECT , , … FROM JOIN ON = ; Вложенные подзапросы
Вложенные подзапросы — это запросы, включающие стандартные выражения SQL, вложенные в другой запрос. Это удобно использовать, если задача требует написать выделить какую-то информацию из результата другого запроса.
Удаление данных
Теперь мы умеем обрабатывать данные. Осталось научиться их удалять:
DELETE FROM WHERE >Такая команда удалит одну строку, id которой равно 1. Если необходимо удалить таблицу, то стоит применить DROP TABLE:
DROP TABLE ; Однако можно очистить таблицу от данных, не удаляя ее саму:
TRUNCATE TABLE ; С такими командами нужно работать предельно осторожно, ведь есть вероятность потерять важные данные. Чтобы избежать такой ситуации, следует всегда иметь актуальный бекап всей локальной базы данных.
API-модули
Python DB-API — это свод правил, которым следуют самостоятельные модули, задача которых заключается в реализации работы с БД. API-модулем мы называем программный интерфейс, посредством которого мы взаимодействуем с данными. Один принцип позволяет применять общий подход для разных БД. Поэтому для полноценной работы не нужно углубленно изучать каждую БД — достаточно разобраться с несколькими основными моментами.
adodbapi
Если возникает такая ситуация, где обязательно надо реализовать доступ через Microsoft ADO, то идеальным решением будет пакет adodbapi. И нельзя забывать, что adodbapi зависим от уже установленного PyWin32.Чтобы установить adodbapi, делаем следующее:
pip install adodbapi Чтобы все заработало, сначала импортируем библиотеку:
import adodbapi Далее мы указываем все необходимые для соединения данные: имя БД, строку подключения и название соответствующей таблицы.
database = "database.mdb" connect_str = "Provider=Microsoft.Jet.OLEDB.4.0; Data Source=%s; User Password=MyPassword;" % database table_name = "customers" После этого для связи с БД создаем подключение, где аргументом у метода connect() указываем строку связи:
connect = adodbapi.connect(connect_str) Теперь создаем курсор — область памяти базы, предназначенная для хранения последнего оператора SQL. Иными словами, объект, отвечающий и за отправку запросов, и за получение их результатов.
cursor = connect.cursor() Дальше мы уже можем передавать конкретные запросы и обрабатывать их вывод.
query = "SELECT * FROM %s" % table_name cursor.execute(query) В конце обязательно завершаем подключение:
cursor.close() connect.close() pyodbc
Сейчас ознакомимся с ODBC (Open Database Connectivity) — интерфейсом доступа к БД, разработанный в компании Microsoft. Суть ODBC заключается в разработке приложений для использования программного интерфейса доступа без опасений о различиях взаимодействия с разными источниками. Это достигается написанием драйверов, осуществляющих стандартные функции с учетом деталей реализации конкретного продукта. Самый используемый метод связи через ODBC — пакет pyodbc. Он устанавливается с помощью pip:
pip install pyodbc После установки импортируем библиотеку:
import pyodbc Далее необходимо написать строку связи:
connect_str = "DRIVER=; SERVER=localhost; PORT=1433; DATABASE=database; UID=uid; PWD=password" В данном случае строка связи состоит из нескольких частей. Хорошей практикой будет сохранить все параметры в отдельный конфигурационный файл, в котором и будут храниться все необходимые параметры. Это добавит удобства при использовании и может обезопасить систему. После соединяемся с БД и получаем курсор:
connect = pyodbc.connect(connect_str) cursor = connect.cursor() Если мы успешно подключились, то, используя это соединение, мы можем применить курсор для получения ответа на запрос:
cursor.execute('SELECT * FROM ') Теперь можно получить результат, вызвав методы fetchone() и fetchall(). Способы их использования мы рассмотрим чуть ниже.Так как не только базы данных от Microsoft поддерживают такой вид соединения, то пакет pyodbc можно использовать при работе и с другими базами данных, совместимыми с ODBC.
pypyodbc
Пакет pypyodbc можно назвать скриптом, написанным на Python. Интересно, что на самом деле pyodbc — это Python, завернутый в бэкэнд С++, в то время как pypyodbc уже является чистым кодом на Python. Чаще всего эти модули взаимозаменяемы. Единственное различие будет заключаться в импорте:
import pypyodbc SQLite в Python
В отличие от других баз данных SQL, которые мы будем рассматривать дальше, у Python’a уже есть встроенная поддержка для SQLite — компактной встраиваемой СУБД. Для этой БД API-модулем будет sqlite3. Поэтому для корректной работы достаточно добавить импортирование стандартной библиотеки и ничего заранее устанавливать не нужно:
import sqlite3 Подключение к базе данных
Далее обязательным этапом следует создание соединения:
connect = sqlite3.connect('database.sqlite') Здесь мы указываем путь до файла базы данных. Следующим шагом требуется создать объект курсора:
cursor = connect.cursor() Чтение из базы
Для чтения необходимо сделать следующее:
cursor.execute("SELECT FROM ") После вызова метода execute() мы уже пользуемся привычным синтаксисом SQL. Для получения ответа воспользуемся fetchall():
results = cursor.fetchall() Так мы получаем все строки результата сделанного запроса. Важно помнить, что после того, как мы получили ответ на запрос из курсора, чтобы получить этот результат еще раз, необходимо повторно выполнить запрос. Иначе вернется пустой результат (null).
После окончания всех требуемых операций, обязательно нужно закрыть наше соединение:
connect.close() Запись в базу
Аналогично чтению, для записи в БД нужно написать запрос к ней:
cursor.execute("INSERT INTO (id, name, surname, birthdate) VALUES (2, 'Petr', 'Ivanov', '2003-12-13') ") Однако, если мы не только читаем, но и вносим какие-либо изменения, обязательно нужно сохранить транзакцию:
connect.commit() Когда к базе установлено не одно соединение, а одно из них пытается как-то модифицировать данные, база данных SQLite блокируется до завершения или отмены текущей транзакции. Закончить транзакцию можно методом commit(), а отменить ее — методом rollback().
MySQL в Python
MySQL — это СУБД с открытым исходным кодом (open source). Ее можно подключить несколькими способами. Один из наиболее распространенных — это использование пакета MySQLdb, у которого существует несколько версий. Из-за наличия различных версий, часть из которых несовместима с конкретными версиями Python, может возникнуть путаница.
Поэтому рассмотрим подробно один конкретный пакет mysqlclient — ответвление MySQL-Python (как раз MySQLdb), которое предоставляет поддержание Python 3. Важно отметить, что нам понадобится MySQL или MySQL Client для его успешной установки:
pip install mysqlclient После этого пакет mysqlclient будет установлен. Теперь посмотрим, как работа с этим пакетом будет реализована в коде:
import MySQLdb Так мы подключаем сам пакет.
connect = MySQLdb.connect('localhost', 'username', 'password', 'table_name') Этой строчкой мы создаем соединение. Обязательно указываем сервер, куда подключаемся, логин и пароль для соединения, а также название таблицы, с которой будем осуществлять взаимодействие.
cursor = connect.cursor() cursor.execute("SELECT * FROM ") Курсор создан. Можно начинать выполнять конкретные запросы.
row = cursor.fetchone() Здесь мы извлекаем только одну строку из всего результата и дальше можем обрабатывать ее так, как требует решаемая задача.
connect.close() Не забываем закрыть связь с БД.
PostgreSQL в Python
PostgresSQL является еще одной БД, распространяемой как свободное программное обеспечение, широко используемое в разработке. У Python существует несколько пакетов, которые поддерживают этот бэкэнд, но мы изучим работу с одним из них — Psycopg. Аналогично другим пакетам для начала необходимо его установить:
pip install psycopg2 Уже в коде будет необходимо импортировать этот пакет:
import psycopg2 После этого аналогично работе с MySQL мы передаем в переменную connect соединение:
connect = psycopg2.connect(host='hostname', user='username', password='password', dbname='database') Что делать дальше нам уже известно — создавать курсор:
cursor = connect.cursor() Далее посмотрим на этот фрагмент кода:
cursor.execute("SELECT * FROM ") row = cursor.fetchone() cursor.close() connect.close() С помощью метода execute() мы делаем запрос к БД. После этого получаем одну строку результата с помощью fetchone(). После чего разрываем подключение к базе данных, закрывая и курсор, и соединение.
За исключением нескольких особенностей, работа с Psycopg практически не отличается от работы с другими пакетами. Мы помним, что и mysqlclient, и Psycopg следуют стандартному API, которому, на самом деле, следует большая часть пакетов. Именно поэтому код взаимодействия с разными БД практически не отличается между собой. Так мы можем подтвердить, что несмотря на существующие различия, работа с разными пакетами сводится к нескольким одинаковым командам.
Расширенные методы курсора
Теперь рассмотрим особые возможности курсора, которые могут помочь при взаимодействии с базой данных.
Разбивка запроса на строки
Часто приходится писать длинные SQL-запросы, состоящие из множества строк. К сожалению, при написании запроса в одну строку теряется читабельность. Поэтому в коде удобно разбить такой запрос на несколько строчек, заключив его в тройные кавычки:
cursor.execute(""" SELECT surname FROM ORDER BY surname LIMIT 4 """) Объединение запросов к БД
Метод execute() позволяет выполнить за раз лишь один запрос (если написать сразу несколько запросов, разделив их точкой с запятой или другим разделителем, то мы получим ошибку). Однако чаще всего в разработке требуется обратиться к БД далеко не один раз. Конечно, можно просто вызвать этот метод несколько раз подряд:
cursor.execute("INSERT INTO (id, name, surname, birthdate) VALUES (3, 'Stepan', 'Platonov', '2010-01-01') ") cursor.execute("INSERT INTO (id, name, surname, birthdate) VALUES (4, 'Platon', 'Stepanov', '2010-02-02') ") Но можно воспользоваться более изящным решением и вызвать executescript():
cursor.executescript(""" INSERT INTO (id, name, surname, birthdate) VALUES (3, 'Stepan', 'Platonov', '2010-01-01'); INSERT INTO (id, name, surname, birthdate) VALUES (4, 'Platon', 'Stepanov', '2010-02-02'); """) Также этот метод может помочь в том случае, если мы сохранили тело запроса в файл или отдельную переменную.
Подстановка значения в запрос
В процессе написания кода, в котором мы тесно взаимодействуем с БД, может возникнуть ситуация, когда необходимо подставить конкретное значение в запрос. Тогда поможет применение второго аргумента в методе execute():
cursor.execute("SELECT surname FROM ORDER BY surname LIMIT ?", ('2')) Или есть еще один способ:
cursor.execute("SELECT surname FROM ORDER BY surname LIMIT :limit", ) Важно! В PostgreSQL и в MySQL для подстановки вместо знака ‘?’ нужно писать %s.
Также стоит отметить, что этот способ не подойдет для замены названия таблицы.
Множественная вставка строк
Для вставки нескольких строк воспользуемся методом executemany(), в который в независимости от количества значений необходимо передавать список кортежей:
new_users = [ ('User',), ('User-2',), ('User-3',), ] В этом примере мы как раз используем кортеж (поэтому после имени пользователя идет запятая), несмотря на то что передаем только одно значение. После этого вставляем полученный список:
cursor.executemany("INSERT INTO Users VALUES (Null, ?);", new_users) Таким образом, проходясь по списку, мы вставляем сразу несколько строк.
Повышение устойчивости кода
Сейчас в любом проекте требуется правильно обрабатывать и отлавливать возможные ошибки во время исполнения программы. Особенно это может быть критично при записи информации в базу данных. Поэтому полезно оборачивать обращение к БД в конструкцию «try-except-else»:
try: cursor.execute(query) result = cursor.fetchall() except sqlite3.DatabaseError as error: print("Error: ", error) else: connect.commit() Подробнее рассмотрим этот фрагмент. В try мы передаем инструкцию для SQL, после чего записываем в result весь результат. При возникновении ошибки мы используем встроенный в sqlite3 объект ошибок и печатаем его в консоль. В противном случае, если же все отработало корректно, мы сохраняем изменения. Такой подход может сильно упростить исправление ошибок в ходе разработки.
Создание таблиц
Перед нами стоит простая задача: создать таблицу. На примере этой задачи мы окончательно разберемся в принципе работы с БД в Python. Ниже посмотрим на функцию, задача которой будет осуществлять работу с такими БД, как SQLite и MySQL (для PostgreSQL будет незначительно отличаться несколькими строчками):
def execute_query(connect, query): cursor = connect.cursor() try: cursor.execute(query) connect.commit() print("Success!") except Error as err: print("Error: ", err) В аргументы execute_query() мы передаем соединение и сам запрос. Дальше с помощью курсора мы исполняем запрос и сохраняем транзакцию. Также сразу обрабатываем ошибки, которые могут возникнуть.
Выше мы уже подробно изучили, что делает каждая строчка кода, здесь же все объединено в одну функцию для удобства написания кода. Теперь осталось написать сам запрос, который будет создавать новую таблицу:
create_table_query = """ CREATE TABLE customers ( id INTEGER PRIMARY KEY AUTO_INCREMENT, name TEXT NOT NULL, surname TEXT, age INTEGER ); В этом запросе мы создаем таблицу клиентов, у каждого из которых будет свой id (генерирующийся самостоятельно), имя, фамилия и возраст. Осталось вызвать execute_query():
execute_query(connect, create_table_query) Все, новая таблица будет создана.
Работа с записями в БД с помощью Python
Теперь мы уже можем подвести итог о принципе работы Python с базами данных. Вне зависимости от того, какую цель мы преследуем и какие действия мы хотим сделать с таблицей, все сводится к отправлению запросов на SQL, которые мы передаем в курсор. Далее мы кратко рассмотрим примеры, связанные с различными операциями с таблицами.
Мы уже знаем, что в зависимости от конкретной задачи будет изменяться только SQL-запрос. Поэтому ниже посмотрим на соответствующие запросы для разных подзадач.
Добавление записей
add_customers_query = """ INSERT INTO customers (name, surname, age) VALUES ('Anne', 'Samoilova', 26), ('Petr', 'Ogurechkin', 44), ('Samanta', 'Ivanova', 31); """ Внутри запроса мы добавляем в таблицу customers трех человек, для каждого указывая имя, фамилию и возраст. Осталось передать этот запрос в execute_query(), как мы делали выше.
Обновление данных
update_customer_query = """ UPDATE customers SET name = 'Pavel' WHERE >В этом запросе мы изменяем имя клиенту с id равном 2. При передаче этого запроса в функцию мы успешно обновим информацию в таблице.
Чтение данных
select_customers_query = "SELECT * FROM customers" Выполняя этот запрос, мы получим всех клиентов, информация о ком хранится в таблице.
Удаление данных
delete_customer_query = "DELETE FROM customers WHERE >А теперь удалим клиента с id равным 1.
Дополнительные возможности SQLite
SQLite широко используется и легко поддерживается большинством клиентов SQL. Рассмотрим некоторые интересные возможности SQLite.
Подключение к БД из клиента SQL
Если мы запускаем Python на локальном компьютере, то с помощью какого-нибудь клиента SQL можно напрямую подключиться к файлу БД. Одним из таких клиентов является приложение DBeaver, позволяющий управлять базой данных.
Алгоритм работы как и раньше: сначала нужно создаем новое соединение: правой кнопкой мыши по названию БД (при установке DBeaver предлагает создать тестовую базу данных, чтобы ознакомиться с функционалом приложения) → Создать → Соединение:

После выбора подходящей нам базы данных SQLite, мы нажимаем Далее и в специальном окне настраиваем соединение нужным нам образом:
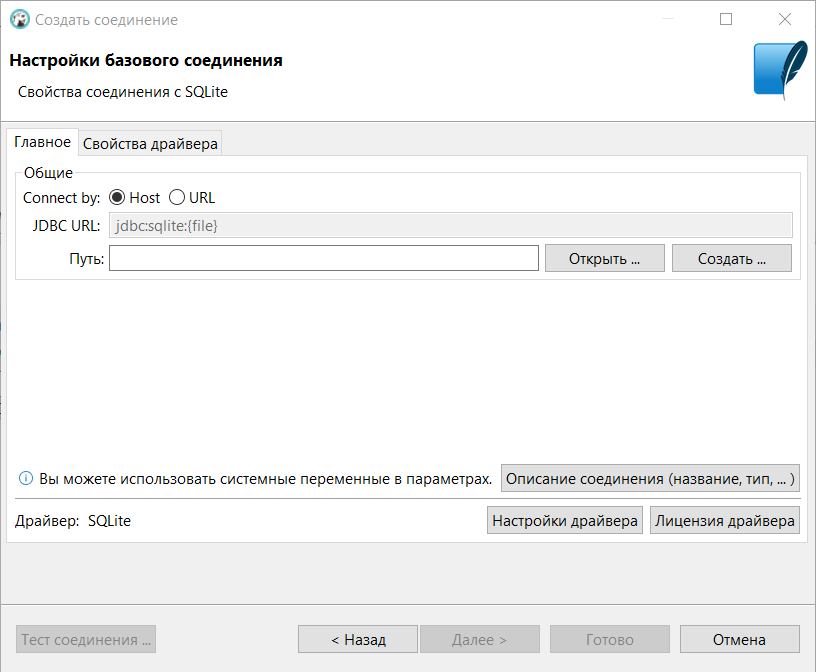
После завершения всех настроек и указания верных путей мы уже можем сделать любой SQL-запрос.
Интеграция с фреймворком Pandas
На самом деле в Python есть библиотека, специально предназначенная для обработки и анализа структурированных данных. Библиотека Pandas — это гибкий и мощный инструмент, широко применяемый в анализе данных.
В фреймворке Pandas есть множество специальных структур и операций для эффективной работы с данными. Основополагающей частью Pandas является фрейм данных (от DataFrame) — структура, представляющая собой двумерный набор данных, хранящихся в табличной форме. Но также фрейм данных непрерывно интегрируется с SQLite.
Как мы уже привыкли, сначала нужно импортировать библиотеку:
import pandas as pd Для демонстрации этого сначала определим какой-нибудь фрейм данных:
df_films = pd.DataFrame(< 'film_id': [1, 2, 3, 4, 5, 6], 'year': [1999, 2017, 2014, 1985, 2002, 2001], 'name': ['The Green Mile', 'Coco', 'Interstellar', 'Back to the Future', 'The Lord of the Rings: The Two Towers', 'Sen to Chihiro no kamikakushi'] >) 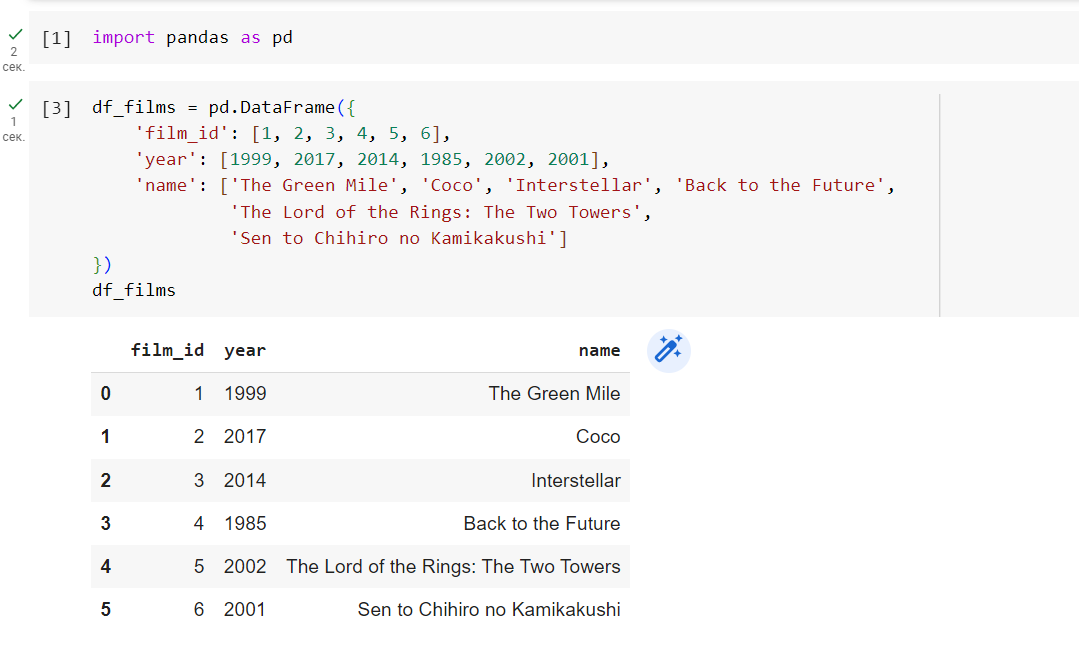
Также мы могли прочитать дата фрейм из файла с расширением csv:
df_films = pd.read_csv(filepath_or_buffer = "file_with_films.csv", sep = ';') Теперь у нас есть небольшой фрейм данных, посвященный фильмам. У фрейма есть метод to_sql(), позволяющий сохранить его в БД. Воспользуемся им:
df_films.to_sql('Films', connection) Теперь у нас есть таблица в нашей БД, соединение с которой мы передали в аргументы метода. Длина столбцов и типы данных будут сгенерированы автоматически. Но если появится такая необходимость, конечно, их можно будет изменить.
Если же мы хотим написать какой-то SQL-запрос к таблице, то это также легко делается с помощью метода read_sql():
df = pd.read_sql(''' SELECT * FROM Films ''', connection) Можем сделать вывод, что с помощью библиотеки Pandas можно очень просто реализовать работу с реляционной базой данных SQLite.
Заключение
Мы тесно поработали с SQL, научились писать запросы, используя специальные операторы и теперь умеем получать самую разную информацию из таблиц в зависимости от поставленной задачи.
Также в этой статье мы ознакомились с разнообразными пакетами и библиотеками языка Python, позволяющими реализовать и упростить неочевидное взаимодействие с базами данных SQL. Python позволяет без труда совершать множество операций, начиная от создания таблиц и заканчивая модификацией строк в уже существующих записях.
Зарегистрируйтесь в панели управления
И уже через пару минут сможете арендовать сервер, развернуть базы данных или обеспечить быструю доставку контента.
Как работать с базами данных
27 сентября 2023
Скопировано
SQL (от англ. Structured Query Language) — это структурированный язык запросов, созданный для того, чтобы получать из базы данных необходимую информацию. Если описать схему работы SQL простыми словами, то специалист формирует запрос и направляет его в базу. Та в свою очередь обрабатывает эту информацию, «понимает», что именно нужно специалисту, и отправляет ответ.

Освойте профессию «Аналитик данных»
Данные хранятся в виде таблиц, они структурированы и разложены по строкам и столбцам, чтобы ими легче было оперировать. Такой способ хранения информации называют реляционными базами данных (от англ. relation — «отношения»). Название указывает на то, что объекты в такой базе связаны определенными отношениями.
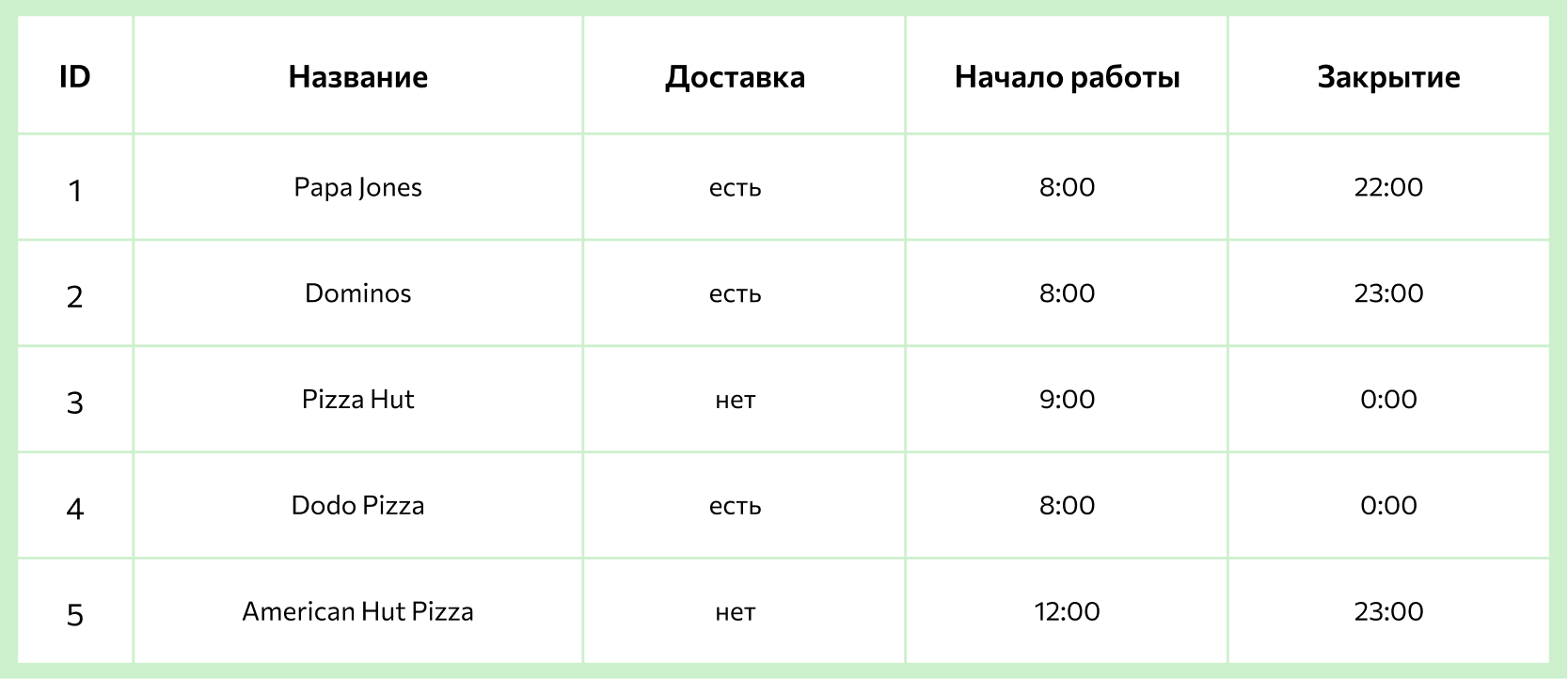
Например, у маркетолога есть база, в которой собрана информация обо всех пиццериях в городе: названия, ассортимент, цены, график работы и прочее. Во время анализа конкурентов он решил выяснить, сколько пиццерий готовят пиццу с ананасами и оформляют доставку после 23:00. Для того чтобы получить такой список из базы, достаточно написать грамотный SQL-запрос.
Профессия / 12 месяцев
Аналитик данных
Находите закономерности и делайте выводы, которые помогут бизнесу

Для чего нужен SQL
SQL — это не язык программирования, поэтому написать приложение или сайт с его помощью не получится, но при этом внутренняя работа сайта (backend) невозможна без запросов. Поиск информации в Google — это тоже модель использования SQL. Пользователь задает параметры, которые его интересуют, и отправляет запрос на сервер; затем происходит магия и в поисковой выдаче появляются результаты, соответствующие именно этому запросу.
SQL используют разные виды специалистов:
- Аналитикиипродуктовые маркетологи. Знание SQL помогает этим специалистам не зависеть от программистов, а самостоятельно получать и обрабатывать данные.
- Разработчикиитестировщики. С помощью SQL они могут самостоятельно проектировать базы для быстрой и надежной работы с данными, улучшать с их помощью сайты и приложения.
- Руководители и менеджеры. SQL позволит специалистам на руководящих постах самостоятельно обращаться к базам, контролировать работу компании и в реальном времени получать данные о положении дел.
Читайте также Востребованные IT-профессии 2023 года: на кого учиться онлайн
Как работают запросы
Чтобы разобраться, как именно работает магия запроса, давайте представим его путь от пользователя до нужных ему данных:
Пользователь → Клиент → Запрос → Система управления → База данных → Таблица с базами данных
Данные для работы с SQL хранятся в таблицах. Как именно они устроены — разберемся ниже; пока же просто представим их. На пути от пользователя к таблице находится несколько посредников:
- Клиент — способ введения запроса. В случае с Google, например, клиентом будет поисковая строка браузера, в которую пользователь вводит сформулированный запрос.
- Система управления базами данных (СУБД) — комплекс программ, которые позволяют управлять данными. Эта система помогает таблицам понять, чего хочет пользователь, а пользователю — что ему отвечают таблицы.
- База данных — система хранения таблиц, в которой они связаны между собой. База данных сама по себе не умеет манипулировать информацией — это просто хранилище, где у каждого объекта есть свое место.

Станьте аналитиком данных и получите востребованную специальность
Что такое база данных в SQL
SQL-запросы обращаются к данным в виде таблиц, то есть к реляционным базам данных. Упрощенный вариант такой базы — это таблицы Excel, в которых информация также упорядочена в столбцы и строки.
Основные понятия реляционной модели:
1. Отношение — это сама таблица, она двумерная и состоит из столбцов и строк.
2. Атрибут — столбец в таблице, который содержит один конкретный параметр: название, тип, дату, стоимость или другую характеристику.
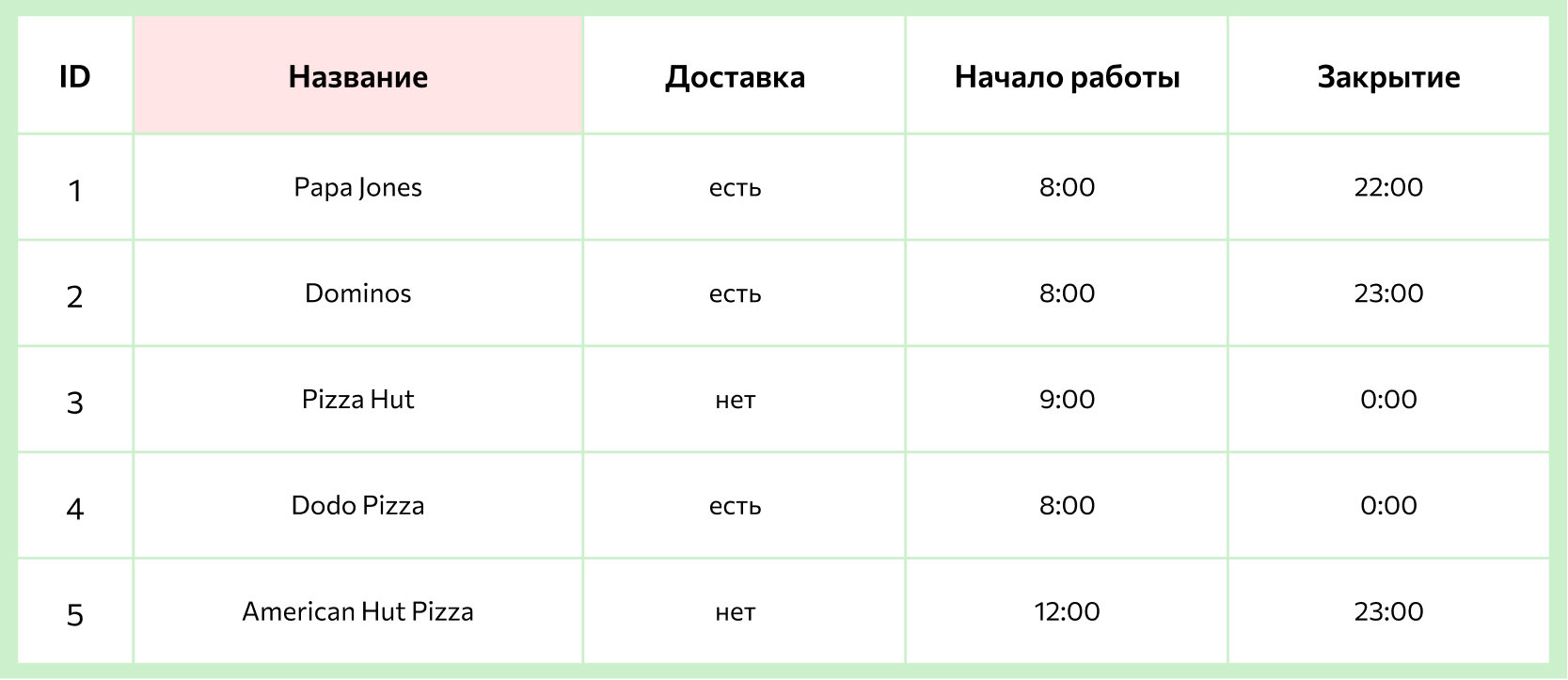
3. Домен — это допустимые значения для каждого атрибута. Например, в столбце «Имя» или «Название» значения должны представлять собой набор буквенных символов, но они не могут начинаться с «ь» или «ъ» и не могут быть записаны числами.
4. Кортеж (строка или запись) — это табличная строка с порядковым номером, в которой содержится информация об одном конкретном объекте.
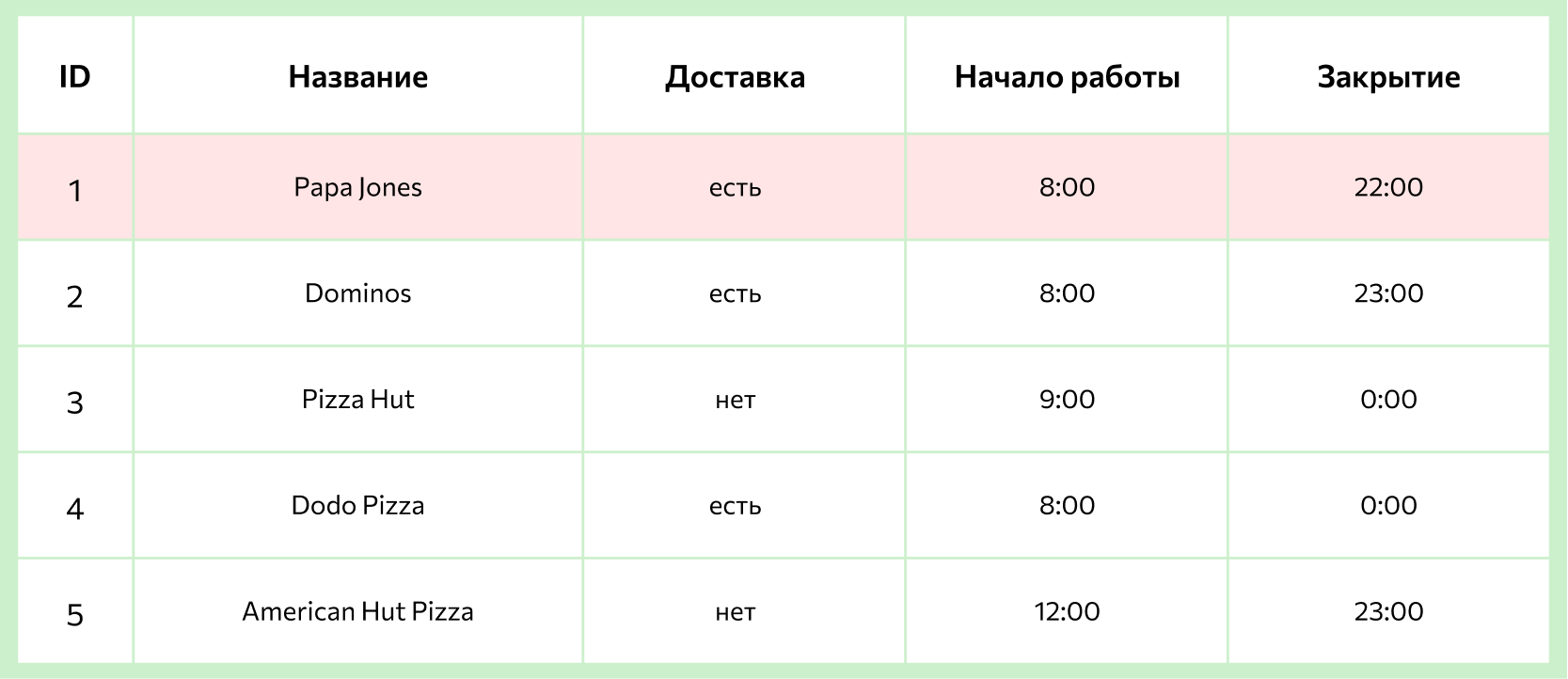
5. Значение — элемент таблицы, который находится на пересечении столбцов и строк.
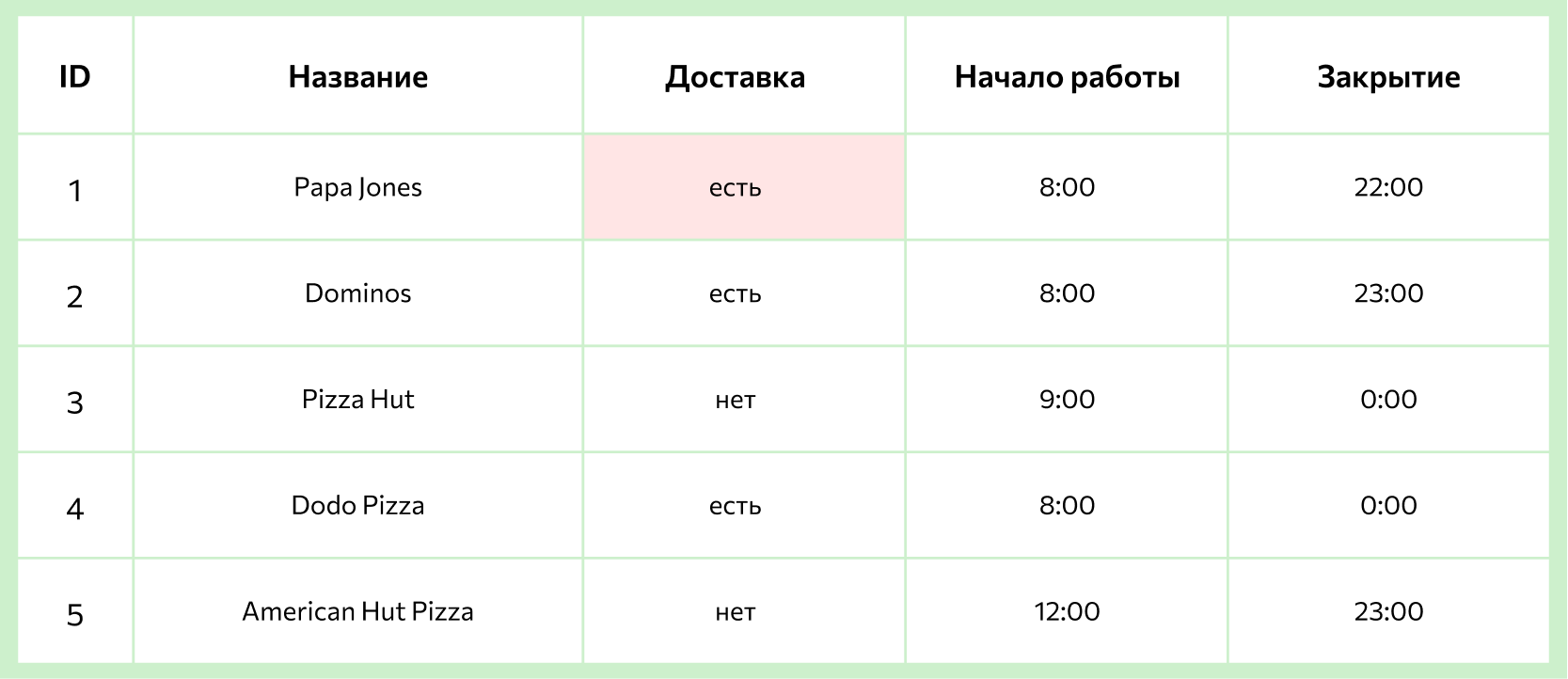
6. Ключ — это самый важный столбец в таблице, за счет этих значений и происходит взаимодействие в реляционной базе данных, он связывает таблицы между собой.
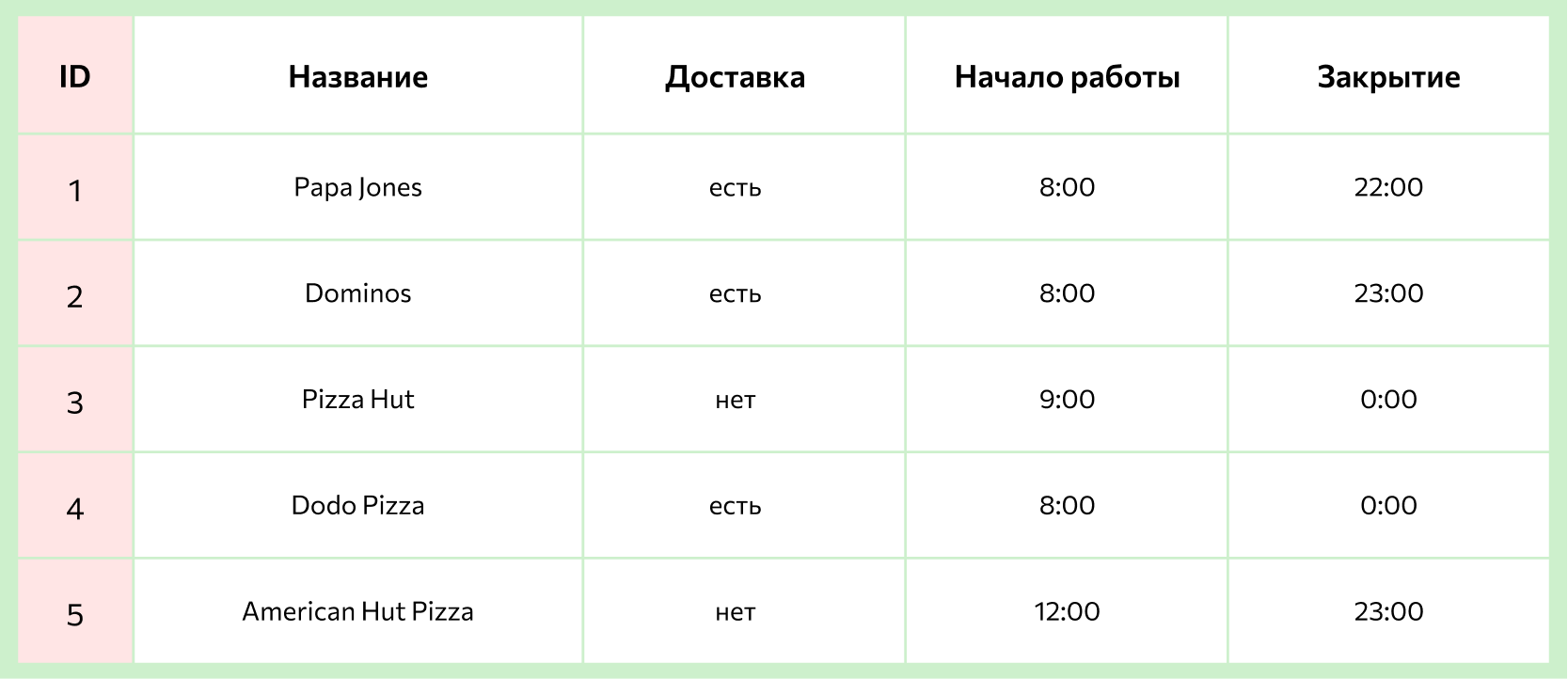
Ключи бывают нескольких видов:
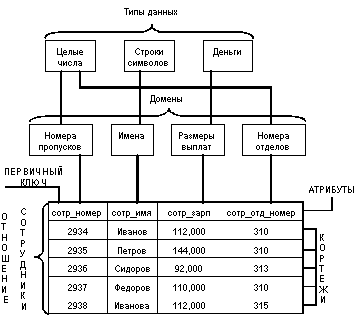
- Первичный ключ — идентификатор, такой как индекс или артикул.
- Потенциальный ключ — другое уникальное значение, которое может служить идентификатором.
- Внешний ключ — столбец-ссылка, используется для объединения двух таблиц, каждое значение внешнего ключа обязательно соответствует первичному ключу в другой таблице.
Например, для решения задачи — выбрать все пиццерии, которые смогут доставить пиццу с ананасами после 23:00, — кроме основной таблицы с графиками работы понадобятся также таблицы с ассортиментом каждого заведения, а также таблицы с составом каждой пиццы (чтобы понять, есть ли в ней ананасы). Все эти таблицы будут связаны между собой с помощью ключей.


Станьте дата-сайентистом: изучите науку о данных с преподавателями Сеченовского университета и практикуйтесь на реальных кейсах
SQL-операторы
Работать с данными помогают операторы — определенные слова или символы, которые используются для выполнения конкретной операции — например, для выбора из множества по конкретному параметру. Если нам нужно из всех видов пиццы отсортировать те, в которых есть пармезан, — нужно использовать оператор SELECT (выбор в соответствии с условием).
Операторы в SQL делятся на несколько групп в соответствии с задачами, которые они решают.
DDL (Data Definition Language) — операторы определения данных. Они работают с объектами, то есть с целыми таблицами. Если базу нужно дополнить таблицей с новыми данными или, наоборот, убрать одну из таблиц с ошибочными данными — используется этот набор операторов.
- CREATE — создание объекта в базе данных
- ALTER — изменение объекта
- DROP — удаление объекта
DML (Data Manipulation Language) — операторы манипуляции данными. Эти операторы уже работают с содержимым таблиц — строками, атрибутами и значениями. С их помощью можно вносить изменения в конкретное значение. Например, заменить поле в колонке «Фамилия» в строке с данными сотрудницы компании посте того, как она вышла замуж. Или удалить строку с данными уволенного сотрудника.
- SELECT — выбор данных в соответствии с условием
- INSERT — добавление новых данных
- UPDATE — изменение существующих данных
- DELETE — удаление данных
DCL (Data Control Language) — оператор определения доступа к данным. Он определяет, кто из пользователей может отправлять запросы к базе, менять объекты и значения. Например, можно отозвать доступ у сотрудника, перешедшего в другой отдел, а также открыть доступ к базе новому маркетологу или разработчику.
- GRANT — предоставление доступа к объекту
- REVOKE — отзыв ранее выданного разрешения
- DENY — запрет, который является приоритетным над разрешением
TCL (Transaction Control Language) — язык управления транзакциями. Транзакции — это набор команд, которые выполняются поочередно. Если все команды выполнены, транзакция считается успешной, а если где-то произошла ошибка — транзакция откатывается назад, отменяя все выполненные команды. Наглядный пример такой транзакции — оплата онлайн, когда банк просит сначала ввести сумму и получателя, затем проверить и подтвердить операцию, а после ввести одноразовый код. На каждом из этих этапов оплату можно отменить и транзакция откатится назад.
- BEGIN TRANSACTION — обозначение начала транзакции
- COMMIT TRANSACTION — изменение команд внутри транзакции
- ROLLBACK TRANSACTION — откат транзакции
- SAVE TRANSACTION — указание промежуточной точки сохранения внутри транзакции
Виды СУБД
Сами по себе таблицы или база данных не способны выполнять операции, а в СУБД можно создавать новые таблицы, удалять ненужные данные, настраивать ключи и обрабатывать запросы. Основные задачи СУБД:
- поддержка языков баз данных;
- непосредственное управление данными;
- управление буферами оперативной памяти;
- управление транзакциями;
- резервное копирование и восстановление после сбоев.
Существуют разные виды таких систем, которые разрабатывает и техногиганты, вроде Google, Microsoft и Amazon, и более нишевые студии. Разработчики стремятся сделать свой продукт лучше, чтобы их система быстрее и качественнее других обрабатывала данные. Из-за этого появились разные виды языка SQL — так называемые SQL-диалекты. У каждой СУБД диалект имеет что-то общее со всеми, а также свои особенности, которые не будут работать в другой системе.
СУБД могут быть коммерческими или иметь открытый код. Системы управления с открытым кодом можно бесплатно использовать в проектах, а также дополнять их документацию и совершенствовать процесс работы с системой. Коммерческие СУБД имеют платный доступ к полным версиям — как правило, такие используют крупные корпорации.
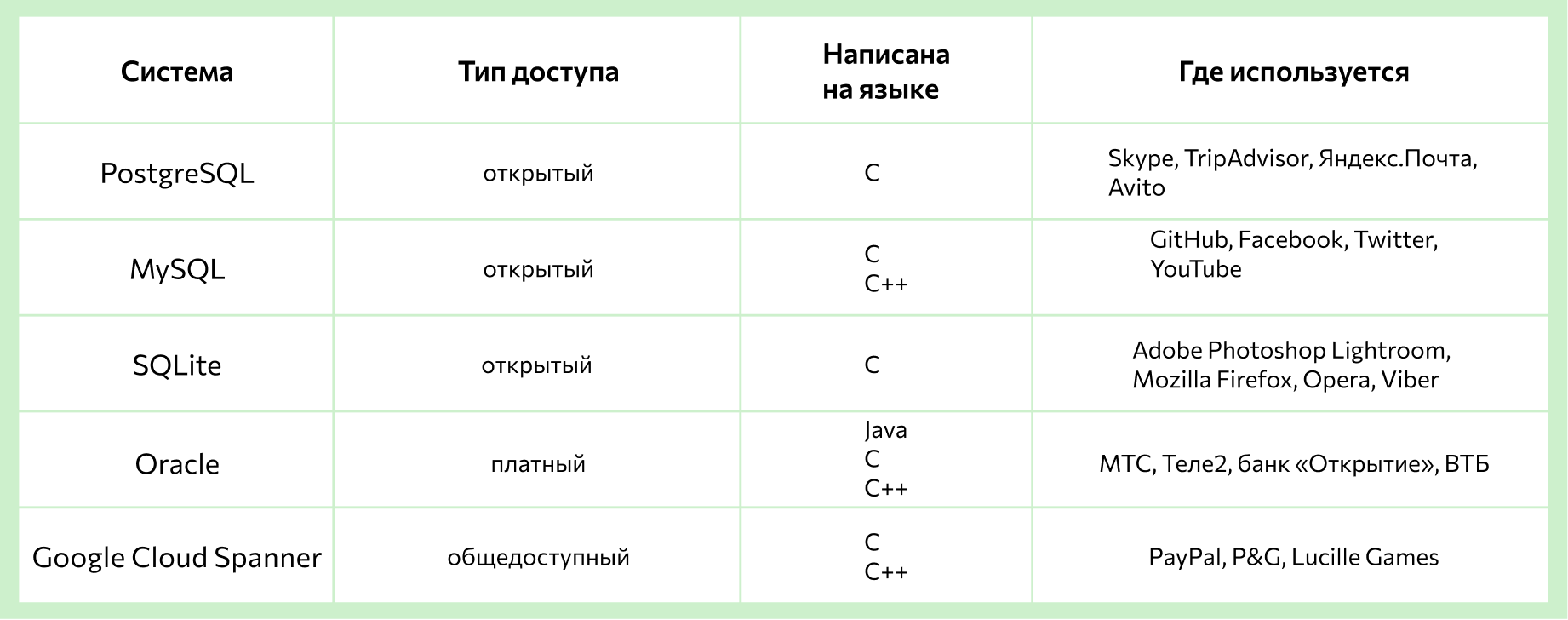
- PostgreSQL — это объектно-ориентированная система, то есть она обрабатывает данные как абстрактные объекты. Каждый объект, в отличие от простых табличных значений, может иметь собственные характеристики и уникальные методы взаимодействия с другими объектами. Это позволяет PostgreSQL обрабатывать более сложные структуры данных и выполнять более сложные процедуры. Например, Яндекс.Почта в свое время перешла на эту систему, чтобы поддерживать стабильное соединение десятков тысяч пользователей к одной базе.
- MySQL — простая в изучении и функциональная система, которая работает с сайтами и веб-приложениями. Чаще всего используется в системах управления контентом сайтов (CMS), на сайтах с возможностью регистрации пользователей, в корпоративных системах CRM, в планировщиках, чатах и форумах. MySQL считается одним из самых безопасных и высокоскоростных решений, которое существует на рынке.
- SQLite — это облегченная встраиваемая версия СУБД. В ней нет возможности поделиться правами доступа, как во многих других системах, но благодаря своему устройству эта система быстрая и мощная. SQLite подходит для обработки запросов на сайтах с низким и средним трафиком, а также в однопользовательских мобильных приложениях и играх. Преимущество такой системы — файловая структура, то есть база в SQLite состоит из одного файла, поэтому ее очень легко переносить.
- Oracle — одна из первых СУБД, которая появилась еще в 1977 году и развивается до сих пор. Это кроссплатформенная система, которая может работать на Windows, Linux, MacOS, мобильных и других ОС. Система используется в крупных коммерческих проектах. Например, в России с Oracle сотрудничают операторы МТС и Теле2, банк «Открытие» и ВТБ.
- Google Cloud Spanner — это облачная система управления данными, которую Google разработал для управления собственными сервисами, например AdWords и Google Play. В 2017 году систему сделали общедоступной. Cloud Spanner относят к категории NewSQL — это системы, которые совмещают в себе преимущества реляционных и нереляционных СУБД.
Как начать работу с SQL
Для начала работы с SQL достаточно разбираться в основах Excel, чтобы понимать принцип работы запросов, а также иметь базовый уровень английского на уровне A1-A2. Эти навыки необходимы, чтобы понимать синтаксис SQL:
- SELECT — выбери данные
- FROM — вот отсюда
- JOIN — добавь еще эти таблицы
- WHERE — при таком условии
- GROUP BY — сгруппируй данные по этому признаку
- ORDER BY — отсортируй данные по этому признаку
- LIMIT — нужно такое количество результатов
- ; — конец предложения
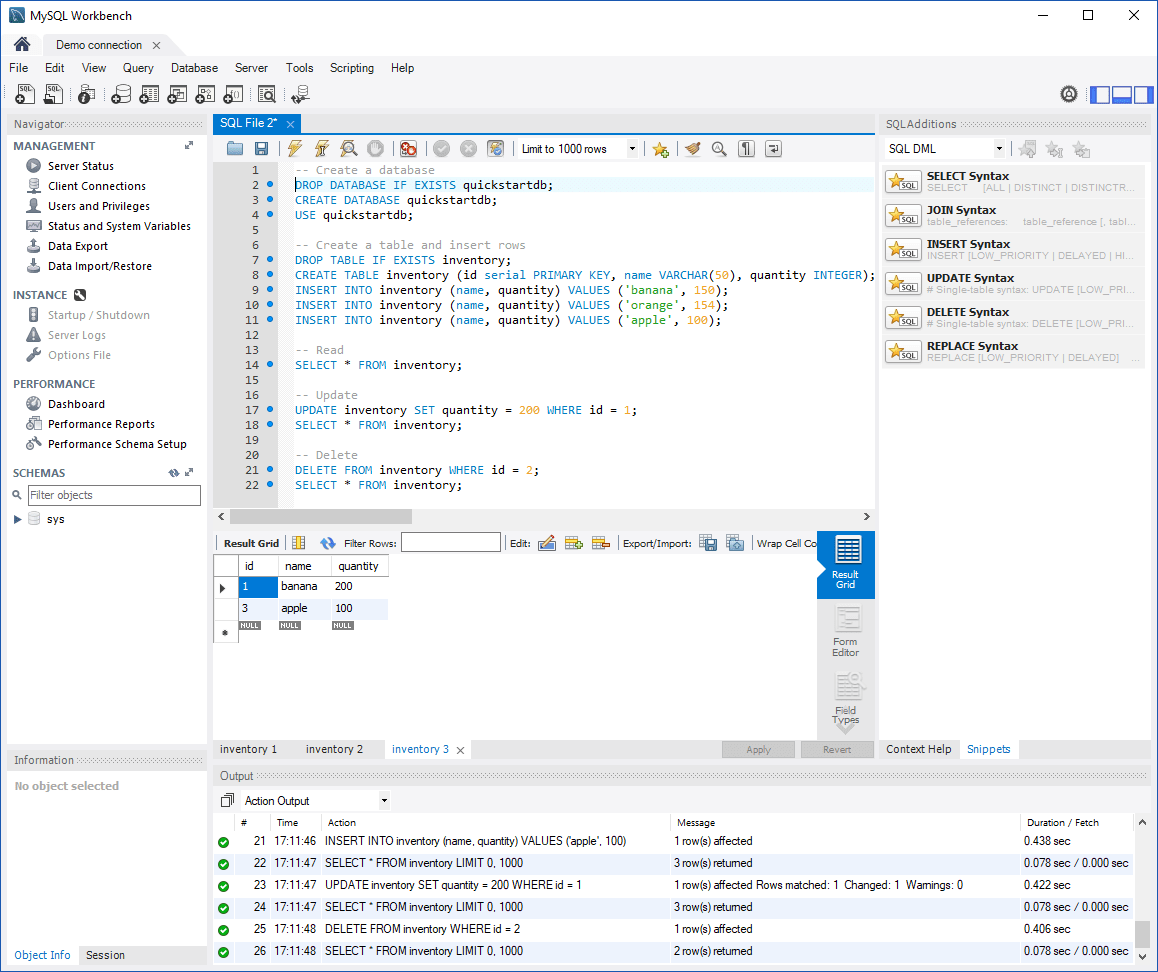
Системы для работы с SQL имеют схожую структуру: есть редактор запросов, результат запросов и список таблиц, которые используются для обработки.
Самостоятельно начать изучение SQL можно с просмотра уроков на YouTube и чтения тематических статей в профильных медиа. Для более системного усвоения информации и экономии времени, потраченного на обучение, лучше записаться на курсы к опытным преподавателям, где вы сразу попадете в профессиональное сообщество и будете получать поддержку менторов.
Аналитик данных
Аналитики влияют на рост бизнеса. Они выясняют, какой товар и в какое время больше покупают. Считают юнит-экономику. Оценивают окупаемость рекламной кампании. Поэтому компании ищут и переманивают таких специалистов.
Начинаем работать с базами данных SQL
Большинство веб-приложений хранят некоторые данные, необходимые для работы, на сервере. Например, движок блога хранит все записи блога, причём каждая запись в этом случае представляет собой текст, заголовок, дату создания и, возможно, целый набор дополнительных данных, необходимых данному блоговому движку для отображения записи блога на сайте.
Сервер онлайн-игры, скорее всего, будет сохранять информацию об игроках и их достижениях.
Онлайн-система учёта личных расходов будет хранить на сервере стоимость сделанных покупок и движения средств на счетах.
Все эти примеры объединяет одно: необходимость хранения данных на стороне сервера. Причём, данные в разных случаях имеют различную структуру, которая зависит от конкретного веб-приложения. Для решения задачи хранения данных на сервере в подавляющем большинстве случаев используются базы данных. Система, реализующая механизм работы с базами данных, называется Система Управления Базами Данных (СУБД, или DBMS, database management system). Для простоты пока будем рассматривать только так называемые реляционные базы данных.
Структура базы данных
Каждая база данных состоит из набора таблиц. Таблица — это набор записей, состоящих из некоторого набора полей. Все записи одной таблицы имеют одинаковый набор полей, задаваемый этой таблицей. Разные таблицы могут задавать разные наборы полей. У таблиц, как и у каждого поля в этих таблицах, есть свои имена. Имена таблиц уникальны в пределах одной базы данных, а имена полей уникальны в пределах таблицы, где эти поля находятся. Каждое поле таблицы имеет свой тип: например, целое число, текстовая строка, дата, и так далее.
Вот пример содержимого таблицы users, состоящей из трёх полей (id, login, password) и трёх записей:
| users | ||
| id | login | password |
| 1 | admin | 123456 |
| 2 | alex | alex123 |
| 3 | marfa | 409ghr |
По сути, каждая таблица предназначена для описания объектов некоторого типа, а каждая запись в таблице — описание конкретного объекта. В примере выше каждая запись таблицы описывает пользователя: его номер, а также логин и пароль.
Механизм СУБД позволяет создавать и удалять таблицы. Содержимое таблиц также можно изменять: можно добавлять новые записи, изменять уже существующие, а также удалять записи из таблиц. Данные, хранящиеся в таблицах, можно извлекать при необходимости. В обязанности СУБД входит обеспечение максимальной скорости и производительности при операциях с таблицами и их содержимым.
Работа с базами данных из программ
Для любых действий с базой данных, как правило, используется специальный стандартный язык, который называется SQL (structured query language, язык структурированных запросов). Это достсточно простой язык, который позволяет выполнять все необходимые действия над базой данных, а это:
- создание и удаление таблиц, а также изменение структуры таблиц;
- добавление и изменение записей в таблицах, удаление записей;
- выборка записей из таблиц.
Простой пример с таблицей users
Чтобы проиллюстрировать изложенное выше, предлагаю проделать это своими руками. Для этого нам понадобится база данных и инструмент, с помощью которого можно будет отправлять в базу запросы на языке SQL и наблюдать результат.
Для начала скачаем и установим: MySQL server — бесплатная версия самого популярного сервера баз данных, MySQL Workbench — инструмент для работы с базами данных. MySQL Workbench, кроме SQL-запросов, позволяет работать с базами данных и через графические представления: отображается структура таблиц, свойства полей и многое другое.
Когда сервер СУБД MySQL запущен и MySQL Workbench открыт, можно приступить к экспериментам. Для этого надо подключиться к базе данных по имени test, которая создаётся при установке сервера MySQL. Далее, для создания таблицы users со структурой, как приведено выше, будет достаточно такого SQL-запроса:
CREATE TABLE users ( id INTEGER NOT NULL PRIMARY KEY AUTO_INCREMENT, name VARCHAR(20), password VARCHAR(60) )
Добавление записей в созданную таблицу выглядит так:
INSERT INTO users (name, password) VALUES ('admin', '123456'); INSERT INTO users (name, password) VALUES ('alex', 'alex123'); INSERT INTO users (name, password) VALUES ('marfa', '409ghr');
Теперь, чтобы извлечь из таблицы ранее сохраненные данные, можно выполнить, например, такой запрос:
SELECT * FROM users WHERE name='alex'
на что сервер вернёт данные из таблицы:
'2', 'alex', 'alex123'
Более глубоко изучить возможности SQL Вы сможете в дальнейшем. Есть множество ресурсов, предоставляющих полное справочное руководство по языку SQL. В частности, справочник на сайте MySQL (правда, на английском языке) содержит наиболее полное описание языка, используемого в сервере MySQL.