Парсить картинки с jsoup сайта

Парсить данные одного сайта со стороны клиента со страницы другого сайта
Есть 2 сайта. 1 — не мой 2 — мой. Мне нужно сделать следующее : Как только пользователь.
Парсинг сайта jsoup
Доброго времени суток. Есть сайт с проксями. Нужно спарсить прокси в таком виде: proxy:port.

Jsoup парсинг сайта
Помогите пожалуйста. Пытаюсь получить названия книг с сайта livelib. Но он ничего не парсит. Все.
Парсинг сайта Jsoup
Всем привет. Изучаю Java, поставил перед собой задачу спарсить сайт. Немного разобрался с.
87844 / 49110 / 22898
Регистрация: 17.06.2006
Сообщений: 92,604
Помогаю со студенческими работами здесь
Jsoup Получить таймер с сайта
Привет дорогой друг если ты читаешь это значит я уже устал искать ответ и решил задать вопрос на.
Парсинг данных с сайта с использованием jsoup
Доброго времени суток, делаю парсинг новостей с сайта в приложение. Смысл такой, на 1 активность.
Jsoup Парсинг сайта в таблицу (GridView)!
Здравствуйте! Подскажите новичку почему этот код на ListView работает, а на GridView приложение.
Дождаться полной загрузки сайта jsoup
Имеется сайт для парсинга и библиотека jsoup, проблема в том, что данные на сайте появляются не.
Или воспользуйтесь поиском по форуму:
Как парсить данные с сайта java
Для парсинга данных с веб-сайта в Java можно использовать библиотеку Jsoup .
- Добавьте зависимость в файл build.gradle :
dependencies implementation 'org.jsoup:jsoup:1.14.3' > - Создайте экземпляр класса Document , передав в качестве параметра URL адрес страницы:
import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import java.io.IOException; public class Main public static void main(String[] args) throws IOException Document doc = Jsoup.connect("https://www.example.com/").get(); System.out.println(doc.title()); > > - Используйте методы класса Document для получения нужных элементов страницы, например:
// Получить все ссылки на странице Elements links = doc.select("a[href]"); for (Element link : links) System.out.println(link.attr("href")); > // Получить текст заголовка страницы String title = doc.title(); System.out.println(title); Пример выше показывает, как получить все ссылки на странице и текст заголовка страницы. С помощью Jsoup вы также можете извлекать другие элементы страницы, такие как изображения, таблицы, формы и т. д.
Парсинг фотографий с сайта cian.ru с помощью Selenium
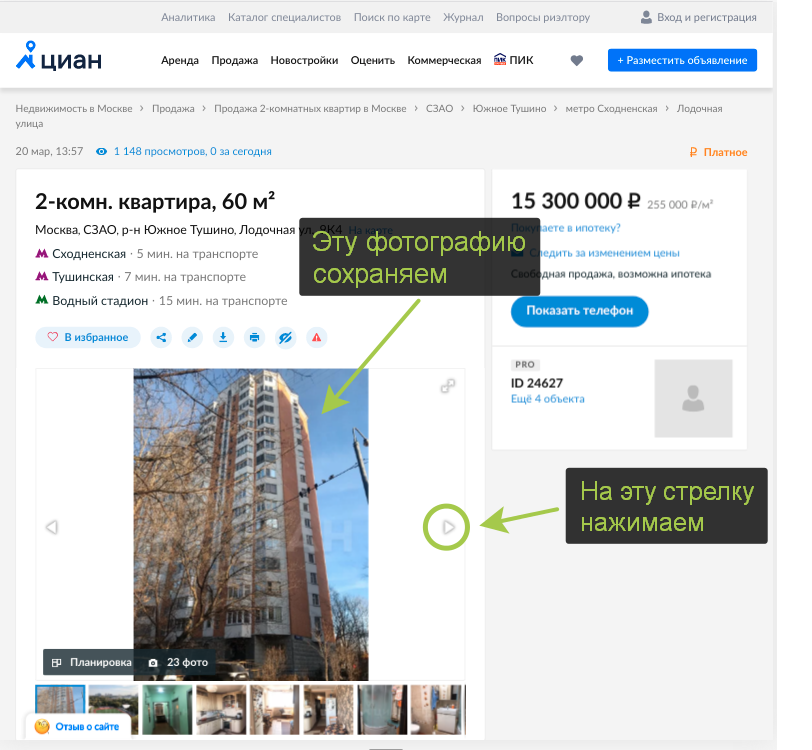
Здравствуйте дорогие хабровчане, в этом небольшом примере я хочу показать как можно распарсить страницу, данные на которую подгружаются с помощью javascript виджетов. Более того, даже если страницу в этом примере просто сохранить, то всё равно не получится спарсить из неё все нужные фотографии из-за этих виджетов. В данном случае я использую для примера сайт cian.ru, у которого есть свой api, который я использовать не буду, вместо этого я буду использовать Selenium. Я не работаю в cian.ru, просто использую этот сайт для примера. Код в парсере простой и расчитан на начинающих.
Небольшое вступление — когда на досуге я рассматривал примеры ремонтов в cian.ru, я подумал, что не плохо было бы сохранить понравившиеся мне фотографии, но вручную сохранять их было бы долго, к тому же это не наш метод, так я и решил написать этот парсер.
Парсер написан на языке python3 из дистрибутива Anaconda, Selenium и chromedriver binary я установил отдельно именно из этих ссылок. (Ну и конечно же в системе должен быть установлен барузер Google Chrome)
Ниже представлен полный код парсера, далее я разберу основные моменты отдельно.
from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.common.exceptions import NoSuchElementException import chromedriver_binary import urllib import time print('start. ') site = "https://www.cian.ru/sale/flat/222059642/" chrome_options = Options() chrome_options.add_argument("--headless") driver = webdriver.Chrome(options=chrome_options) #driver = webdriver.Chrome() driver.get(site) i = 0 while True: try: url = driver.find_element_by_xpath("//div[contains(@class, 'fotorama__active')]/img").get_attribute('src') except NoSuchElementException: break i += 1 print(i, url) driver.find_element_by_xpath("//div[@class='fotorama__arr fotorama__arr--next']").click() name = url.split('/')[-1] urllib.request.urlretrieve(url, name) time.sleep(2) print('done.')Первым делом я загрузил страницу https://www.cian.ru/sale/flat/222059642/ с понравившимися мне фотографиями. Для этого я создал объект driver браузера и передал ему ссылку через метод get . Обратите внимание, что я использую Headless Chrome, т.е. передаю в webdriver.Chrome() параметры опций браузера с аргументом —headless , благодаря этому браузер не будет реально отрисовывать содержимое страницы, если вы захотите посмотреть на отрисовку, то не передавайте аргументы chrome_options и тогода вы сможете увидеть, что происходит на самом деле.
site = "https://www.cian.ru/sale/flat/222059642/" chrome_options = Options() chrome_options.add_argument("--headless") driver = webdriver.Chrome(options=chrome_options) #driver = webdriver.Chrome() driver.get(site)Далее в цикле я начал парсить фотографии, логика парсера работет также, как если бы я сам скачивал их вручную, т.е. сохраняю текущую фотографию и нажимаю на стрелку «next».
Код ниже сохраняет в переменную url ссылку на фотографию, блок try/except отслеживает ошибку NoSuchElementException , эта ошибка возникает, когда все фотографии скачаны и Selenium больше не находит ссылку.
try: url = driver.find_element_by_xpath("//div[contains(@class, 'fotorama__active')]/img").get_attribute('src') except NoSuchElementException: break
Слудующий блок кода буквально кликает по стрелке для перехода к следующей фотографии.
driver.find_element_by_xpath("//div[@class='fotorama__arr fotorama__arr--next']").click()
Далее сохраняем фотографию по ссылке на диск через библиотеку urllib .
name = url.split('/')[-1] urllib.request.urlretrieve(url, name)
И в конце простой но важный код, задержка позволяет полностью подгрузиться странтице после клика по стрелке. (здесь можно сделать код почище организовав задержку средствами Selenium)
time.sleep(2)
Вот такой пример парсера фоторграфий на Selenium, не утверждаю, что это лучший подход, если кто-то знает как сделать лучше напишите свои идеи в комментах.
Как спарсить картинку через java и jsoup?
Помогите пожалуйста, пытаюсь спарсить со страницы картинку, но бросает эксепшин на строке
Document doc = connection.url(«4pda.ru/forum/index.php?»).get();
Что я делаю не так?
mContext = context; LayoutInflater inflater = (LayoutInflater) context.getSystemService(Context.LAYOUT_INFLATER_SERVICE); mView = inflater.inflate(R.layout.login, null); username_edit = (EditText) mView.findViewById(R.id.username_edit); captcha_edit = (EditText) mView.findViewById(R.id.captcha_edit); captcha_image = (ImageView) mView.findViewById(R.id.captcha_image); password_edit = (EditText) mView.findViewById(R.id.password_edit); privacy_checkbox = (CheckBox) mView.findViewById(R.id.privacy_checkbox); String ClassName = "ipbtable"; try < String url = "http://4pda.ru/forum/index.php?act=Login&CODE=01"; Connection connection=Jsoup.connect(url); connection.method(Connection.Method.GET); connection.referrer("http%3A%2F%2F4pda.ru%2Fforum%2Findex.php%3F"); connection.ignoreHttpErrors(true); connection.timeout(1000); connection.data("act", "login"); Connection.Response res = connection.execute(); Document doc = connection.url("http://4pda.ru/forum/index.php?").get(); Elements wrapper = doc.select(ClassName).eq(0); Elements img = wrapper.select("img").eq(0); String imageUrlStr = img.attr("src"); Bitmap mIcon11 = null; URL newUrl = new URL(imageUrlStr); URLConnection urlConn = newUrl.openConnection(); InputStream stream = urlConn.getInputStream(); mIcon11 = BitmapFactory.decodeStream(stream); captcha_image.setImageBitmap(mIcon11); >catch (Exception e)
- Вопрос задан более трёх лет назад
- 2187 просмотров
2 комментария
Оценить 2 комментария